



前回に引き続きIntel Vision 2024の話題であるが、今回のお題はGaudi 3である。Gaudi 3は昨年12月のAI Everywhereイベントにおける基調講演の最後にGelsinger CEOによるチラ見せこそあったものの、詳細は不明なままだった。

Gelsinger CEOによるGaudi 3のチラ見せ
Gaudi 3はGaudi 2比で2~4倍の性能だが
ダイあたりの性能はそれほど伸びていない
今回Gaudi 3に関してホワイトペーパーまで含めて広範な情報が公開されたので、これをまとめて説明しよう。

Gaudi 3のOAM(OCP Accelerator Module)。2つのダイにそれぞれ4つのHBMが接続され、ダイ同士も接続されている構図がわかる。電源レギュレーターとパスコンの数がエグい
まず基本的な情報から。Gaudi 3には64個のTensor Coreと8つのMME(Matrix Math Engine)、96MBの2次キャッシュと128GBのHBM、24×200GbEとPCIe Gen5 x16が搭載される。

これは2ダイでの合計の数値と思われる
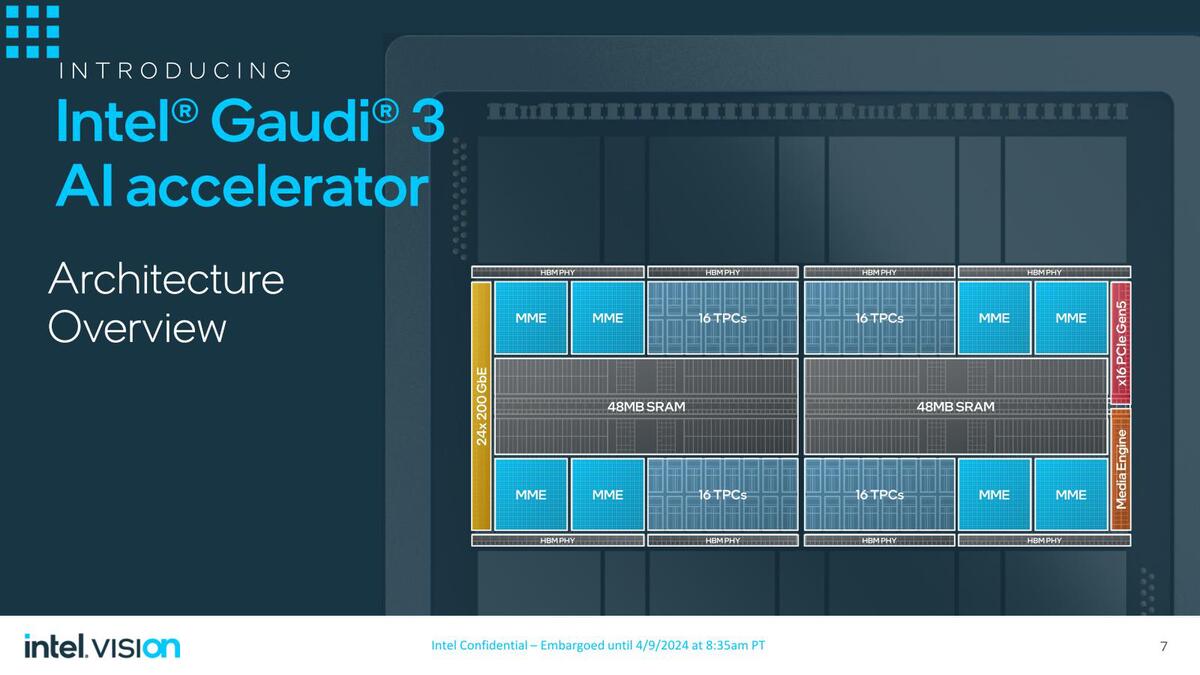
ダイの内訳。これだと2種類のダイがあるように見えるが、実際には下の画像のように、両方のダイの端に12×200GbEとMedia Engine、PCIe I/Fが搭載されている。気になるのは2つのダイ同士を接続するPHYがないことで、実は2つのダイはPCIe経由で接続されているのか? と思ったのだが、下の画像を見る限りにそれも違うようで、どこかに隠れている模様
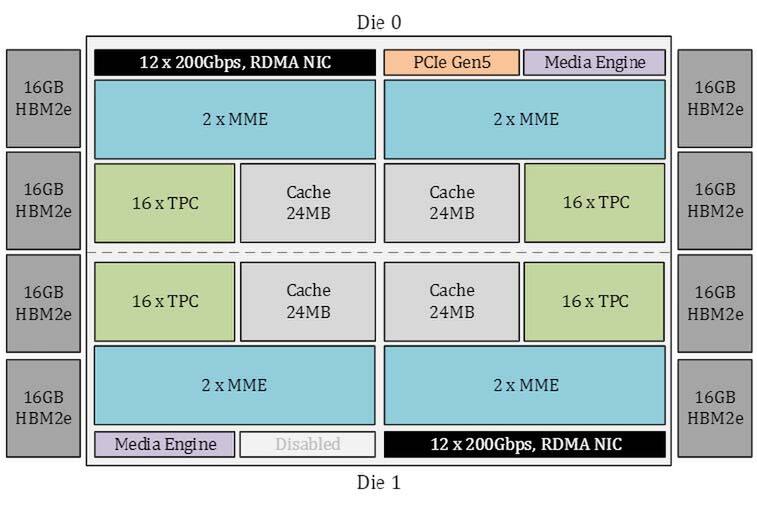
てっきり両方のダイから出たPCIe Gen 5 x16を、カードに載ったPCIeスイッチ経由で接続してホストにもPCIe Gen5 x16で接続しているのかと思った(記事冒頭の画像左上のチップがいかにもそれっぽい)のだが、違うようだ。SRAM同士を相互接続しているのだろうか?
Gaudi 2の概略は連載686回で説明したが、そのGaudi 2とGaudi 3の比較をホワイトペーパーから抜き出したのが下表である。
| Gaudi 2とGaudi 3の比較 | ||||||
|---|---|---|---|---|---|---|
| Gaudi 2 | Gaudi 3 | Gaudi 3(1 Die) | ||||
| BF16 MME TFLOPs | 432 | 1835 | 917.5 | |||
| FP8 MME TFLOPs | 865 | 1835 | 917.5 | |||
| BF16 Vector TFLOPs | 11 | 28.7 | 14.35 | |||
| MME Units | 2 | 8 | 4 | |||
| TPC Units | 24 | 64 | 32 | |||
| HBM Capacity | 96GB | 128GB | 64GB | |||
| HBM Bandwidth | 2.46TB/s | 3.7TB/s | 1.85TB/sec | |||
| On-die SRAM Capacity | 48MB | 96MB | 48MB | |||
| On-die SRAM Bandwidth | 6.4TB/s | 12.8TB/s | 6.4TB/s | |||
| Networking | 100GbE×24 | 200GbE×24 | 200GbE×12 | |||
| Host Interface | PCIe Gen4x16 | PCIe Gen5x16 | PCIe Gen5x16 | |||
| Media | 8 Decoders | 14 Decoders | 7 Decoders | |||
| Process | TSMC N7 | TSMC N5 | TSMC N5 | |||
ここでGaudi 3(1 Die)は筆者が作成したものだ。Gaudi 3はGaudi 2比で2~4倍の性能としているわけだが、ダイあたりで言うと実はそれほど性能は伸びていない。まずMMEの性能で言えば、MMEの数そのものは倍増しており、BF16では性能も倍増しているのだが、FP8で言えば微増(6%程度の向上)に留まっている。

確かにこういう表記にすると、大幅に性能が伸びているように見える
Gaudi 2ではFP8の性能がBF16の倍になっているのに、Gaudi 3ではFP8とBF16の性能が同じ、というのは要するに16bit幅のエンジンを8bit×2に分割する機能をGaudi 3では省き、この結果FP8であってもBF16をそのまま使う形になってのことと思われる。
TPCの数は33%増えているのに、性能で言えば6%しか上がっていないというのは、性能消費電力比を改善するために、動作周波数を引き下げたのではないかと考えられる。動作周波数そのものは示されていないが、Gaudi 2のOAMのTDPが600Wに対し、Gaudi 3では900W。つまりダイ1つあたり450Wになっている。
もちろんプロセスも微細化しているし、HBMもダイあたり6スタック→4スタックに減少しているとはいえ、これだけで150Wも減ったりはしない。おそらくは相当動作周波数を引き下げたものと考えられる。
もう1つのポイントはHBMである。Gaudi 2では1.6GHz駆動のHBM2×6なのに対し、Gaudi 3では1.8GHz駆動のHBM2e×8という構成になっている。AMDはInstinct MI300でHBM3を、NVIDIAはB100/B200でHBM3eを利用していることを考えると、なぜHBM3を選ばなかったのか? という疑問が当然湧く。
これに関して、The RegisterのシステムエディターであるTobias Mann氏のポストによれば、「Gaudi 3の設計に当たっては、実際に動作するシリコンが存在するIPのみを使うというポリシーを貫いており、この結果設計段階で利用可能なHBM3のIPが存在しなかった」のが理由だとしている。
Official comment from Habana:
— Tobias Mann (@Tobias_Writes) April 9, 2024
"Our methodology was to use only IPs that were already proven in silicon before we tape out. At the time we taped out Gaudi3 there was simply no available physical layers that were validated to meet our standards," COO Eitan Medina told The Register
記事にはしていないが、2023年のDCAI Investor Webinarの際にGaudi 3がテープアウトしていることはすでにアナウンスされており、もうこの時点ではSilicon Proven(実際に製造して動作を確認した)なHBM3のI/F IPは存在しているが、ただこの決断はもっと前の話である。
タイムラインで言えば2021年10月にSynopsysはHBM 3のI/F IPと検証用IPの提供を開始しており、Rambusはこれに先立ち2021年8月に8.4Gbpsまで利用可能なHBM3/HBM3EのI/F IPの提供を開始している。
Silicon Provenか? というと、これが実現したのは2021年末~2022年にかけて(TSMCでの5nmのサンプルが実際に出てきたのがこのあたり)で、使う/使わないの判断が行なわれたのはこれよりもっと前だったと考えられる。
Habana Labsがインテルに買収されたのは2019年12月で、もうこの時点でGaudi 2の開発は始まっていた。Mann氏は「おそらくGaudi 3の開発もインテルの買収前に始まっていただろう」と推察しているが、昨今の5nmプロセスの製造には巨大な初期投資が必要で、買収前のHabana Labsでこれをまかなえたかはやや疑問である。
筆者は企画そのものは買収前にスタートしており、実際に開発が始まったのはインテルの買収後ではないかと考える。ただそれはインテルの買収により、5nmプロセスを利用するのに必要な初期投資がまかなえる目途が立ったので"Go"を出した、という感じでそれほど買収から間がない時期だったであろう。
であえば、HBM3のIPがないからHBM2で、という選択は理解できるが、結果としてこれはGaudi 3のスペックをやや見劣りするものにしてしまったことは否めない。実のところ、FP8とBF16の性能が同じ(FP8が倍増しない)理由は、このメモリー帯域がボトルネックになることが見えていたためではないか? と考える。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります