



Stable Diffusionで画像からプロンプト(呪文)を生成・抽出する方法。Fooocusの新機能「Describe」が便利でした
2024年01月17日 09時00分更新
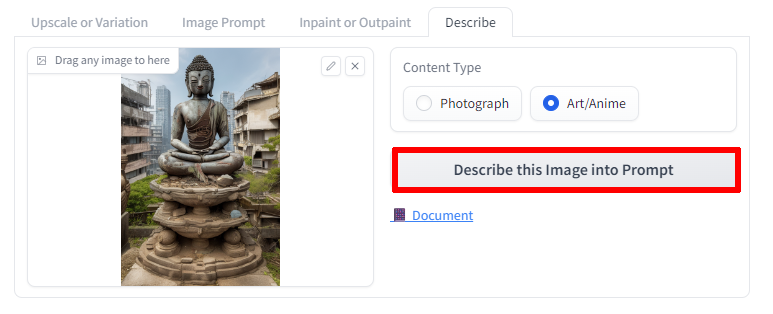
間違えることも多いがご愛嬌
次は少し意地悪をして、人形(ひとがた)ではあるが人間ではない「仏像」が描かれたイラストで試してみよう。

solo, smile, open mouth, sitting, closed eyes, outdoors, sky, day, cloud, no humans, building, indian style, ruins, statue
最後に「statue(彫像)」と入ってはいるものの、これだと人間が出ちゃうんじゃないかしら……。

予想通り、人間が生成された。これはこれでおもしろいのだが、やっぱり仏像も出してもらいたい。

というわけで、冒頭に「buddha statue(仏像)」を追加して再生成。

当たり前だが、狙い通り仏像が生成された。
使い道としては
以上ひととおり試してみたが、この機能はどのような使い道があるのかを考えてみよう。
お手本と似た画像を生成したいだけなら、「image 2 image」や「image prompt」を利用したほうがいいだろう。
これらについては連載第5回(「画像から画像が作れる『Image Prompt』が便利です」)で詳しく紹介している。
そうではなく、「Describe」機能が得意とするのはやはりプロンプト探求だ。「こんな絵を生成したいんだけどプロンプトになにを入れればいいかわからない」という場合、AI画像ならメタデータが入っている場合もあるが、Describeなら、どんな画像からでもそのような結果を出すプロンプトを考えてくれるのだ。
もちろん出力は完璧ではないが、生成されたプロンプトにさらに手を入れたり、後処理を工夫したりすることで、思い通りの絵を作っていけばよいだろう。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります