



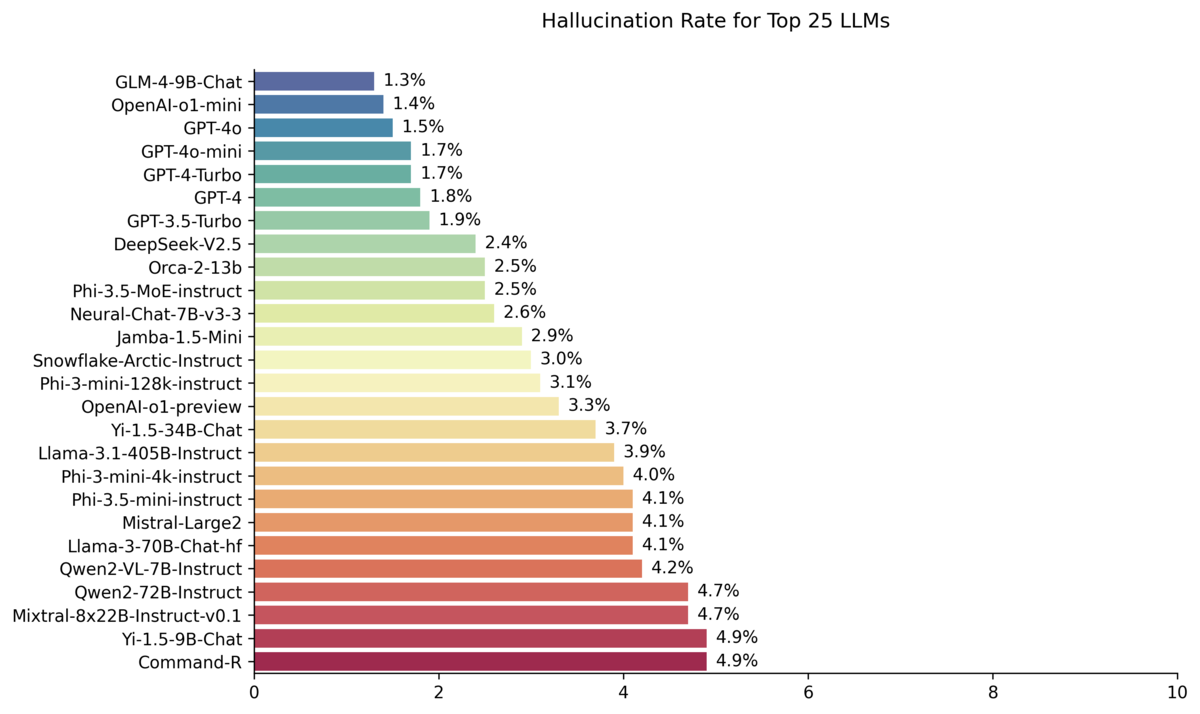
2024年9月13日付けのHallucination Leaderboard
AIがあたかも本当のように事実と異なることを言ってしまうハルシネーション(幻覚)。どのくらい幻覚を見るかを示すハルシネーションレートは、各社がしのぎを削る大規模言語モデル(LLM)の精度の高さを証明する1つの指標となっている。
さて、各LLMのハルシネーションレートを比較すべくAI企業Vectaraが開発したGitHub上のHallucination Leaderboardを見ると、現在(2024年9月13日付け)は中国版ChatGPTとも言われる「智譜AI(Zhipu AI)」のGLM-4-9B-Chatが1.3%でもっともハルシネーションレートが低い。出たばかりのOpenAI o1 miniの1.4%、GPT-4oの1.5%を抑えての1位は正直すごい(冒頭のグラフ参照のこと)。
そういえば先日、コープさっぽろCIOの長谷川秀樹氏が「ハルシネーションがある限り、企業では生成AIは使えないというCIOが多くて驚いた」とOpenAIイベントでの感想をSNSでコメント。確かに、この先も日本企業はハルシネーションレート0%まで求め続けるのだろうか? 長谷川氏も同じ投稿で「人間オペレーションの方が、ハルシネーション多くね?www」とコメントしていたけど、まさにそうだなと。明らかにハルシネーションみたいな発言をする人ってどこにでもいますよね。
文:大谷イビサ
ASCII.jpのクラウド・IT担当で、TECH.ASCII.jpの編集長。「インターネットASCII」や「アスキーNT」「NETWORK magazine」などの編集を担当し、2011年から現職。「ITだってエンタテインメント」をキーワードに、楽しく、ユーザー目線に立った情報発信を心がけている。2017年からは「ASCII TeamLeaders」を立ち上げ、SaaSの活用と働き方の理想像を追い続けている。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります