



第801回
光インターコネクトで信号伝送の高速化を狙うインテル Hot Chips 2024で注目を浴びたオモシロCPU
2024年12月09日 12時00分更新
信号速度128Gbpsで16波長多重あたりまで高速化が可能
実際に試作されたチップの写真が下の画像だ。搭載されているCPUの詳細は不明だが、大きさから考えて第4世代Xeon Scalableあたりとほぼ同等の大きさと思われる。

現状はコネクター部がややごついが、例えばリンク4本(光ファイバー32本相当)を束ねて一つのコネクターにまとめても、そう大きくはならないと思われるので、このあたりはなんとでもなるだろう
下の画像はその光信号をスペクトルアナライザで確認したものだが、1310nmを中心に、波長を1nm程度ずらして1307~1315nmの間に8波長を通す格好となっている。
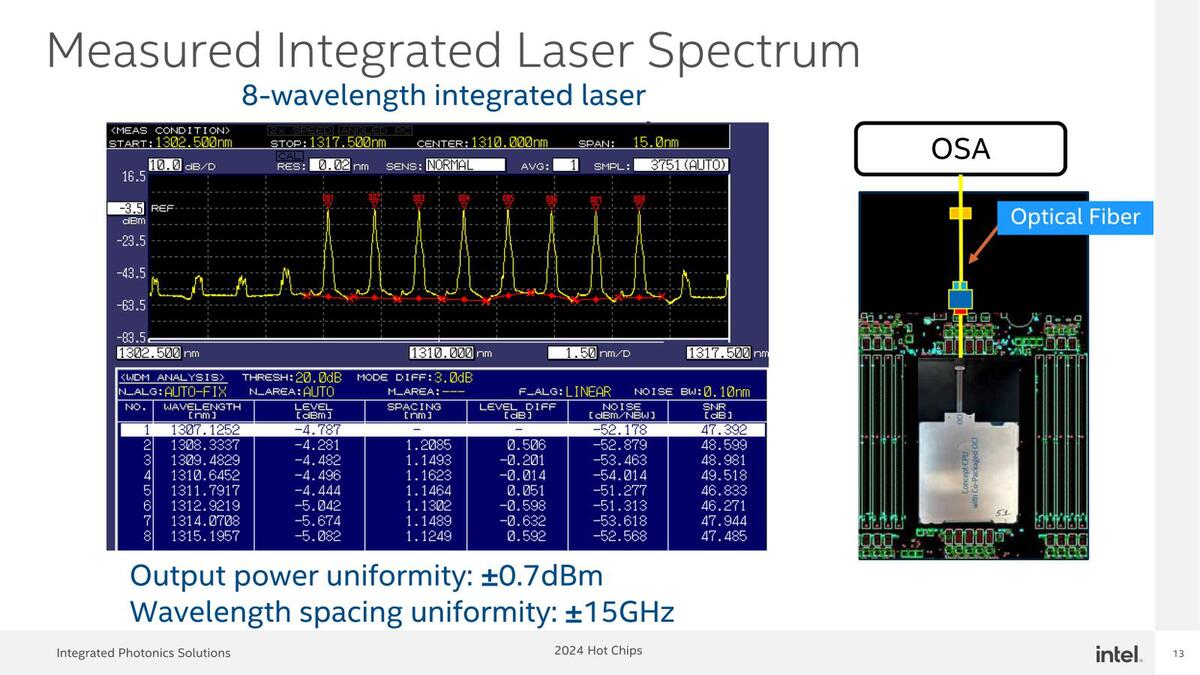
波長で言えば1nm強、周波数で言えば15GHz刻みとなっている
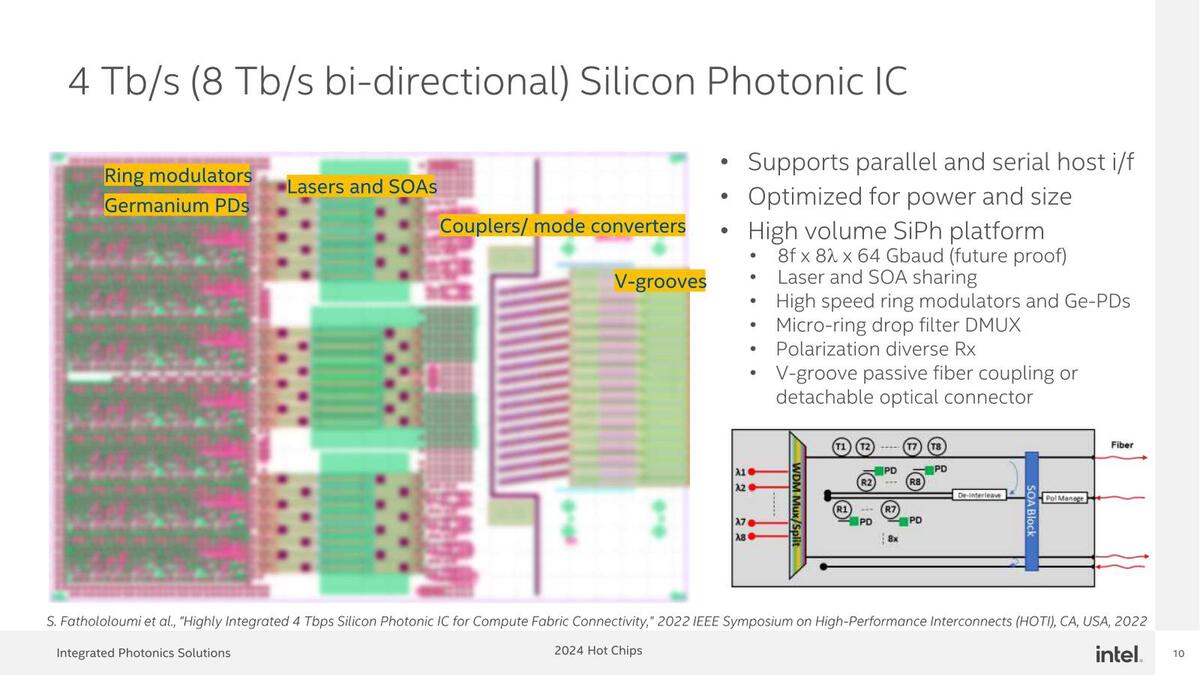
この場合、送信側は波長の異なる8種類の光信号を8つの送信素子を使って生成し、これを一本の光ファイバーにからめて(これを行なうのがMUX:Multiplexer)送り出し、受信側はこれを受け取ったら個々の波長で光信号を分解(これを行なうのがDeMUX:DeMultiplexer)してからそれぞれ異なる受信素子を利用して受け取るわけだ。
ちなみに今回の送受信は、1レーンあたり32Gbpsということになっているが、シリコンフォトニクスの回路そのものは倍の64Gbpsでの送受信が可能になっているという話で、あとは消費電力やI/Fなどの都合がつけば帯域を倍にすることも容易、というのがインテルの説明である。
このあたりはイーサネット向けと技術を共用している部分もあるので、インターコネクト向けは32G→64G→128Gだが、イーサネット向けには現在の112G(56G PAM4)→224G(112G PAM4)を視野に入れているとのこと
またこの先はさらに高速化が可能で、ロードマップ的には信号速度128Gbpsで16波長多重あたりまで視野に入れているという話であった。おもしろいのは、インターコネクト向けにはPAM4を使う予定がなくNRZ(0か1のバイナリーシグナル:PAM4は4値である)なことだ。おそらくだが、PAM4を使うとエラー訂正のために強力なFEC(Forward Error Collection)機構を入れる必要があり、これがレイテンシー増大の大きな要因になる。おそらくはこれを嫌ってのことであろう。
ということでわりと未来は明るい的な説明であったが、現状の問題点はSMF(Single Mode Fiber)を利用していることだろう。光ファイバーにはSMFの他にMMF(Multi-Mode Fiber)やPMF(Polarization Maintaining Fiber)と呼ばれるものが存在する。
SMFとPMFはガラスベース、MMFはプラスチックベースのもので、SMF/PMFの方が信号減衰が少ない一方、曲げにくい(最近はいろいろ進化しているが、MMFにはおよばない)のと高価なのが問題である。
ちなみにSMFとPMFではPMFの方が高価で、3つ上の画像の説明に"no PMF required"とあるのは「PMFのような超高価なファイバーは要らない(けれどMMFよりは高い)」という意味である。
なぜSMFが必要かといえば、減衰に起因する。一つは光信号の出力がそれほど高くできないので、減衰の多いMMFでは信号伝達に支障をきたす可能性があること、それともう一つはDWDMを利用している関係で、中心波長が1310nmになっており、この波長帯でMMFは減衰が多いことが要因であろう。
Light PeakはMMFを利用し、なので波長も850nmというMMFでも損失が少ない領域を使っていた(し、そもそもWDMを利用していなかった)が、今回は高速化のためにWDMを使わざるを得ず、そうなると850nm帯では波長が重なり合い兼ねないので1310nmに移行せざるを得ず、結果としてSMFが必要になるというわけだ。
このあたり、製品に応用するにはまだ一捻り、二捻り必要な気がする。今後このあたりをどう克服していくのか、興味あるところである。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります