



第799回
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす
2024年11月25日 12時00分更新
大規模システムは性能を上げると効率が落ちるが
小規模システムなら性能と効率のどちらも上げられる
TOP500の2024年11月版で10位となったTuolumne、これもローレンス・リバモア国立研究所のシステムである。El Capitanは、実はサイエンス向けというよりも核実験シミュレーション(連載286回で説明した、ASCI/ASCの流れを汲む用途)がメインである。そこで、より小規模なサイエンス向けのシステムとして、El Capitanとは別に提供されるのがTuolumneであり、2021年に初めてその計画が明らかになった。
こちらはRpeakが288.88PFlopsで、El Capitanのほぼ10分の1のサイズである。実際総コア数は116万1216、うちAccelerator/Co-Processorが105万624で、CPUコアは11万592。つまりInstinct MI300Aが4608個、ノード数1152/ブレード数576枚とかなり小規模である。このTuolumneでの効率は72.0%とずっと高くなっているあたりは、小規模なゆえにネットワークのレイテンシーもずっと少ないのが効率の向上につながっていると思われる。
おそらくEl CapitanとTuolumneではバックボーンの規模が違う。ベースとなるのはどちらも681回で紹介しているDragonFlyであるが、下の画像の例では、8ノードからなる小さなクラスター同士を相互接続する、いわば2段構造である。
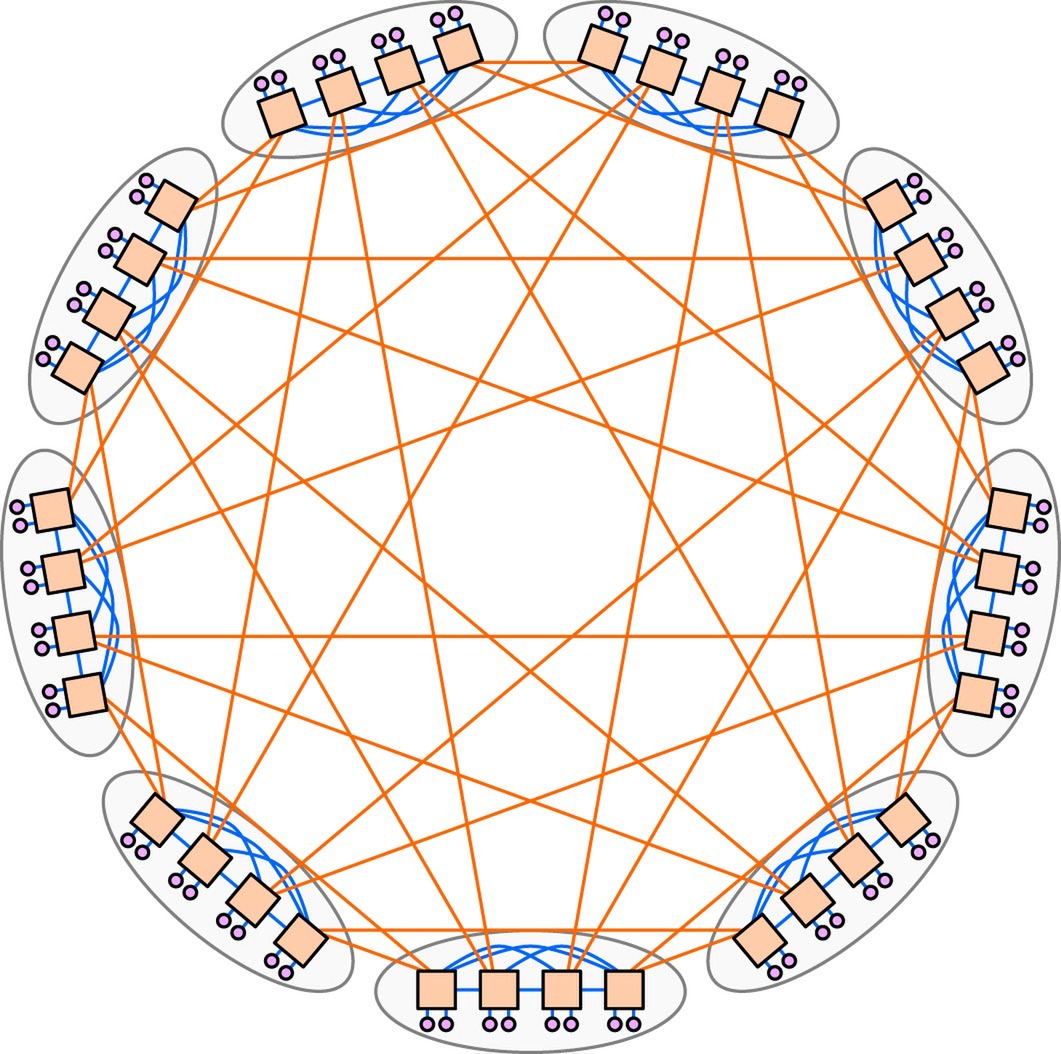
Tuolumneでは、クラスターそのものが16ノード程度になり(これを小クラスターとする)、この小クラスターを8つ相互接続した中クラスターを9つまとめた大クラスターでシステム全体を構成するという、3段構造あたりが考えられる。
そしてEl Capitanではその大クラスターを10個ほど集めて相互接続する巨大クラスター構成あたりになりそうだ。要するに、4段構造になると想定される。この段数の差がレイテンシーの差につながり、効率の低下をもたらすというあたりが正直なところではないかと思う。
性能/消費電力比は58.89GFlops/Wで、今回のGreen 500では18位にランキングされている。とはいえ、Frontierの54.98GFlops/W(ランキング22位)よりは良い結果である。ローレンス・リバモア国立研究所はEl CapitanやTuolumne(12位)以外にrzAdams(10位 )をInstinct MI300Aベースで立ち上げており、他にサンディア国立研究所がEl Dorado(13位)をランクインさせている。
またフランスGENCI-CINESのAdastra 2はやはりInstinct MI300Aベースながら69.10GFlops/Wでランキング3位に輝いている。このAdastra 2、Rmax/Rpeak比は79.9%と極めて効率も高い。ただしInstinct MI300の数は64個。ノードで言えば16である。要するに小規模なシステムであれば、性能効率と消費電力効率のどちらも上げるのは極めて容易という話であって、問題は大規模にスケールさせると途端に悪化することである。
下のグラフは、今年のGreen 500のリストからTop 199を選んで、Rmaxの値とEnergy Efficiencyでプロットしたものである。なぜGreen 500から選んだかというと、今回リストに入った500システムのうち、消費電力を申告しているのは199システムしかなく、それがGreen 500の199位までにランクインしているからである。
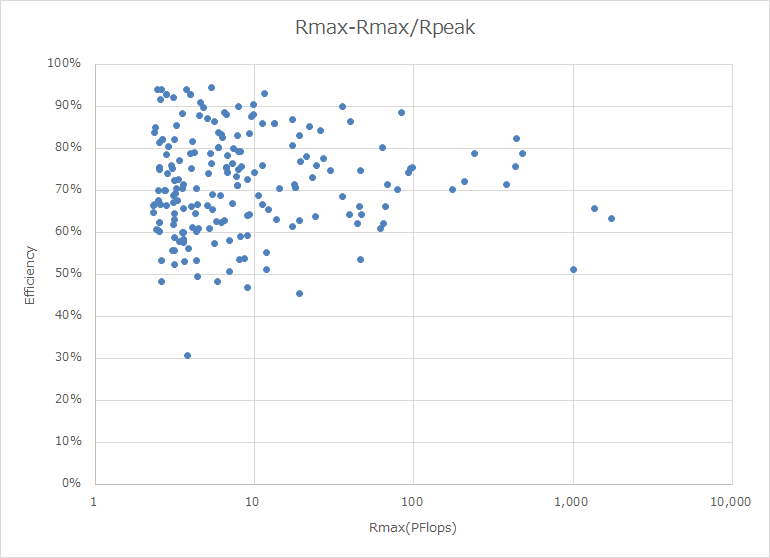
今年のGreen 500のリストからTop 199を選んで、Rmaxの値を点で書き込んだもの
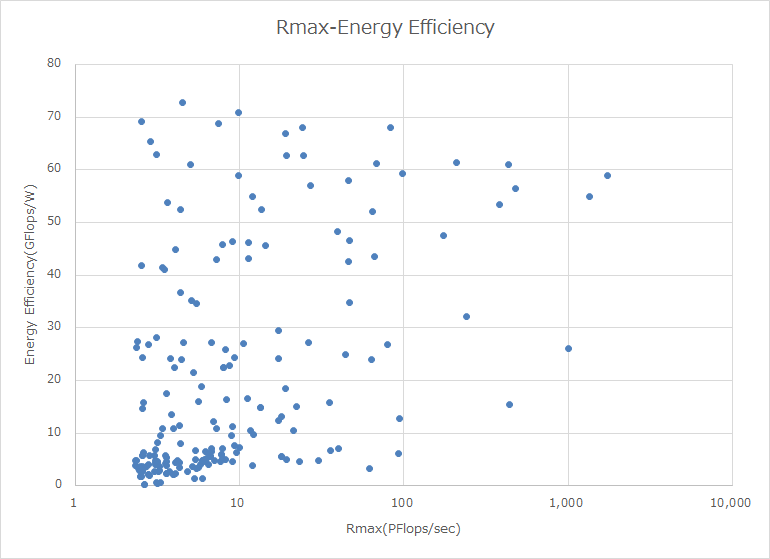
今年のGreen 500のリストからTop 199を選んで、Energy Efficiencyの値を点で書き込んだもの
実際に見てみるとRmaxが1~10PFlops程度のシステムでも大多数は30GFlops/W未満で、そもそも30GFlops/Wを超えるシステムは少ないのだが、60GFlops/Wを超えるような高効率なシステムはRmaxが100PFlops以下に集中しており、これを超えるのは本当にごくわずか、ということだ。
要するに絶対性能を上げると効率はどうしても落ちる。こうしてみると、Auroraですらこの性能で30GFlops/W弱を維持できているのは素晴らしいともいえる。もっと上のEl Capitan/Frontierと比べてしまうと見劣りはするが。
下のグラフは同様に、縦軸を性能効率(Rmax/Rpeak)、横軸をRmaxとしてプロットしたもので、10PFlopsくらいのマシンであれば効率90%以上も期待できるが、100PFlopsでは最大でも80%、1000PFlopsだと70%程度で、これを超えると60%に落ちている。当然と言えば当然の結果ではあるのだが、ピーク性能を求めるとどうしても効率が落ちるのは避けられない、という話が再確認できた格好である。
NVIDIAのBlackwellはHPC向けの性能はあまり期待できないので、あとはAMDがInstinct MI350/400世代のHPC向けでどの程度性能を引き上げられるか、あるいはインテルのFalcon Shoreがどの程度の性能なのか、というあたりが次の話題になりそうだ。
ちなみに今回のSC24で、インテルは恒例だったHPC製品のロードマップ公開を止めた模様だ(まだ原稿執筆時点でSC24は終わっていないので、この後行なわれる可能性はあるが、インテルのウェブサイトを見ている限りなさそうである)。Falcon Shoreの進捗とか知りたかったのだが、残念である。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります