



第779回
Lunar LakeではEコアの「Skymont」でもAI処理を実行するようになった インテル CPUロードマップ
2024年07月08日 12時00分更新
フロントエンドに合わせてバックエンドも強化
FPU/VectorもLoad/Storeユニットも性能が向上
さて、フロントエンドをこれだけ強化した以上、バックエンドも相応に強化する必要がある。Allocationは6-wideから8-wideに、Retirementも8→16に強化された。

例えばPort 01/02はALU/SHIFT/MUL/DIVが共用なのは変わらなかったりするあたり、どこまで依存度が下げられたのかはよくわからない
Dependency breakingというのは、後述するように発行ポートを大幅に増やしたことで、発行ポートの取り合いが大幅に減ることが期待できることを指しているものと思われる。そして発行ポートを増やすというのは扱うべき命令の数も増えるということで、それに合わせてバッファ類も大幅に増量された。

ROB(実行が終わった命令の格納場所)も256→416と大幅に増強され、また物理レジスターファイルも大型化、Load/Storeバッファも拡大、とあってなんかもうAtom系列とは思えない重厚さに
そして実行ユニットだが、まずALU系は、なんとInteger ALUが6→8、分岐も2→3と大幅に強化。AGU(アドレス生成ユニット)もLoad×3、Store×4になっており、Load/Storeがそれぞれ2のCremont世代から倍増とは言わないものの大幅に強化されている。それはIPCも向上するはずである。
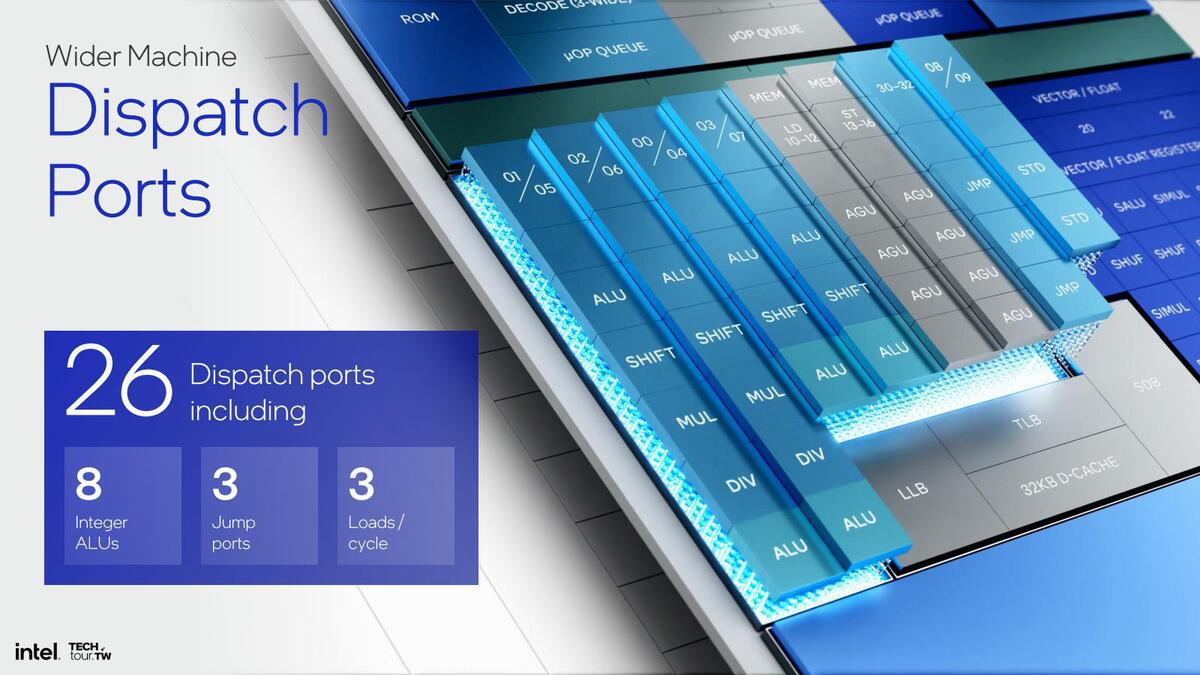
ALUの数だけで言えば、すでにLion Coveを超えている
同様にFPU/Vectorも大幅に強化されている。Cremont世代ではAVX128命令が2命令/サイクル、あるいはAVX256命令が1命令/サイクルで実行できる構成になっていたが、Skymontはこれが倍増しており、AVX128で4命令/サイクル、AVX256でも2命令/サイクルが可能になった。
これはおそらくVNNI関連命令のスループット向上がメインと考えられる。またFPU周りでもレイテンシーの削減などが行なわれ、全体として結構なFPU/Vector性能の向上が実現したものと思われる。
処理性能が向上したら、それに合わせてLoad/Storeユニットも強化しないと、処理が終わっても結果がメモリーに書き戻せないことになる。

L2 TLBの4192もかなりのサイズである。というか、もうこれは完全にサーバー向けCPUのスペックになっている気がする
先程も触れたが、Load AGUが2→3、Store AGUが2→4に強化されている。このStore AGUの強化はFPU/Vectorのスループットが実質2倍になった以上、結果の書き戻しも2倍になるために必要な対策である。そしてこのStore AGUの倍増に合わせてか、2次のBandwidthも128Bytes/サイクルに倍増されており、かなり足回りも頑丈になった格好だ。

L1 to L1は、同じ2次キャッシュを共有するほかのコアとのデータを交換する際の話である。ただ、どの程度高速化されたのかは不明である
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります