



第765回
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ
2024年04月01日 12時00分更新
GB200 Grace Blackwell Superchipは
Grace Hopper比で2.5倍~6倍の性能
さて今回のメインとなるのは、このBlackwellを利用したシステムの話だ。前回示したロードマップにもあるように、本来B100をベースに、ArmベースのGrace CPUを組み合わせたGB200やGB200NVLというソリューションと、x86と組み合わせるB100とB40というソリューションの2つが用意される。
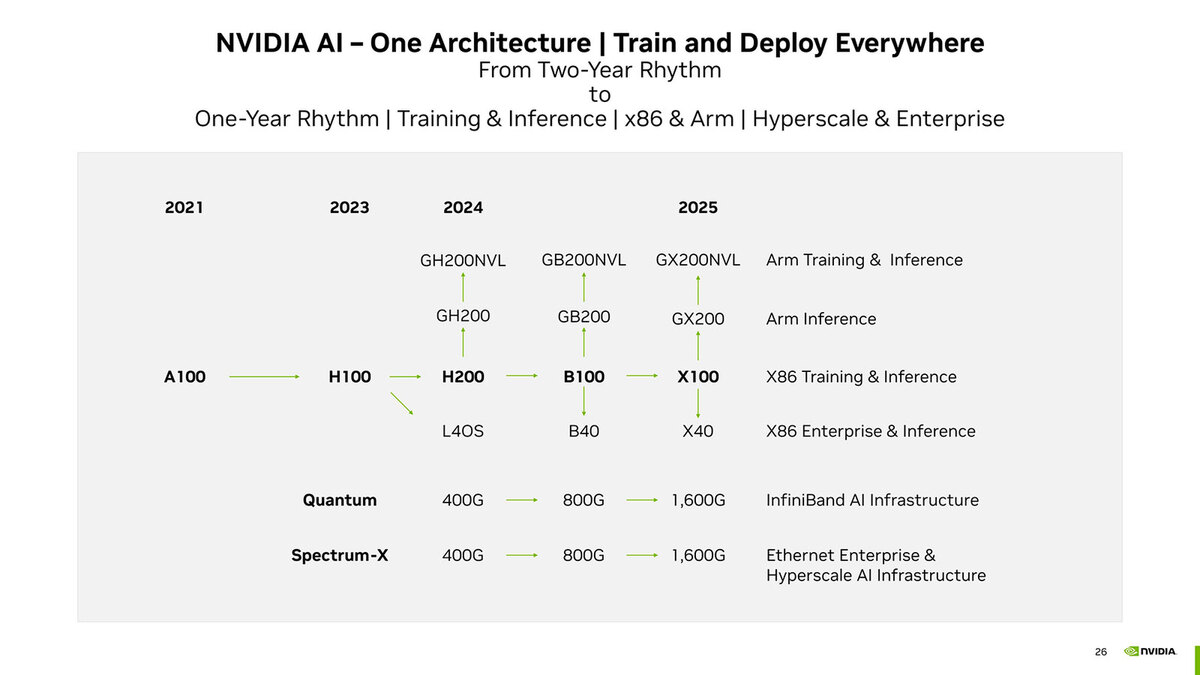
NVIDIAのロードマップ
現時点で公開されているのは、以下の3種類のみである。
- B200×2+Graceを組み合わせた、GB200 Grace Blackwell Superchipと、これを36枚組み合わせたGN200 NVL72
- B200×8を1枚のキャリアボードに搭載した、HGX B200
- B100×8を1枚のキャリアボードに搭載した、HGX B100
まずGB200 Grace Blackwell Superchipというのが下の画像だ。その下の拡大図を見ると、Grace Hopper比で2.5倍~6倍の性能という数字が出てくるが、FP6やFP4を使った場合の数字ということを考えると、この性能が本当に発揮されるのかどうかはTransformer Engineの頑張り次第という感じがする。

B200の搭載メモリー量(HBM3e)は192GBなので、GraceにはLPDDR5xが480GB分搭載される。これはGrace Hopperと同一スペックである

下の方に見える7つのソケットと、右端の2つのソケットはPCIeのOCuLinkのものに見える。ボードの上に垂直にカードを差すのは実装密度の観点から現実的ではなく、OCuLinkを使って外部に引っ張り出すのが一般的だから理解はできる。それにしてもB200とGrace周囲のVRMの配置がエグい
基調講演ではこの開発用のボードも披露された。

右手に持つのが開発用のもので、全体的にかなり広い。左手の方が製品のモックアップである
このGB200 Grace Blackwell Superchip(ボードなのにチップ呼ばわりするのもどうかと思うが)を2枚、1Uのブレードに収めたのがBlackwell Compute Nodeであり、このブレードを18枚集積したのがGB200 NVL72となる。

Blackwell Compute Node。当然のように液冷である

Blackwell Compute Nodeを18枚集積したGB200 NVL72。9枚×2ではなく、10枚と8枚になっているのがおもしろい
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります