



著作権侵害を未然に防ぐ機能も持つ
昨年紹介した音楽生成AI「Stable Audio」が「Stable Audio 2.0」となり大きく進化した。
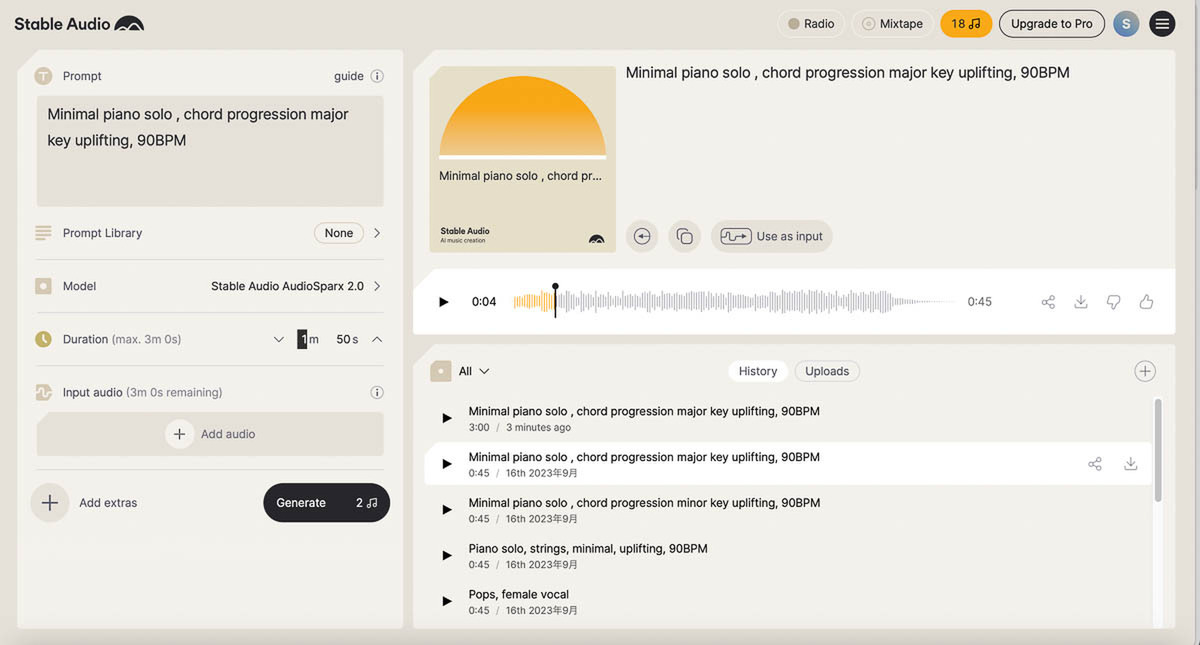
Stable Audio 2.0
生成AIがブレイクするきっかけを作った画像生成AI「Stable Diffusion」を開発したStability AIによる音楽生成AIだ。2023年8月にバージョン 1.0をリリースした際にはこの連載でも紹介した。グーグルの「MusicLM」のようにプロンプトを与えることで、音楽を作り出す音楽生成AIで、Stable Diffusionのようにステップを経て徐々に生成が完了する“拡散モデル”を使用しているのが特徴だ。Stable Audio 2.0では、モデルが新しくなったのが最大の改良点だ。ある入力に対応して生成される出力に関して、生成のルールやパターンを決めるのがモデルである。つまり、知識やアルゴリズムを持つ中核部分が改良されたことになる。
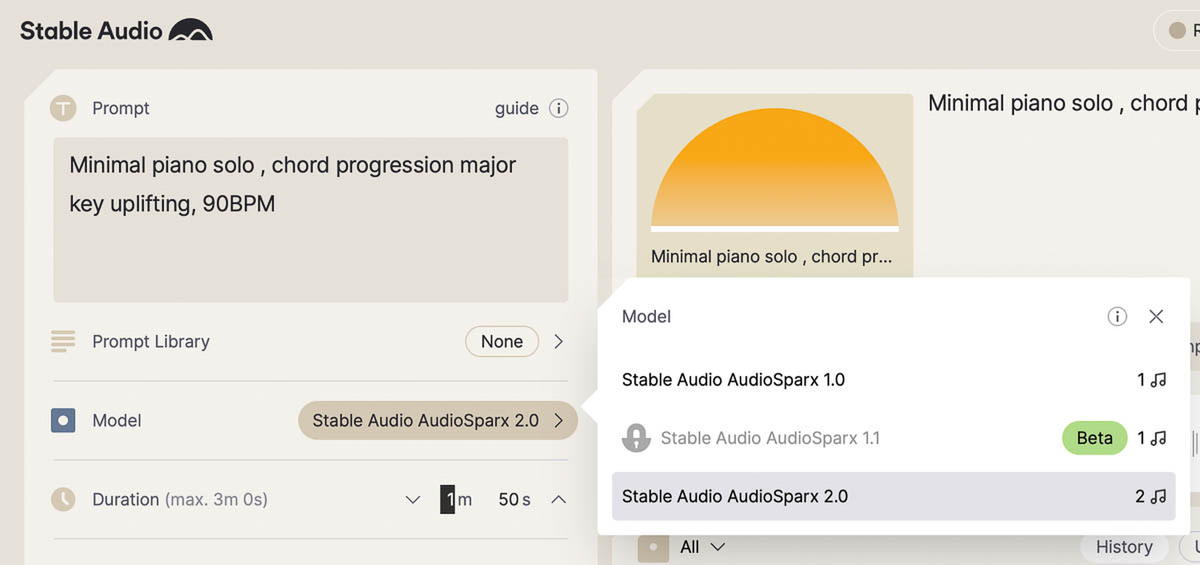
新しいモデル2.0の設定画面
新しい高圧縮オートエンコーダーや拡散トランスフォーマーの導入により、より長い時間スケールでの性能が可能となっている。生成できる時間を3分に延長している。また、Audio to Audio機能も追加された。これはある曲を手本にして、別の曲を作る機能だ。サウンドエフェクト生成もでき、キーボードのタッピングや群衆の歓声なども生成できる。

学習元のサイト
AIで問題となる学習元は、AudioSparx.comと契約し、同社が持つ音楽ライブラリーから「音楽、効果音、単一楽器のステム、および対応するテキストメタデータ」など、80万以上のファイル、1万9500時間以上のデータセットを使用している。また、新たに著作権保護のためにAudible Magicと提携し、リアルタイムのコンテンツマッチングに対応した。ここは、著作権侵害につながりやすいAudio to Audio機能の追加とも関係している。Stable Audio 2.0では、より著作権の問題に対して有効な手段が講じられたと言えそうだ。ここは、新しいモデルを搭載したこと以上の目玉と言えるかもしれない。
異世界転生アニメに使えそうな曲を作ってみる
早速試してみた。無料版のユーザーは、月に最大20曲を作曲できる。ここは従来版と変わらないのだが、モデル2.0を使用した場合は生成に必要なリソースが増えるため、生成できる曲数は半分に減少するようだ。
以前試して分かったのは、Stable Audioではプロンプトを自然言語で入力するよりも、Stable Diffusionのようにジャンルや楽器、テンポなど単語を列挙して行くほうがいい結果を得られることだ。Stable Audioの自然言語解析能力は、グーグルのような先進的な自然言語処理技術と比較して、なんらかの制限があるからかもしれない。今回も同様に単語を列挙するプロンプトで試してみた。記事では日本語に訳すが、実際には英語で入力する必要がある。
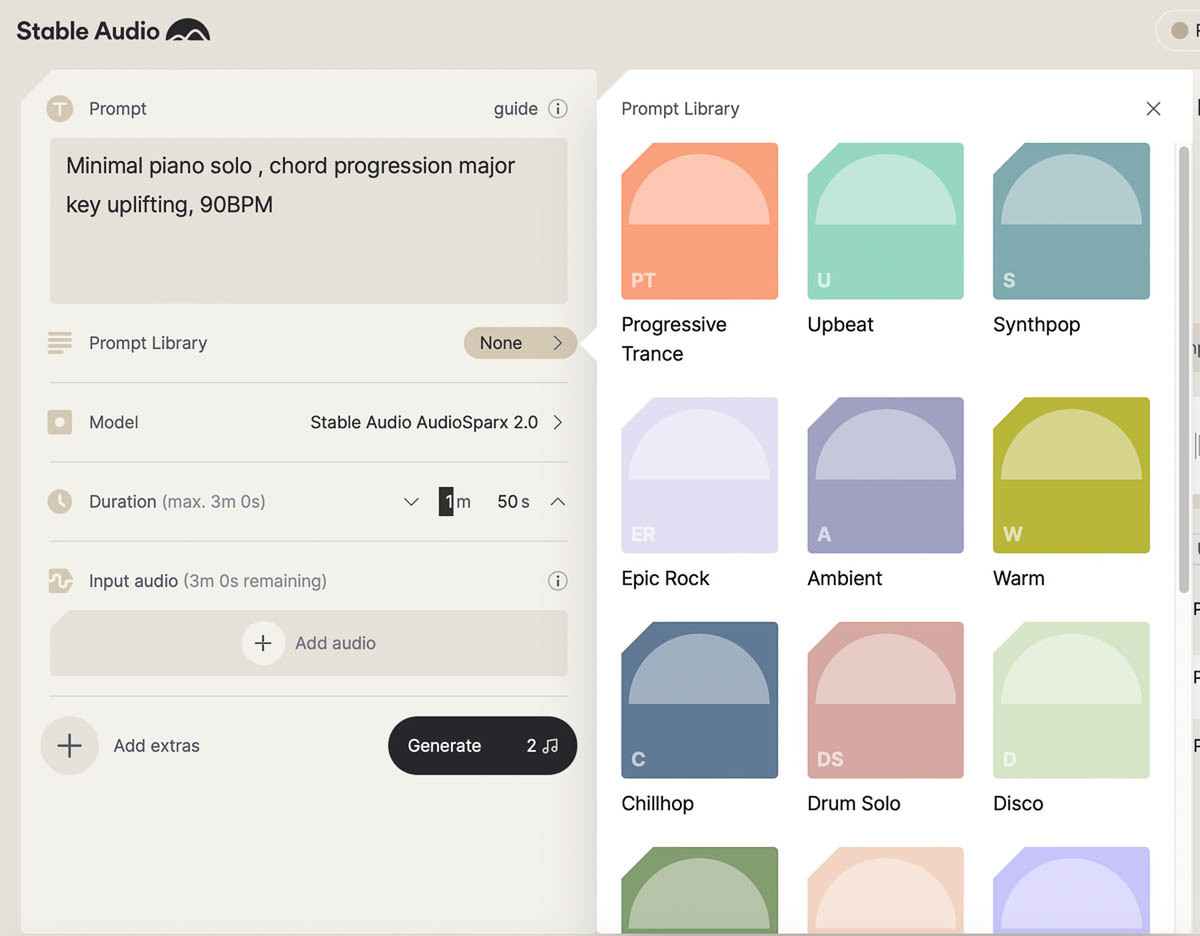
プリセットのプロンプトも利用できる。
はじめに前回と同じプロンプトを使用した。似たような曲にはなるが音質は高くなった。ビットレートが上がったのだろう。有料版ではWAVの出力に対応しているので、さらに良い音質が得られかもしれない。
新しい曲を作ってみた。異世界アニメのサントラを意識し、民族音楽の要素を加えようと考えた。プロンプトは次のようなものにした。「ケルト音楽風のアニメのサウンドトラック音楽。オーケストラがメインだが、民族音楽風のアレンジのためにフィドルとティンホイッスルも使用する。ゆっくりと始まり、徐々に壮大になり終わる」。ちなみにフィドルはバイオリンを民族音楽で使う時の弦楽器の名前で、ティンホイッスルはケルト音楽に特有の管楽器だ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります