



第751回
CDNA3のホワイトペーパーで判明した「Instinct MI300X/A」の性能 AMD GPUロードマップ
2023年12月25日 12時00分更新
今回は連載749回の続きであるが、CDNA3のホワイトペーパーが公開されたことで、Instinct MI300X/300Aの正確なスペックが判明した。まずは連載749回の訂正からスタートする。
Instinct MI300XはMI250世代からMatrix Engineのみが強化
XCDのスペックについて連載749回で、XCDが1つあたり38XCUと書いたのは正確であったが、XCDの性能はInstinct MI250Xの2倍になると推定したのだが大外れであった。下の画像がホワイトペーパーに記載された性能である。
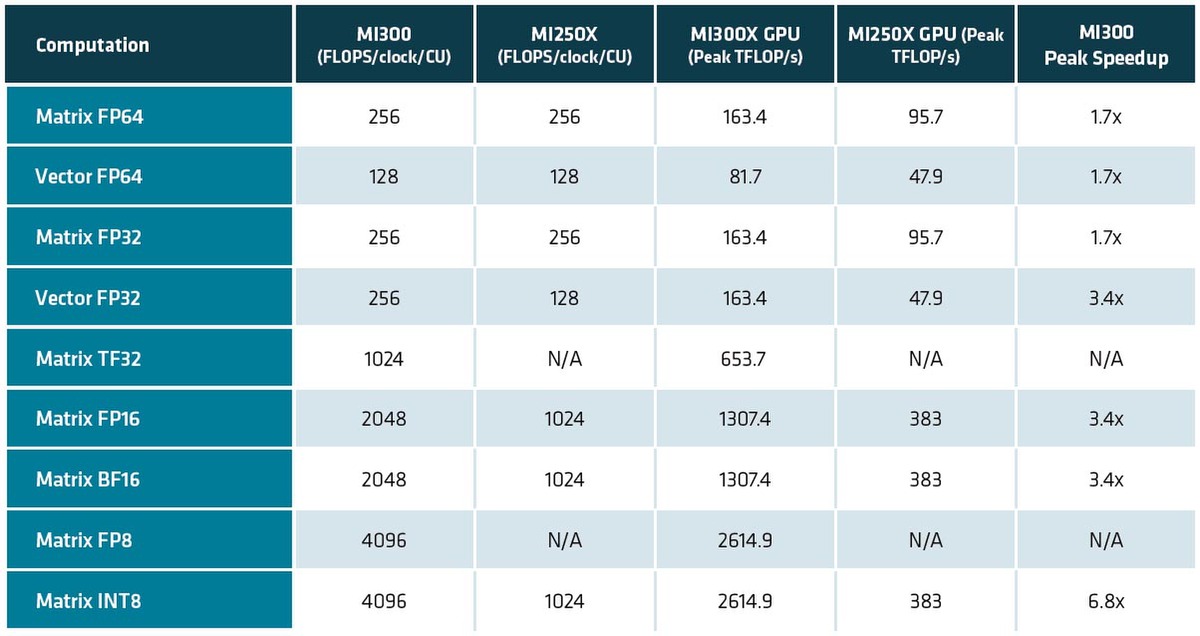
Instinct MI300Xの性能。こうしてみると、Vector EngineそのものはMI250世代から変わっておらず、手が入ったのはMatrix Engineのみになる
この性能と連載479回の結果を比較したものが下表である。MI250世代からMI300世代では、Matrix Engineのみが強化されたわけで、CUそのものは変わっていなかった。
| Instinct MI300Xのホワイトペーパーと連載479回の推定結果を比較したもの | ||||||
|---|---|---|---|---|---|---|
| 演算 | 筆者推定 | 実際 | 正否 | |||
| Vector FP64 | 256Flops/cycle | 128Flops/cycle | × | |||
| Vector FP32 | 512Flops/cycle | 256Flops/cycle | × | |||
| Vector FP16/BF16 | 1024Flops/cycle | N/A | × | |||
| Matrix FP64 | 512Flops/cycle | 256Flops/cycle | × | |||
| Matrix FP32 | 512Flops/cycle | 256Flops/cycle | × | |||
| Matrix TF32 | 1024Flops/cycle | × | ||||
| Matrix FP16/BF16 | 2048Flops/cycle | 2048Flops/cycle | ○ | |||
| Matrix FP8 | 4096Flops/cycle | 4096Flops/cycle | ○ | |||
| Matrix Int8 | 2048Ops/cycle | 4096Ops/cycle | × | |||
つまりHPC向けの演算性能は、基本的な部分がMI250世代と変わっていないので、なるほどAMDがMI300XシリーズでAI性能の高さを大々的にアピールしていたわけである。また、MI200世代ではXCUという表記だったのが、MI300世代ではCUに戻っている。したがって、以下は表記をCUに戻す。
Matrixに関しても、FP64/FP32が全然変わっていない。もちろん科学技術計算でMatrix Engineを利用する可能性があるので、ここはMI250世代と同じスペックは維持している。一方でAI向けで言えば、学習用途でFP64を使う可能性はまずなく、FP32も最近はあまり使われなくなっている。
ただFP16/BF16では精度的にやや足りない用途向けに新たにTF32が追加され、これが1024Flops/サイクルとMI250のFP32から8倍のスループットになった。TF32は仮数部10bit、指数部8bit、符号1bitの合計19bitのフォーマットである。
FP32は仮数部23bit、指数部8bit、符号1bitの32bit、FP16は仮数部10bit、指数部5bit、符号1bitの16bitであり、「FP32並みの指数部とFP16並みの仮数部」のフォーマットだ。
最初にTF32を採用したのはNVIDIAで、連載730回で説明したとおり、A100でTensorFloat-32として導入したものだ。
またMatrixのINT8は2倍でなく4倍の4096Ops/サイクルまで強化されている。16bit幅で2048Flops/サイクルなのだから、8bit幅なら当然その倍になるわけだ。ちなみに動作周波数は推定通り2.1GHzになる。
ただそれでもCU数そのものがMI300Xは304CUと多い(MI250Xは220CU)うえ、動作周波数も高い(MI250Xは1.7GHz)こともあり、CU数で38.2%、動作周波数で23.5%の向上がある。結果、Vector Engineを使った場合でも軒並み70%の性能向上、Matrix Engineでは性能が3.4倍なり6.8倍に向上するわけだ。
ちなみに上の画像の数字はオプションなしでの数字となるが、Matrix Engineに関してはMI300世代でSparsityをサポートした。これは入力する4要素のうち2つ以上が0だった場合には疎行列として扱うことで性能を引き上げるという、NVIDIAのA100以降で搭載された技術と同じものだ。
Sparsityを利用した場合、TF32で10.5FPlops、FP16とBF16で20.9PFlops、FP8とINT8では41.8PFlops/41.8POpsまで処理性能が向上するとしている。そういう意味でもH100と肩を並べる性能になったわけだ。
もう1つ肩を並べるものとしては、仮想化のサポートもある。NVIDIAはA100世代でGPCごとにインスタンスを実行できるので、見かけ上最大7つのGPUを同時に使えるようになる、という話は連載663回で説明したが、同様にMI300も最大8つまでのインスタンス(AMDはこれをパーティションと呼ぶ)を同時に利用できるようになった。このあたりもA100/H100と肩を並べた格好だ。

最大8つまでのインスタンスを同時に利用できる。1/2/4/8分割を選べるようになった
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります