



第751回
CDNA3のホワイトペーパーで判明した「Instinct MI300X/A」の性能 AMD GPUロードマップ
2023年12月25日 12時00分更新
Instinct MI300Xは単体販売はなくプラットフォームの提供のみ
また今回XCDの2次キャッシュ容量も4MBであることが公開された。十分か? と言えば十分とは言い難いのだろうが、このあたりはダイサイズとの兼ね合いもあるから、最大限努力したというあたりだろうか。
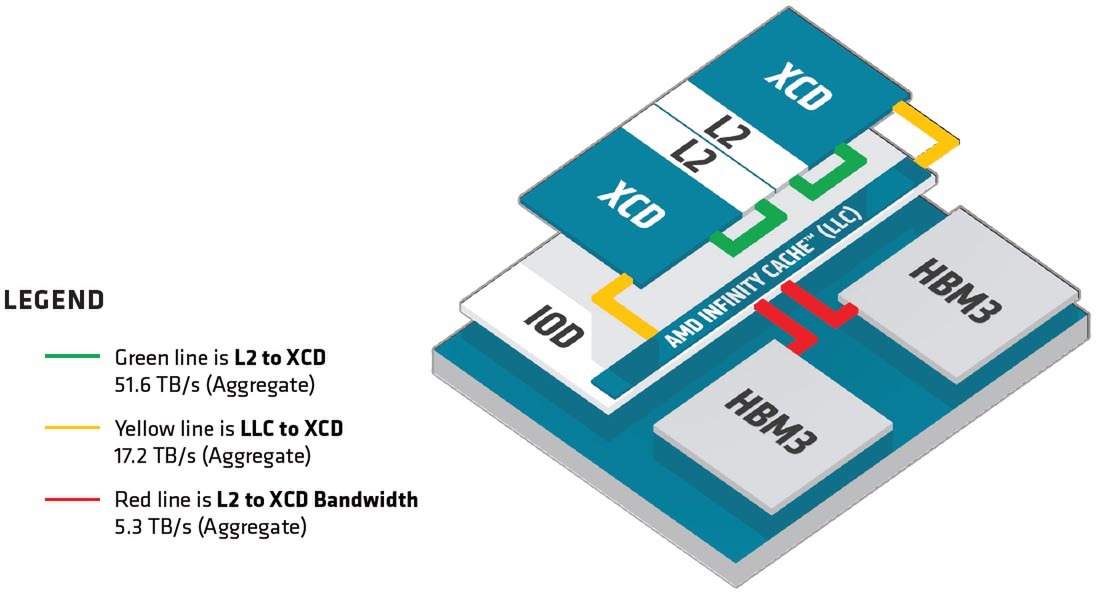
XCDの2次キャッシュ容量は4MB。なお、赤線の説明は明らかに間違っており“LLC to HBM3 Bandwidth”が正しい
XCDと2次キャッシュの間の帯域は51.6TB/秒、インフィニティ・キャッシュとは17.2TB/秒、インフィニティ・キャッシュとHBM3の間の帯域は5.3TB/秒とされる。ただこの5.3TB/秒というのは8つのHBM3での合計の帯域になるので、CU1つあたりの帯域であれば実質665.6GB/秒という計算だ。
連載749回では科学技術計算向けにB/F値を計算してみたが、いろいろ計算の前提が間違っていたことがわかったので、計算しなおしてみる。システム全体でなくXCDあたりの性能で計算してみると、Vector FP64では128Flops/サイクル×38CU×2.1GHz動作なので10.2TFlopsという計算になる。この数字をベースにするとB/F値は以下のようになる。
| Instinct MI300XのB/F値 | ||||||
|---|---|---|---|---|---|---|
| 2次キャッシュ | 51.6TB/秒÷10.2TFlops = 5.06 Bytes/Flops | |||||
| インフィニティ・キャッシュ | 17.2TB/秒÷10.2TFlops = 1.69 Bytes/Flops | |||||
| HBM3 | 0.67TB/秒÷10.2TFlops = 0.07 Bytes/Flops | |||||
さすがに4MBの2次キャッシュでは一瞬で使い切るので、B/F値が5を超えていると言ってもあまり喜べない。ただインフィニティ・キャッシュでもB/F値は1を超えているのはかなり優秀だが、こちらもわずか64MB。そしてHBM3にアクセスになった瞬間にB/F値は0.1を下回っているわけで、B/F値が効いてくるアプリケーションは、いかにプリフェッチを効果的に行なってインフィニティ・キャッシュにヒットするようにするかを細工しないと性能が出しにくそうである。
もっともこれをGPUにやらせるのはかなり無理があり、こうした処理はやはりCPUも一緒に搭載したInstinct MI300Aで行なう方が妥当と考えられる。その意味でも、やはりInstinct MI300XはAI向け製品として扱うのが妥当なのだろう。
ところでInstinct MI300XはOAM(OCP Application Module)の形で提供されるが、どうも単体販売はなく、Instinct MI300X×8をUBB(Universal Base Board) 2.0と組み合わせた形でのプラットフォームの提供のみになるようだ。
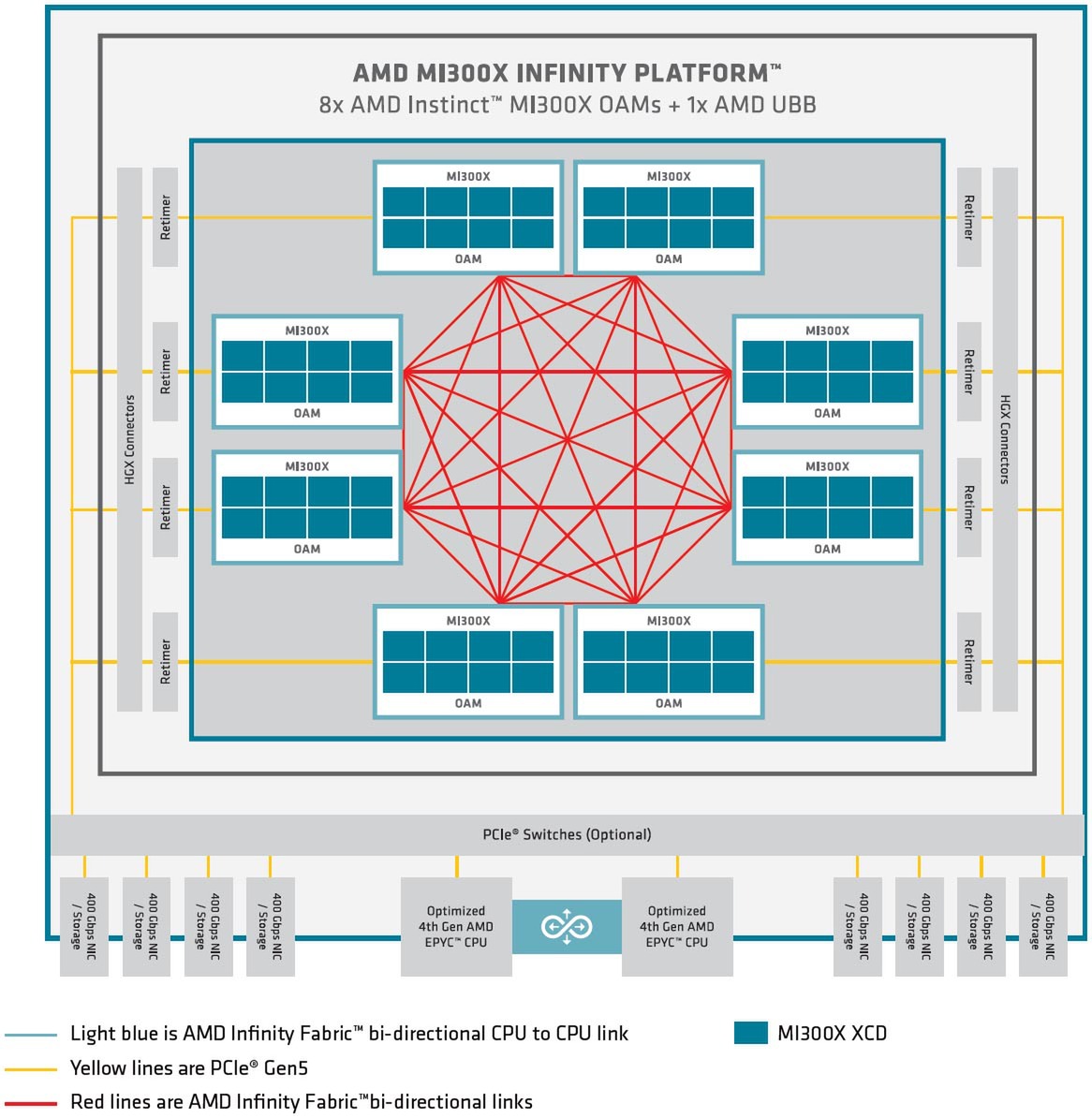
外部に引っ張るPCIe 5.0レーンは、やはり配線長が規定を超えるためかRetimerが全部に入っているあたりがさすがである

Instinct MI300Xプラットフォーム。ちなみにこれは空冷オプションを使った場合の写真だが、液冷も可能である
8つのOAM同士はインフィニティ・ファブリックでピア・ツー・ピアで接続され、ホストとはPCIe 5.0 x16レーンでの接続となる。このPCIe 5.0を直接ホストにつなぐのか、あるいは間にPCIeスイッチを挟むのかは、実際にこのプラットフォームを提供するOEMベンダーが決める話になる。
OAMの1つあたりの最大電力は750W。つまりプラットフォーム全体で最大6KWを消費する計算になる。昨今の「普通の」データセンターの供給電力はラック1本あたり15KW程度が上限のことが多いので、このプラットフォームにフロントエンドのCPUやネットワークのI/Fなどを含むと、7.5KWで収まるかどうか。つまりラック1本にこのシステム2つを収められればラッキー、というなかなか厳しい状況である。
もっともこれはNVIDIAのHGXも同じであり、最近はHigh Density Rackと呼ばれる50~100KWを供給できるラックがこうした用途に利用されつつある。おそらくInstinct MI300Xのプラットフォームもこうしたラックを利用するのが一般的になるだろう。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります