



Llama-3-ELYZA-JP-70BとLlama-3-ELYZA-JP-8B
今回開発した国産日本語LLMは、高性能モデルである700億パラメータの「Llama-3-ELYZA-JP-70B」と、PCでも利用できる軽量モデルとして80億パラメータの「Llama-3-ELYZA-JP-8B」の2つを用意している。
70BモデルはGPT-4やClaude 3 Sonnetなどの商用グローバルモデルを上回る性能を実現。チャット形式のデモを提供し、多くの人が利用できるようにする。今後は、高性能な国産モデルと位置づけ、企業向けに提供することを予定している。
ベンチーマークの結果は、ELYZA Tasks 100では4.070、Japanese MT-Benchでは平均で9.075のスコアを達成したという。2024年3月に発表したELYZA-japanese-Llama-2-70bでは、ELYZA Tasks 100のスコアが3.485、Japanese MT-Benchの平均スコアは7.500であり、大幅に性能が改善している。また、GTP-4では、ELYZA Tasks 100のスコアが4.030、Japanese MT-Benchでは平均が9.013となっており、それらの数値を上回っている。
「Japanese MT-Benchでは、8つのタスクで評価しているが、数学ではやや弱い部分がある。だが、執筆やロールプレイ、抽出、推論、人文科学の知能、科学技術の知能、コーディングでは高い性能を達成している。複雑なプロンプトに従い、抽出や要約を行い、JSONで出力することもできる」と述べた。
一方、軽量モデルとなる8B(80億パラメータ)モデルでは、ELYZA Tasks 100では3.655、Japanese MT-Benchでは平均で7.775のスコアとなっており、3月発表の700億パラメータのELYZA-japanese-Llama-2-70bの性能も上回るという大幅な進化を遂げている。また、GPT-3.5 turboでは、ELYZA Tasks 100が3.475、Japanese MT-Benchの平均スコアが8.538となっており、同等水準の実績になっている点も見逃せない。
「オープンモデルのなかでは最高水準の性能を達成しており、数100億パラメータのオープンモデルと比較しても遜色がない日本語性能を持った軽量なモデルであり、一般的なPCでも動作させることができる。一般公開を行う予定であり、LLAMA 3 COMMUNITY LICENCEに準拠し、Acceptable Use Policyに従えば、研究利用のほか、商業目的での利用も可能になる。PCやエッジデバイスでも利用してもらい、自分たちにフィット感がある形で利用してもらいたい」とした。
LLM開発は日本においても活発化している
説明会でELYZAの曽根岡CEOは、日本においても、LLM開発が活発化している現状について説明した。
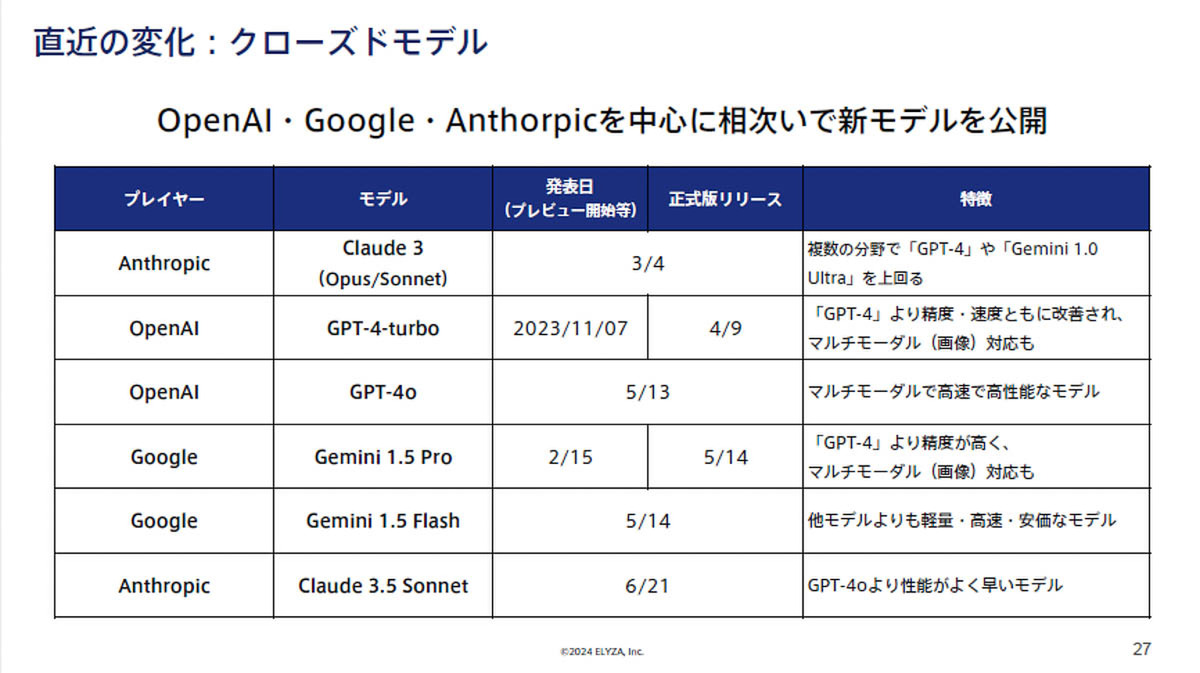
「米国企業を筆頭に、世界各国で様々なプレイヤーがLLM開発を進めているが、日本でも大手ITベンダーを中心に独自モデルを開発しており、NECやNTTでは、サービス提供も始まっている。さらに、研究機関や大学、AIスタートアップなども、LLM開発を推し進めており、国立情報学研究所や東京大学 松尾・岩澤研究所、sakana.ai、rinna、Preferred Elements、Turingをはじめ、研究成果としては50以上のモデルが公開されている。加えて、2023年から、日本の政府がLLM開発に対して予算をつけ、支援を推し進めており、大規模言語モデル構築支援プログラムやGENIACプロジェクトがある」と、LLMに関するこれまでの経緯に触れる一方で、「2023年末時点では、ChatGPTなどのグローバルモデルは、3歩ぐらい先を行っており、国内モデルの性能は大きく差をつけられていた。2024年3月以降は、さらに状況が変化し、OpenAIのGPT-4oや、GoogleのGemini 1.5 Pro、AnthorpicのClaude 3.5 Sonnetなど、相次いで新たなモデルが公開されたほか、クローズドモデルの商用ラインに匹敵するオープンモデルとして、Mistral AIのMixtral 8x22b、MetaのLlama 3、AlibabaのQwen2が登場し、日本語性能でも、この4カ月でトップラインが次々と更新された。だが、そうしたなかでも、今回発表した日本語LLMは、高い性能を発揮することができている」と位置づけた。

週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります