



第749回
生成AI向けGPU「Instinct MI300X」はNVIDIAと十分競合できる性能 AMD GPUロードマップ
2023年12月11日 12時00分更新
転送速度が落とされている
Intinct MI300XのHBM3
それとやや謎なのが、HBM3である。本来HBM3は6.4Gbps/pinの帯域を持つ。Hostとは1024bit I/Fで接続されるので、メモリー帯域は1スタックあたり6.4Tbps=819.2GB/秒である。Instinct MI300Xはこれを8スタック搭載するので、本来ならば819.2×8=6553.6GB/秒、つまり6.5TB/秒のメモリー帯域がある計算になる。
ところが実際には5.3TB/秒の帯域と説明されている。ということは、HBM3の転送速度が5.2Gbpsかそのあたりまで落とされているわけだ。可能性として考えられるのは以下のとおり。
(1) 6.4GbpsのHBM3 スタックの供給が間に合わなかった、もしくは速度の歩留まりが低くてもう少し動作周波数を下げないと満足に入手できない。
(2) 6.4Gbpsで転送すると消費電力が過大になるので、転送速度を下げた。
(3) XCDがそこまでのメモリー帯域を必要としないので、バランスをとれるところまで下げた。
(4) メモリーコントローラーが追い付かない
このうちありそうなのは、(1)と(2)である。実際、同じくHBM3を実装しているNVIDIAのH100は4.8Gbps/pinに転送速度を落としているという話は連載661回で説明したとおり。
メーカーの方を見てみると、SamsungのIceboltは6.4Gbps/pinと言いつつまだサンプル出荷段階、SK HynixのHBM3も、MP(Mass Production)なのは5.6Gbps/pinで、6Gbps/pinはまだCS(Customer Sample)状態。MicronはそもそもHBM2Eの後、直接HBM3Eに行くようで、HBM3の製品ページ自体がない状態だ。
6.4Gbps品の製品開発そのものは各社とも完了し、すでに9.6GbpsのHBM3Eの開発完了を発表しているところもあるが、量産はまた別ということだろう。またInstinct MI300XのIODはTSMC N6だが、確かにこれで6.4GbpsのPHYを動かすと、それなりに発熱がすごそうだ。
6.4Gbpsという信号速度はDDR5-6400と同じだが、こちらは64bit幅なのに対してHBM3は1024bitなので16倍になる。もう少し動作周波数を落として消費電力を下げたい気持ちはわからなくもない。
(3)に関しては、AIはもうメモリー帯域はあればあるだけ良いので考えても無駄として、ではHPC系の科学技術計算は? というのを試算してみる。上の表にあるように、FP64のVectorでは128Flops/cycleなので、308XCUで78848Flops/Cycle。先の試算の2.1GHz動作だとすると165.5TFlopsほどになる。Instinct MI250Xがピークで47.9TFlopsなので4倍ほどの性能になる計算だ。
さてこの場合のB/F値(Bytes/Flops)だが、5.3TB/秒に対して165.5TFlopsになるので、全然お話にならない(0.03Bytes/Flops)数値であり、このあたりを考えても(3)はあり得ないところだろう。
(4)については、例えばRadeon RX 7000シリーズの上位グレードはXCDを同じくTSMC N6で製造しているが、こちらは19Gbpsにも耐えられるわけで、発熱の問題はあるにしても考えにくい。ということで可能性としては(1)と(2)あたりが理由となりそうだ。
ちなみにこのInstinct MI300Xであるが、H100との比較ではLLM Kernelの演算性能で1.1~1.2倍、8 GPU構成でのトレーニング速度はH100と同等、130億パラメーターのLlama 2の推論速度はH100の1.2倍といった数字が示されている。
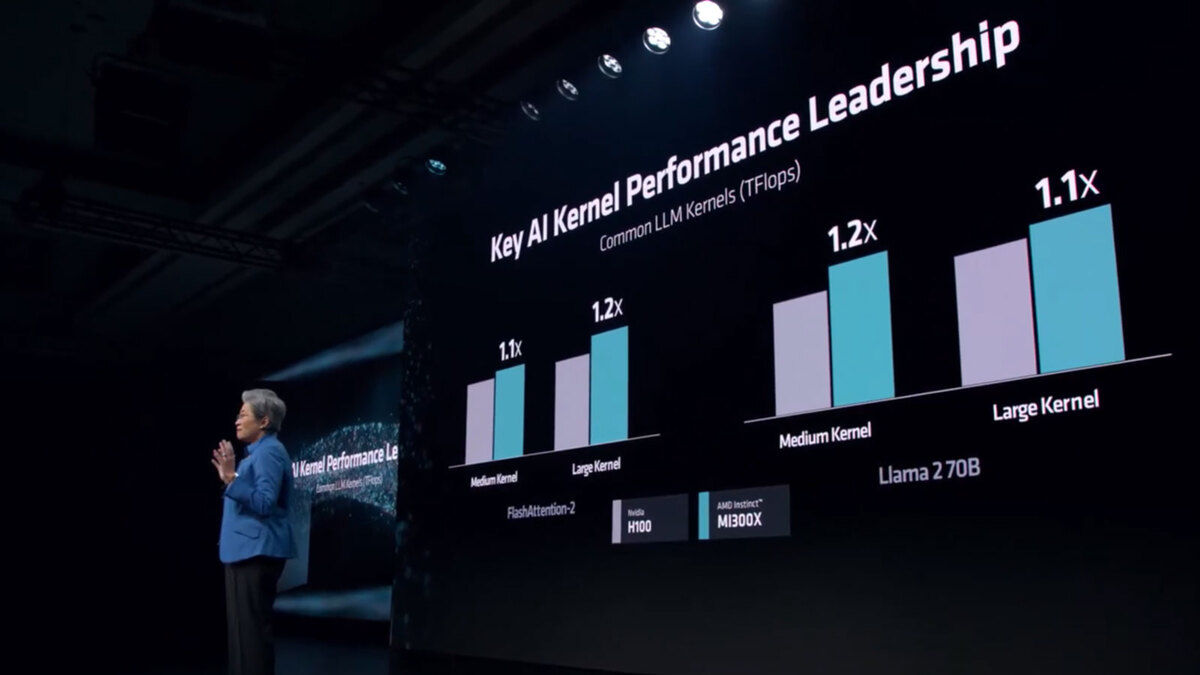
左はFlashAttention-2、右はLlama 2(パラメータ数700億個)での比較。ただこれ、スループットではなく演算性能とされている点に注意

説明では300億個のパラメーターをもつLLMを実施した場合の比較とのこと

これはパラメーター130億個のLlama-2の推論を実行した際のレイテンシーの比較
連載730回で触れたが、同じモデルを実行した場合、ソフトウェア側の問題で性能が出ない件に関しても、今回発表されたROCm 6では特に生成AI向けに大幅な最適化をしたとしている。

あくまでもこれはLLMを実施した場合をROCm 5とROCm 6で比較したもので、CUDAコードの変換などに関しては今回特に数字などは示されなかった
MI300Xでページを費やし過ぎてしまったので、MI300Aに関しては次回お届けしたい。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります