



グーグル、LLMを活用したマルチモーダル動画生成モデル「VideoPoet」発表
2023年12月21日 11時55分更新

グーグルの研究開発機関Google Researchは12月19日(現地時間)、テキストや画像から動画を生成するなど様々な動画生成タスクに対応できる大規模言語モデル(LLM)「VideoPoet」を発表した。
マルチモーダル対応
「VideoPoet」は、動画、テキスト、画像、音声など多様なメディア形式に対応するマルチモーダルモデル。
上記のショートムービーは、旅するアライグマについての短い物語を「Bard」に書いてもらい、それぞれのプロンプトに対してビデオクリップを生成し、それをつなぎ合わせたものだ。
テキストから動画

「A Raccoon dancing in Times Square(タイムズスクエアで踊るアライグマ)」というテキストから生成された動画。
画像とテキストから動画

こちらは画像とテキストの組み合わせから動画を作成した例。例えばいちばん左の船の画像に「A ship navigating the rough seas, thunderstorm and lightning, animated oil on canvas(荒波を進む船、雷雨と稲妻、キャンバスに油彩のアニメーション)」というテキストを組み合わせて動画化したものが左から2番めの動画だ。
動画とテキストから動画

動画とテキストの組み合わせから新規動画を生成できる。たとえば左側の動画に「Wombat wearing sunglasses holding a beach ball on a sunny beach(晴れたビーチでビーチボールを持つサングラスをかけたウォンバット)」というテキストを組み合わせて動画をスタイライズ(後処理)したもの。
拡散モデルではなくLLMを使用
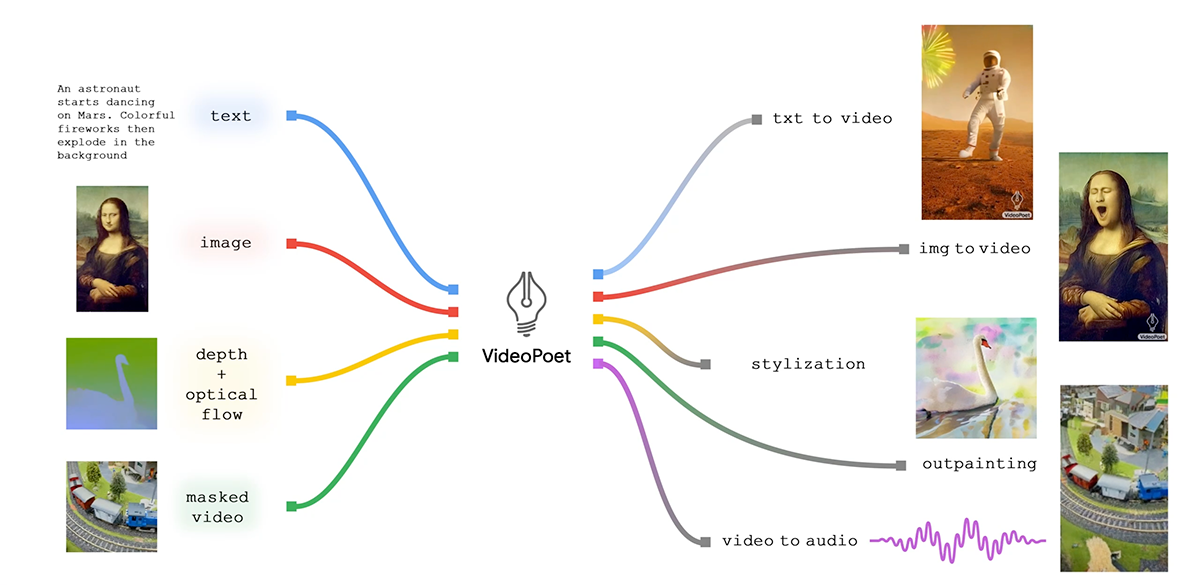
現在、主要な動画生成モデルはほとんどが拡散(Diffusion)モデルをベースにしているが、本モデルは大規模言語モデルを用いているのが特徴だ。
各タスクに特化した個別に訓練されたコンポーネントに依存するのではなく、単一のLLM内に多くのビデオ生成機能をシームレスに統合している。

内部的には、ビデオやイメージをトークンにエンコード/デコードする複数のトークナイザー(ビデオとイメージはMAGVIT V2、オーディオはSoundStream)を使用しており、学習と生成はこれらが用いられている。
ベンチマークも優秀
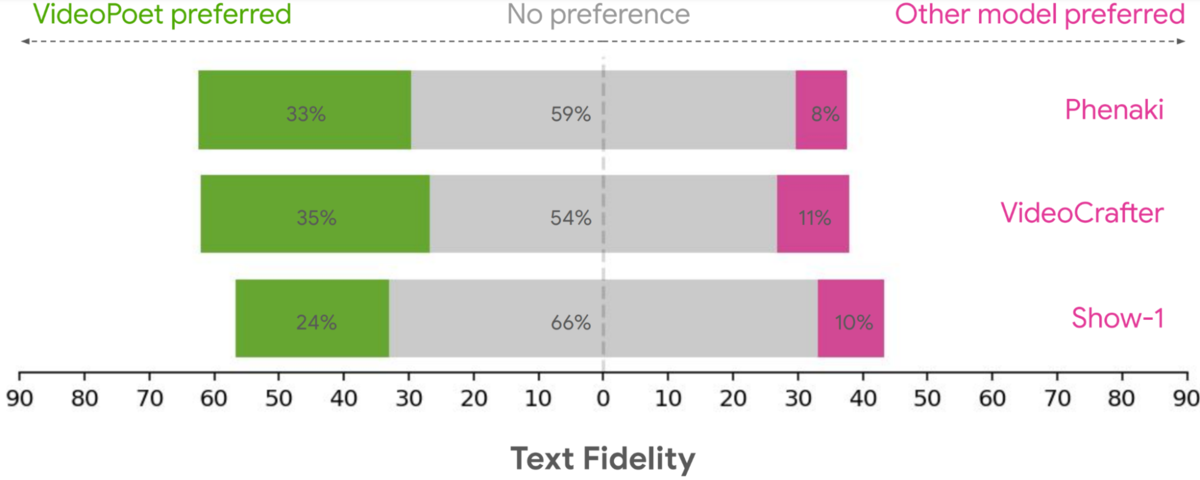
上記はプロンプトへの追従性についてPhenaki、Videocrafter、Show-1といった競合モデルと比較したもの。緑色がVideoPoetを支持した人の割合だ。
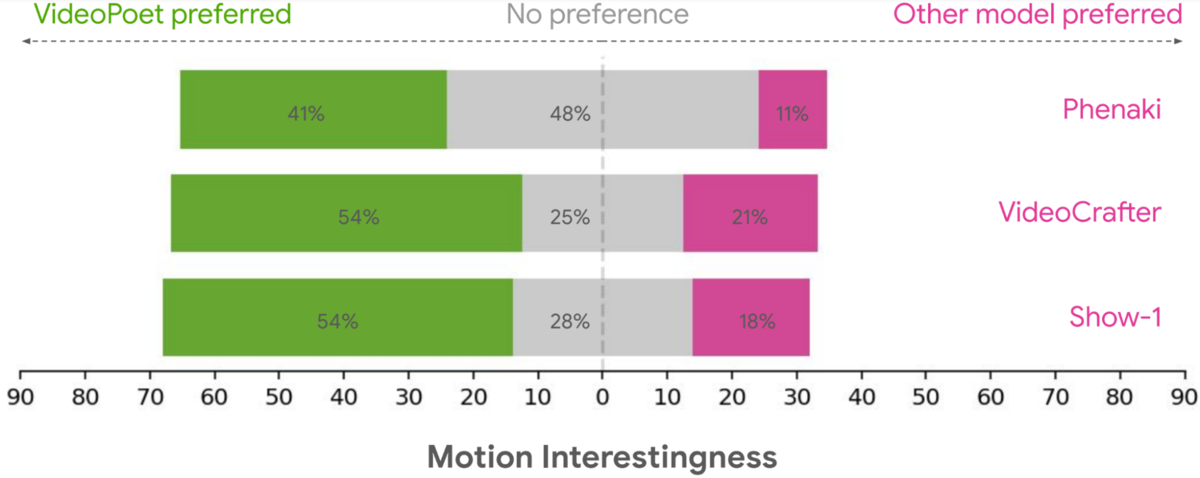
こちらは「動きのおもしろさ」について聞いたもの。より多くの被験者がVideoPoetの動きはおもしろいと感じているようだ。
現時点ではRunwayやPikaなどのツールに比べて出力品質は劣るとグーグルも認めているが、今後も研究を続けていくとしている。将来の展開として、文章から音声を生成したり、音声から動画を生成するといった「any-to-any」生成技術の開発も含まれている。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります