



3nmプロセスで製造されている
Turinこと第5世代EPYC
KTU氏のレポートから落ちていた話題が、Turinというコード名で知られていた第5世代EPYCである。実はこのTurinは3nmプロセスで製造されていることが基調講演で説明されている。コア数は実に192で、これを12個のCCDでまかなっている。つまり1 CCDあたりのコア数は16に増強されている格好で、これはBergamoことZen 4cベースのEPYCと同じ量になる。

Turinこと第5世代EPYCは今年後半に投入、ということでまだ話題に上げるには早いという話もあるが、今年第2四半期の決算発表の際に、すでに特定顧客へサンプルが出荷されていることを認めている
AMDが公開したCGや実際のサンプルを見ると、明らかにCCDが横長であり、冒頭のRyzen 9 9950Xの写真と異なっている。

第5世代EPYC。なんとなくIODも共通に見えなくもないが、この世代でAMDもMRDIMMをサポートする気がするので、ひょっとするとIODは刷新されている可能性がある

第5世代EPYCの現物。CCDの切れ目がきちんとわかる。こうしてみると、Ryzen 9000のCCDに比べて横の長さが倍くらいありそう。その一方、高さは若干減っている感じもする
そこでMcAfee氏に「Zen 1からZen 4までRyzenとEPYCは同じCPUダイを利用する戦略だったが、Zen 5世代ではこの戦略を変更したのか?」と尋ねた返事が趣深かった。曰く「その認識は正しくない。Zen 4世代でもGenoaとBergamoは異なるダイを利用していた。つまり高密度向けのダイはコンシューマー向け(=Ryzen)とは必ずしも共有しない」だそうである。
氏が言外に述べているのは、基調講演で示されたTurinというのはZen 4ベースのEPYCであるGenoaの後継製品ではなく、Zen 4cベースのEPYCであるBergamoの後継であるというわけだ。
逆に言えば、Genoaの後継として、Zen 5コア(つまりRyzen 9000シリーズと同じCCD)を利用したEPYCが別に投入される可能性がある、という話である。こちらの方は、それが実現するとするとCCDは同じ4nm世代での投入ということになるだろう。少なくともこの世代ではメインストリームはまだ4nm止まりで、RyzenおよびEPYCが3nmに移行するのは2025年に入ってから、ということになるのかもしれない。
性能/消費電力比や性能/エリアサイズ比に向けて最適化した
Ryzen AI 300
Ryzen AI 300については大きな追加情報はないが、下のスライドで出てきたBlock FP16の正体が判明したのでこれだけ追記しておきたい。
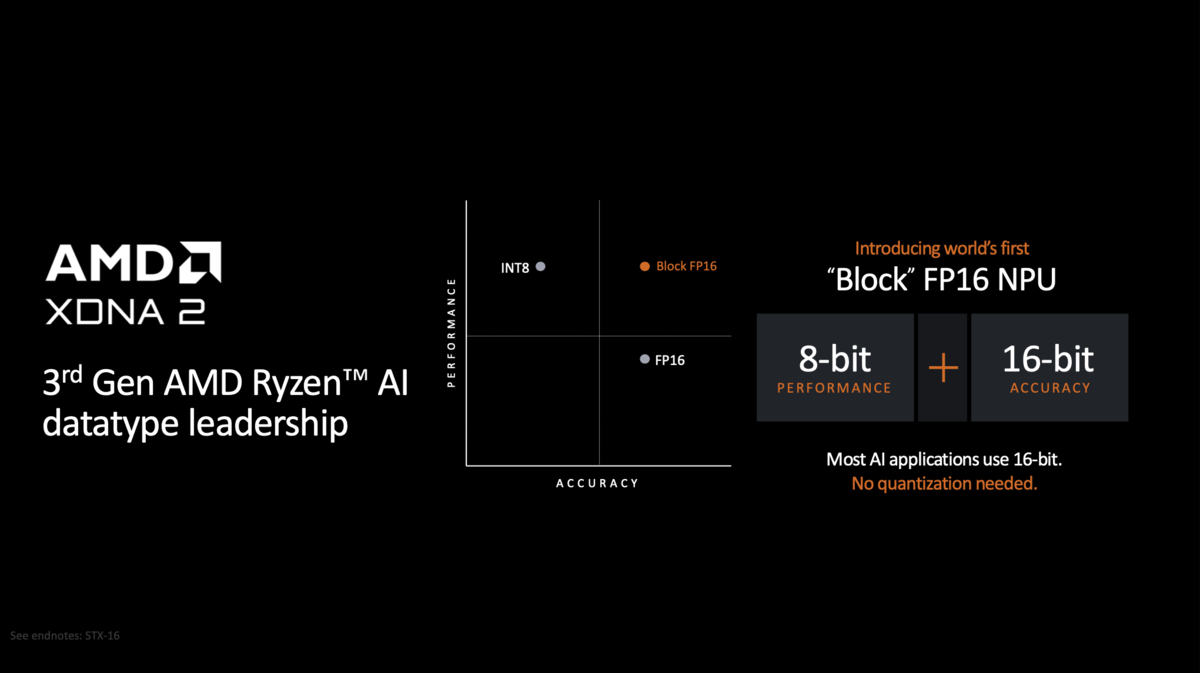
COMPUTEX TAIPEI 2024で発表されたRyzen AI 300のスライド
Jack Ni氏(Sr. Director, AI Product Management, Making AI pervasive across AMD platforms)にBlock FP16の正体を確認したところ、「これはもともとOCPが定めたもので、AMD独自ではない。ただしシリコンに実装したのはRyzen AIが最初だ」という返事が返ってきた。
その中身であるが、"OCP Microscaling Formats (MX) Specification Version 1.0"に定められたMXFP8がその実体のようだ。これは仮数部5bit+指数部2bitないし仮数部4bit+指数部3bit(あと符号が1bit)の構成で、要するにFP8のことである。
なるほどこれならFP16の倍の処理性能が期待でき、そのわりに(推論なら)精度を落とさないで済む。実際にRyzen AI Engineを使って生成AIで画像生成をした結果が下の画像で、確かにBlock FP16はFP16と同等の精度を期待できることが示されている。

Ryzen AI Engineを使って画像生成をした結果。INT8の結果は、よく見るとケーキっぽい気もするのだが、上に謎の人形が載ってたりして"A beautiful dessert"とは言いにくい
またRyzen AI 300に搭載されるRDNA 3.5のGPUについて「詳細は7月のTech Dayまで明かされないと思うので、簡単にRDNA 3との違いをまとめて欲しい」とMcAfee氏に尋ねたところ、「基本的には同じだが、RDNA 3.5は組み込み向けに特化しており、RDNA 3ほどのスケーラビリティはない。また性能/消費電力比や性能/エリアサイズ比に向けて最適化した」(=絶対性能は必ずしも追及する方向になっていない)とのことであった。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります