



4096 OAMがGaudi 3の最大構成に近い
話を戻すと、イーサネットを利用して大規模システムを構築する場合の構成例も示された。
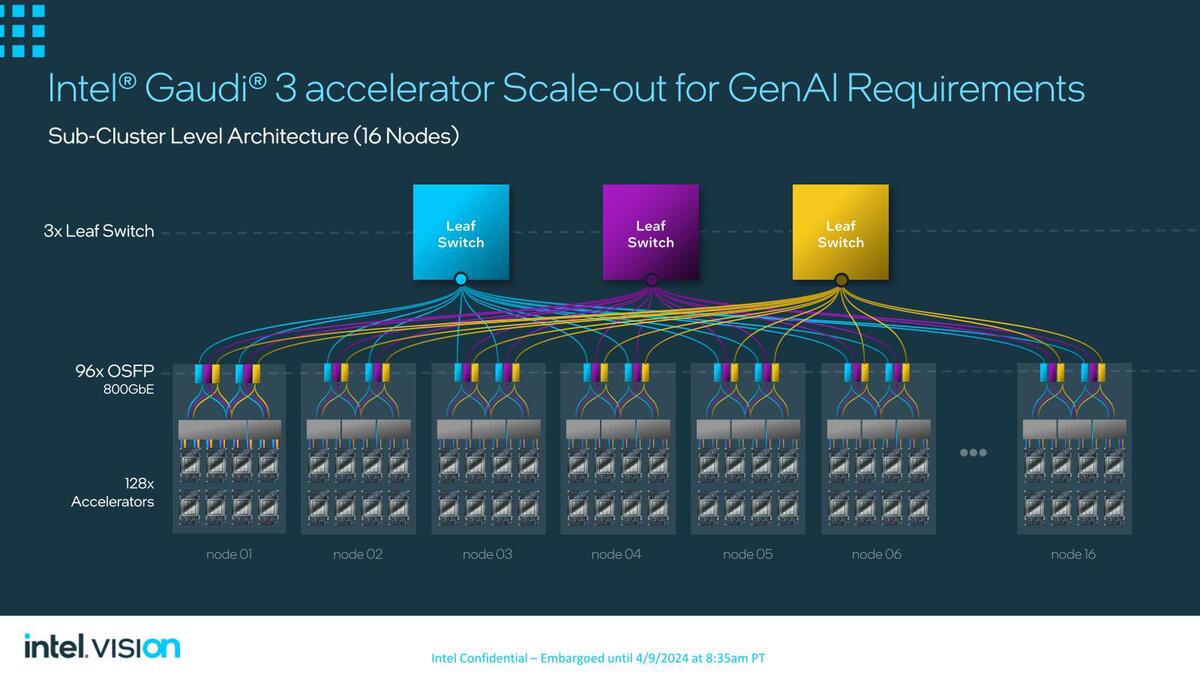
HLB-325を16枚(Gaudi 3 OAMを128枚)が1つのサブクラスターという扱いになる。リーフスイッチはToR(Top of Rack)に収めるのは収容量的に難しいかもしれない

4枚のHLB-325で1ラックが構成される。ということは、HLB-325を格納するシャーシは6Uでも足りず、8Uかそのくらいの高さになるのかもしれない。7200Wを空冷でなんとかするつもりなら、そのくらいの高さのシャーシが必要になるだろう
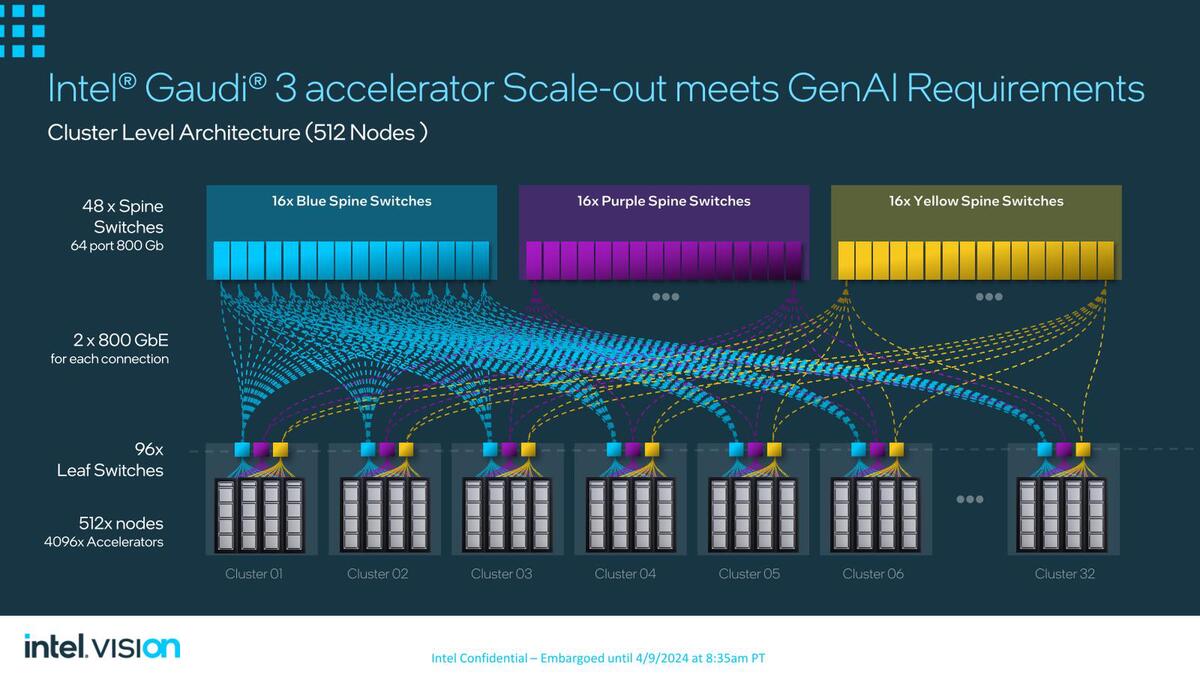
サブクラスター同士をスパインスイッチで接続することで、最大32クラスターを構成したケース。ただここまでくると、800GbE×2でも帯域が足りるのか疑問だ
おそらくはこの直上の画像にある512ノードが現実的には上限に近く、これ以上になるとスパインの上にもう1つコアスイッチを入れないと収まらないようにも思える。さすがにそうなるとレイテンシーが無視できないところであって、4096 OAMがGaudi 3の最大構成に近いと考えて良さそうだ。
メモリー容量が最大のネック
さて、ここからは性能の話。Gaudi 3はNVIDIAのH100/H200をターゲットとしており、性能もH100/H200との比較という格好になる。まずH100とのトレーニングの性能比較では、1.4~1.7倍高速となっている。平均1.5倍といったところか。

トレーニングの性能比較。テストによってOAMの数が異なるので注意

こちらがもう少し詳細な数字。LLAMA2では8や16個のOAMで済むが、さすがにGPT-3のトレーニングでは最大8192になる。あとH100は実測値だが、Gaudi 3は推定値なことにも注意
これが推論におけるH200との比較になると、だいぶ旗色が悪くなる。H100はHBMが80GBだったので、トータルで128GBを実装するGaudi 3にアドバンテージがあるが、141GBを搭載するH200には、メモリー量で押し負けるといったあたりだろうか?
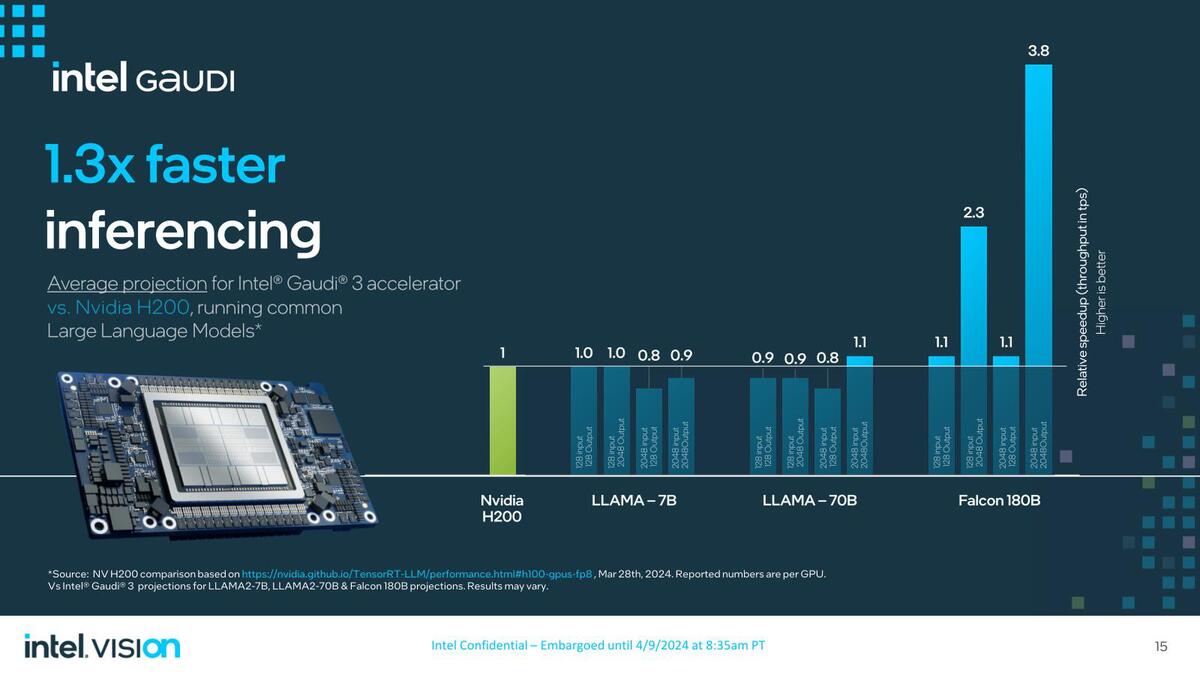
LLAMAだと良くてタイ、70Bだと明らかにメモリー不足である。Falcon 180BだともうH200でもメモリー不足になるので、そうなると地力の性能がでるということだろう。しかしこの結果で平均1.3倍高速というのは無理がある

見ると全般的にGaudi 3の方がバッチサイズを大きめに取っており、あるいはFalcon-180Bで性能が良いのもこれが理由かもしれない
実際H100との推論での比較では、だいぶいい勝負になっているあたりは、やはりメモリー容量が最大のネックということだろう。
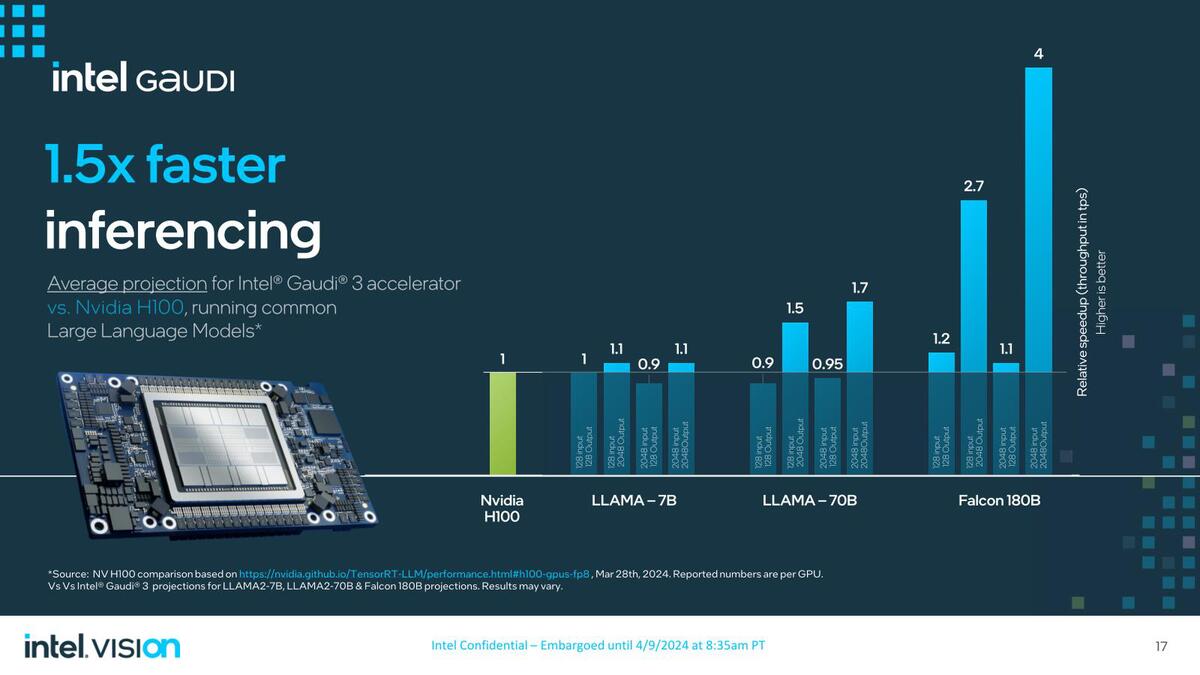
それでもLLAMA-70Bでだいぶ性能が改善しているから、1.2倍くらいとしてもいいようには思うが、1.5倍はないだろう(Falcon-180Bの数字は入れない方が妥当な気がする)

ちなみにFalcon-180Bの数字を入れない場合のAverage Speed upは14%ほど。これが実情に近い気がする
もう1つGaudi 3の特徴としては電力効率の良さをアピールしたいようだが、結果を見ると「確かに高効率なものもあるが、そうでないケースも多い」という感じで、もうなにをどう実行するかで変わってくる感じで、そのあたりの見極めが大変そうである。
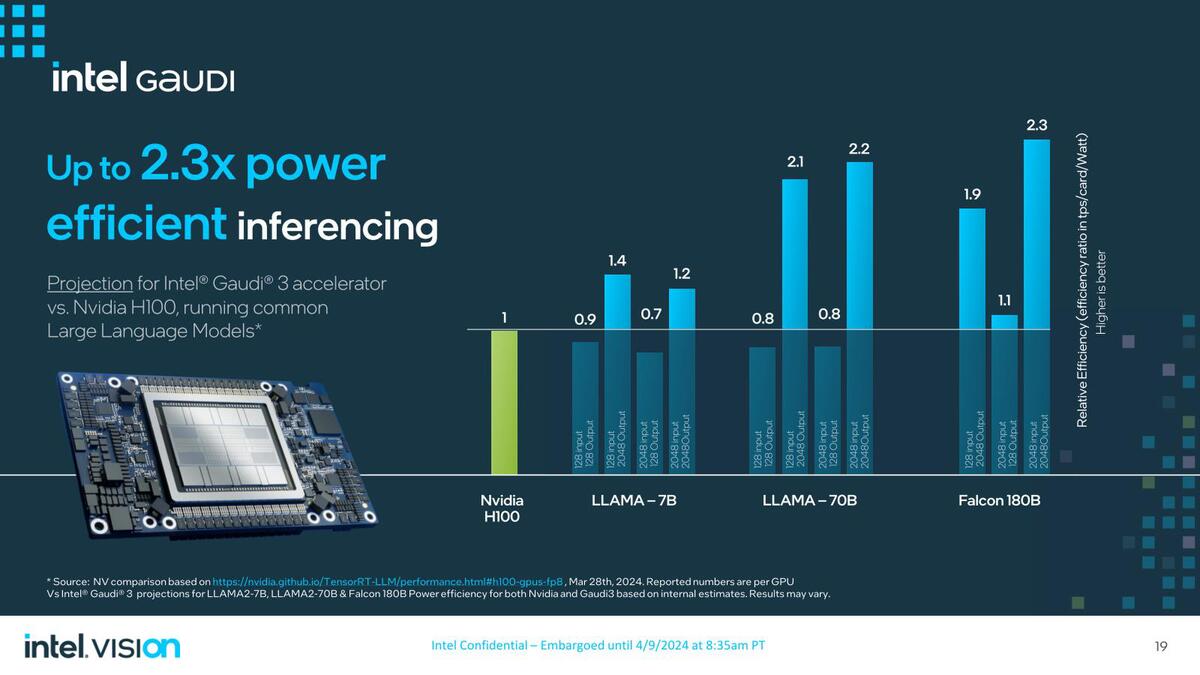
アウトプットサイズが大きい場合には効率が良いのだが、小さいとむしろH100の方が効率が良い結果になっている
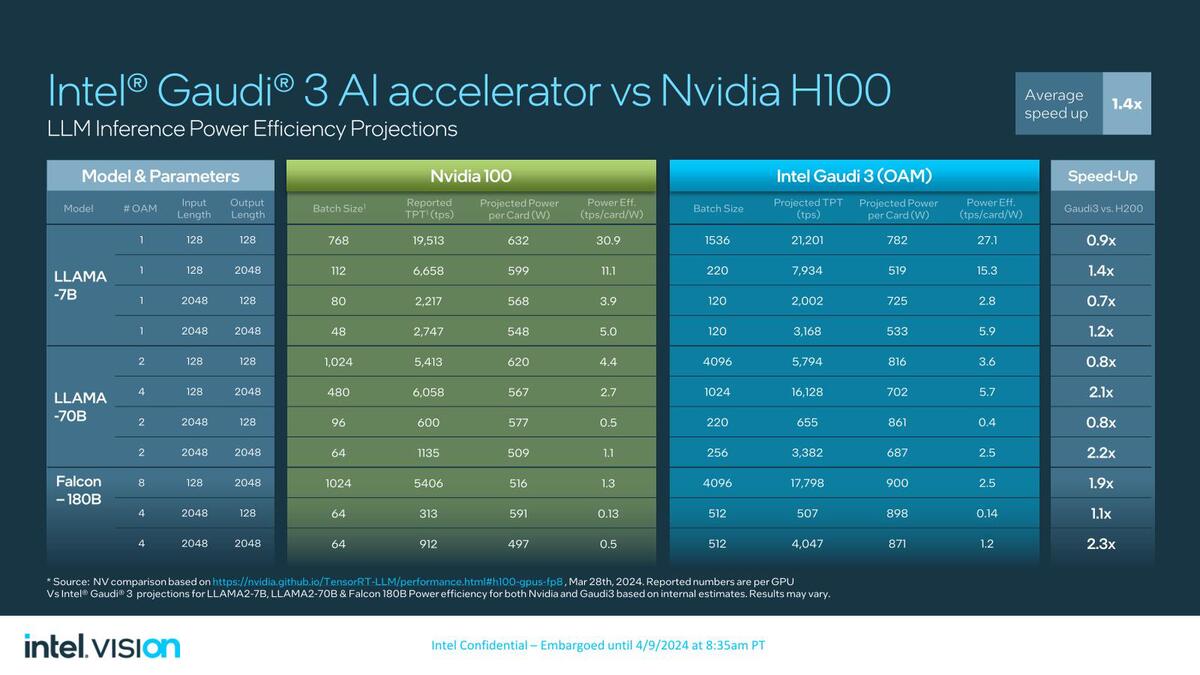
消費電力の絶対値そのものはGaudi 3の方が大きいので、効率はともかく絶対的な消費電力(電力コスト)を抑えるという観点からするとやや使いにくい感じもある
Gaudi 3の後継はFalcon Shores
最後に今後のロードマップについて。Gaudi 3の後継としてGaudi 4的なものは特に考慮されていないようで、次はFalcon Shoresになることが改めて明らかにされた。
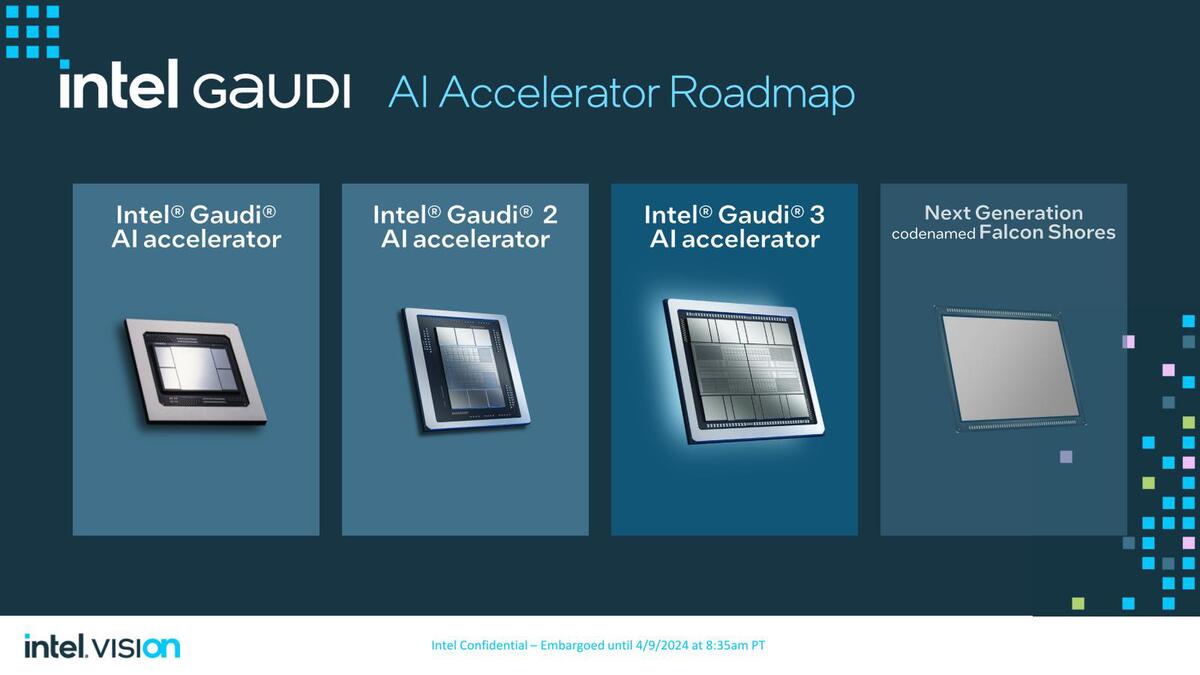
時期的に言えば、B100対抗という形の実装になるのだろうが、その頃にはNVIDIAはX100を、AMDはInstinct MI350あるいはMI400をリリースする頃であり、これらと戦えるのか少し疑問である。そろそろAMD/NVIDIAの最新製品をキャッチアップできないとまずいだろう
Falcon Shoresは連載710回で説明したが、Ponte Vecchioの後継となるAPUである。要するにx86コアとXeベースのGPUから構成され、しかもユニファイド・メモリーが実装される構成である。
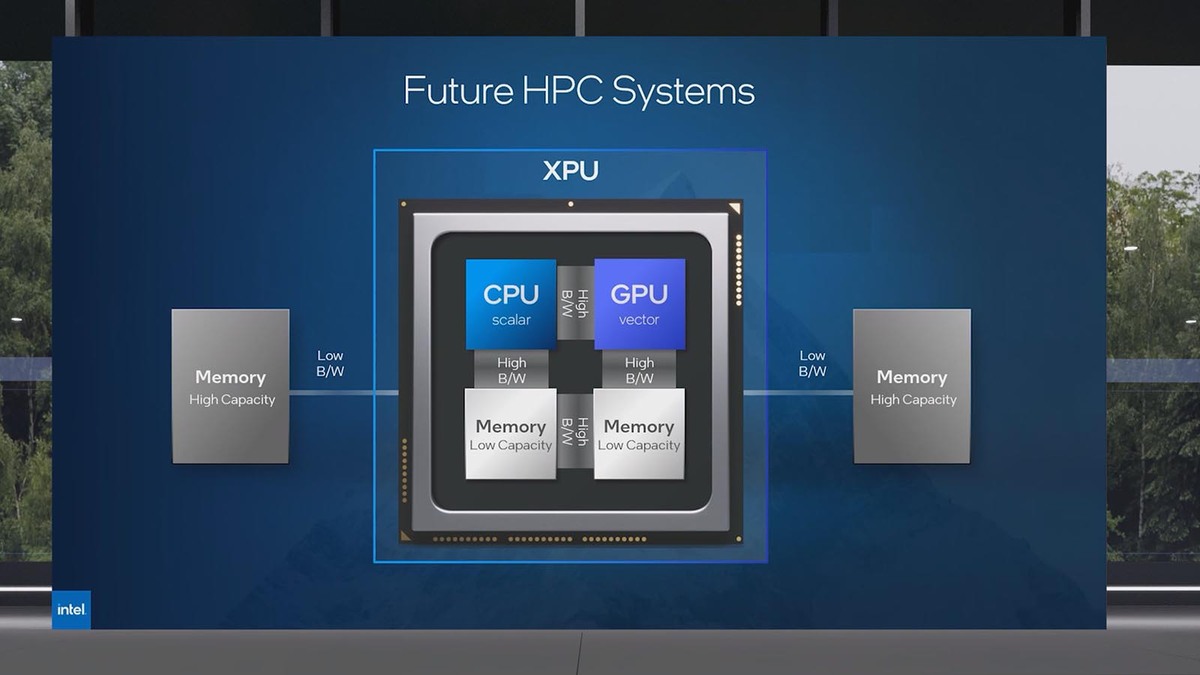
Falcon Shoresの概念図
XeコアベースのGPUと発表されていることから、GaudiのTPCやMMEが実装されるかどうかはかなり怪しい(普通に考えると実装されない)ことになる。もともとHabana Labsの製品はインテルのoneAPIとソフトウェアの互換性がなく、独自のSynapseAI SDKを利用してアプリケーションを構築することになっており、これはGaudi 3でも同じである。
インテルとしてはGaudiをoneAPIに統合するより、Gaudiのアーキテクチャーを廃してXeベースでAIを処理する方向に舵を切った、と考えるのだが妥当だろう。要するにGaudiは、あくまでXeベースのAIトレーニング向け製品が出るまでのピンチヒッターという役割だったことが、今回の発表で図らずしも明らかになった格好である。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります