



第797回
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月11日 12時00分更新
今回取り上げるのはFuriosaAIのRNGDである。あまり日本では有名ではないが、韓国のファブレス半導体メーカー、要するにスタートアップ企業である。創業は2017年と比較的最近であるが、すでに第2世代製品であるRNGDを完成させ、HotChipsの会場では動作デモを実施したあたりは、製品の発表をしながらちっとも動作サンプルが展示されていないAIプロセッサーベンチャーが多い中では優秀、というべきだろう。
NVIDIAのT4を上回る性能を発揮する
第1世代AIアクセラレーター「Warboy」
第2世代のRNGDの話をする前に、まずは第1世代の製品であるWarboyについて説明したい。実はWarboyが正確にいつリリースされたのかという日付は不明なのだが、2021年9月24日にそのWarboyを搭載した評価基板上でMLPerf 1.1を実施し、NVIDIAのT4を上回る性能を確認したというリリースを出しているので、おそらく2021年中に最初のサンプルは完成しており、量産開始は2022年あたりのはずだ。

発表当時のWarboyを搭載した評価ボード。社名のロゴが現在のものとやや違っているのがわかる。チップの左のメザニンコネクターはデバッグ用だろうか?
ちなみにそのMLPerfであるが、MLPerf Inference:Edge Benchmarkでv1.1を選択すると出てくるが、実はNVIDIA T4に勝ってるか? というと微妙である。この時NVIDIA T4を利用したのはLenovoで、ThinkSystem SE350(CPUはXeon D-2123IT)にNVIDIA T4ボードを装着してMLPerf 1.1 Inferenceを実行した。一方FuriosaAIはCore i9-11900K搭載のシステムに上の画像のボードを搭載したものらしい。
結果は下表の通り。MLPerf 1.1 Inference:Edgeでは3D-UNet-99.0/3D-UNet-99.9/BERT-99.0/ResNet/RNN-T/SSD-Large/SSD-smallの7種類のネットワークが用意され、それぞれオフライン(バッチサイズを1より大きくできる)とSingle Stream((バッチサイズ=1)の2つの方法で実施する。
| FuriosaAIが公表したベンチマーク結果 | ||||||
|---|---|---|---|---|---|---|
| テスト項目 | テスト方法 | NVIDIA T4 | Warboy | 単位 | ||
| 3D-UNet-99.0 | Offline | 7.18 | samples/s | |||
| Single Stream | 158.33 | ms | ||||
| 3D-UNet-99.9 | Offline | 7.18 | samples/s | |||
| Single Stream | 158.33 | ms | ||||
| BERT-99.0 | Offline | 375.89 | samples/s | |||
| Single Stream | 6.01 | ms | ||||
| ResNet | Offline | 5,808.47 | 2,634.18 | samples/s | ||
| Single Stream | 0.82 | 0.74 | ms | |||
| RNN-T | Offline | 1,343.67 | samples/s | |||
| Single Stream | 73.04 | ms | ||||
| SSD-Large | Offline | 134.51 | 73.85 | samples/s | ||
| Single Stream | 8.30 | 13.62 | ms | |||
| SSD-small | Offline | 7,399.41 | 4,122.14 | samples/s | ||
| Single Stream | 0.47 | 0.42 | ms | |||
WarboyはそもそもResNet/SSD-Large/SSD-smallの3種類の結果しか登録していないのだが、いずれのケースでもオフラインではNVIDIA T4の方が高速である(こちらは複数を同時に処理しているから、1秒当たりの処理数で比較)。一方Single Streamの方は、ResNetがT4が0.82msに対してWarboyが0.74ms、SSD-smallが同じく0.47msに対して0.42msと若干ではあるがT4を上回る性能を出しているのは事実である。
ただSSD-Largeでは8.3ms vs 13.62msであり、どのテストでも満遍なくT4より高速というわけではないし、Single StreamはともかくオフラインではほぼT4の半分程度の性能、というのはやはりそれなりに制約があるのがわかる。とはいえ、創業から4年ほどで動作するシリコンの製造にまで漕ぎつけ、それが一部のテストではNVIDIA T4を上回る性能を発揮するというのはスタートアップ企業にとってはうれしいことであったと思う。
FuriosaAIによれば、最初のシリコンが完成して数週間でMLPerfの締切に間に合わすべくデータを取った関係で、上表のデータはソフトウェアの最適化が最小限でのものだったらしい。翌年MLPerf 2.0では下表のように全項目で若干性能が向上しており、特にSSD-smallのオフラインの性能は倍以上になっている。同じMLPerf 2.0 Inference:Edgeに登録されたNVIDIA A2ベースのシステムよりも性能が高くなった、とアピールしている。
| FuriosaAIが公表したベンチマーク結果 | ||||||
|---|---|---|---|---|---|---|
| テスト項目 | テスト方法 | MLPerf 1.1 | MLPerf 2.0 | 単位 | ||
| ResNet | Offline | 2,634.18 | 2,758.44 | samples/s | ||
| Multi Stream | 3.97 | ms | ||||
| Single Stream | 0.74 | 0.71 | ms | |||
| SSD-Large | Offline | 73.85 | 79.92 | samples/s | ||
| Multi Stream | 107.87 | ms | ||||
| Single Stream | 13.62 | 13.43 | ms | |||
| SSD-small | Offline | 4,122.14 | 8,762.15 | samples/s | ||
| Multi Stream | 2.05 | ms | ||||
| Single Stream | 0.42 | 0.36 | ms | |||
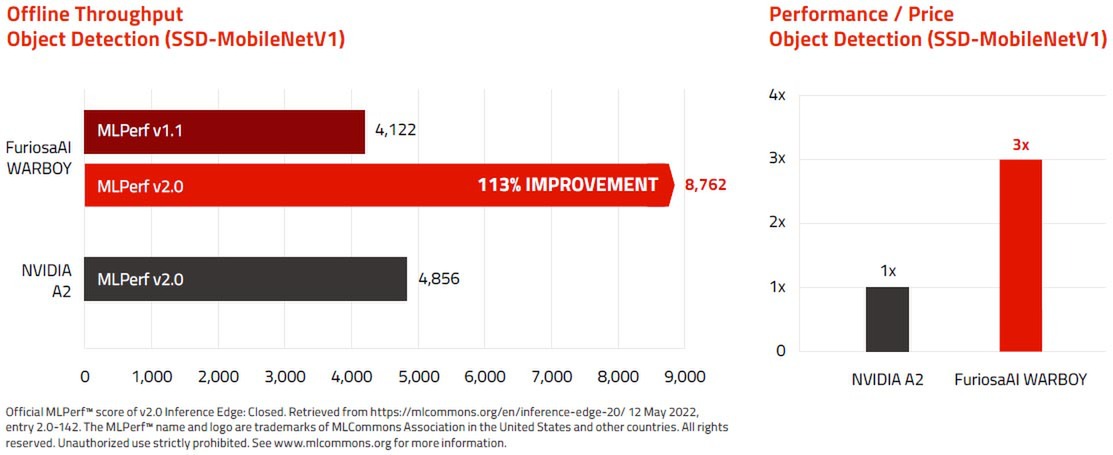
NVIDIA A2の数字は、NVIDIAがSupermicro AS-1114S-WTRTにNVIDIA A2を1枚搭載した構成で取得して登録したものと思われる
ちなみに最終的な製品はPCIeのFHHL(Full-Height/Half-Length)もしくはHHHL(Full-Height/Half-Length)に収まり、処理性能は64TOPS。オンチップSRAMが32MB、オフチップでLPDDR4X-4266を4つ接続し、16GB(技術的には32GBまで可能)のメモリーを利用可能。TDPは40~60W(Configurable)と説明されている。ホストとはPCIe 4.0 x8で接続される格好だ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります