



NTT、独自のAIモデル「tsuzumi」 日本語性能はGPT-3.5超え
2023年11月02日 17時00分更新

日本電信電話(NTT)は11月1日、同社独自の大規模言語モデル(LLM)「tsuzumi」を用いた商用サービスを2024年3月に開始すると発表した。
tsuzumiは日本語と英語に対応したLLM。同社が長年の研究成果を活かした高い日本語処理能力をもっており、生成AI向けのベンチマーク「Rakuda」では日本語性能でOpenAIの「GPT-3.5」を上回るスコアを獲得。英語についても世界トップクラスと同程度のスコアを出せるという。
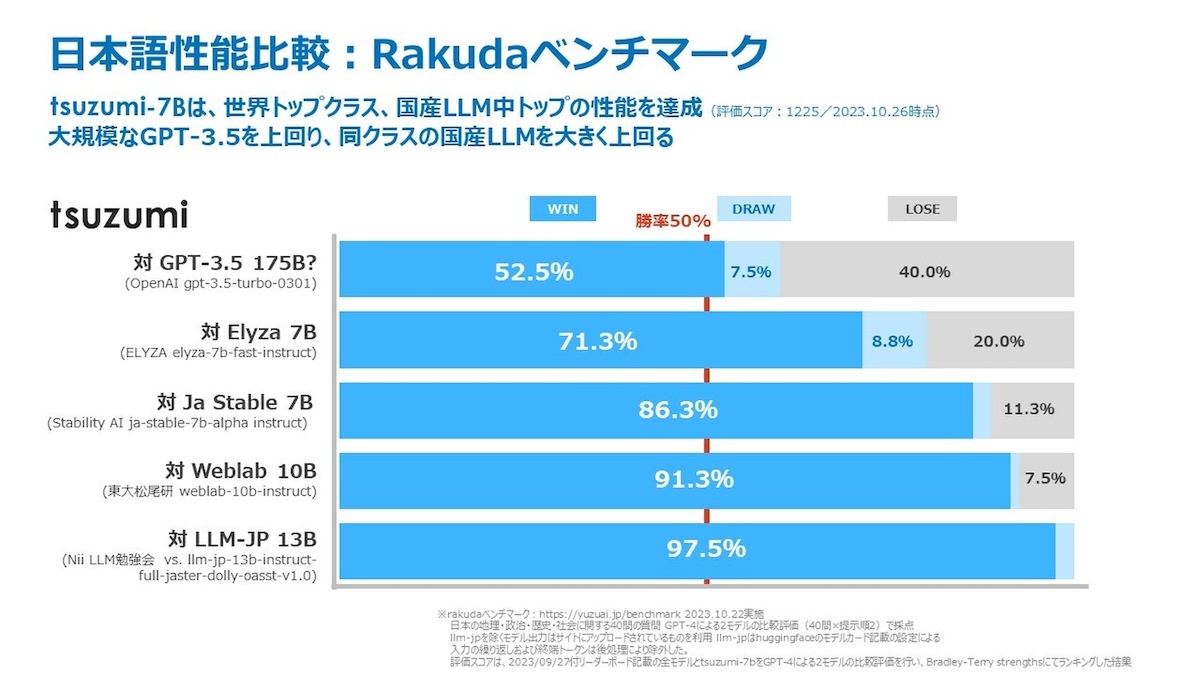
Rakudaの日本語性能ベンチマーク結果をほかのLLMと比較したグラフ
同LLM最大の特徴は、一般的なLLMと比較してパラメーター数が少ないこと。具体的には前述のGPT-3.5が約1750億パラメーターを持つ一方、tsuzumiは軽量版でGPT-3.5のおよそ1/25、超軽量版ではおよそ1/300となっている。パラメーター数の減少は動作にも反映されており、軽量版は1つのGPUで、超軽量版ではCPUで高速な推論が可能。大規模なGPUクラスタを必要としないため、運用時の経済的な負担が大きく減少した。
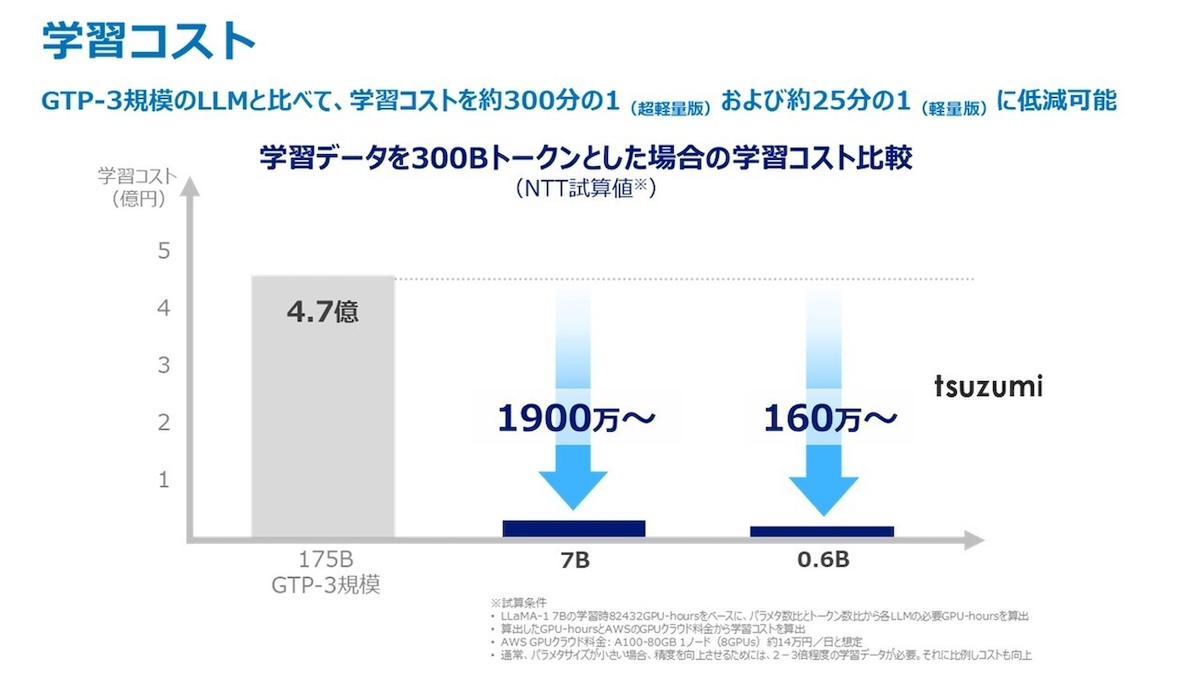
学習コストの比較
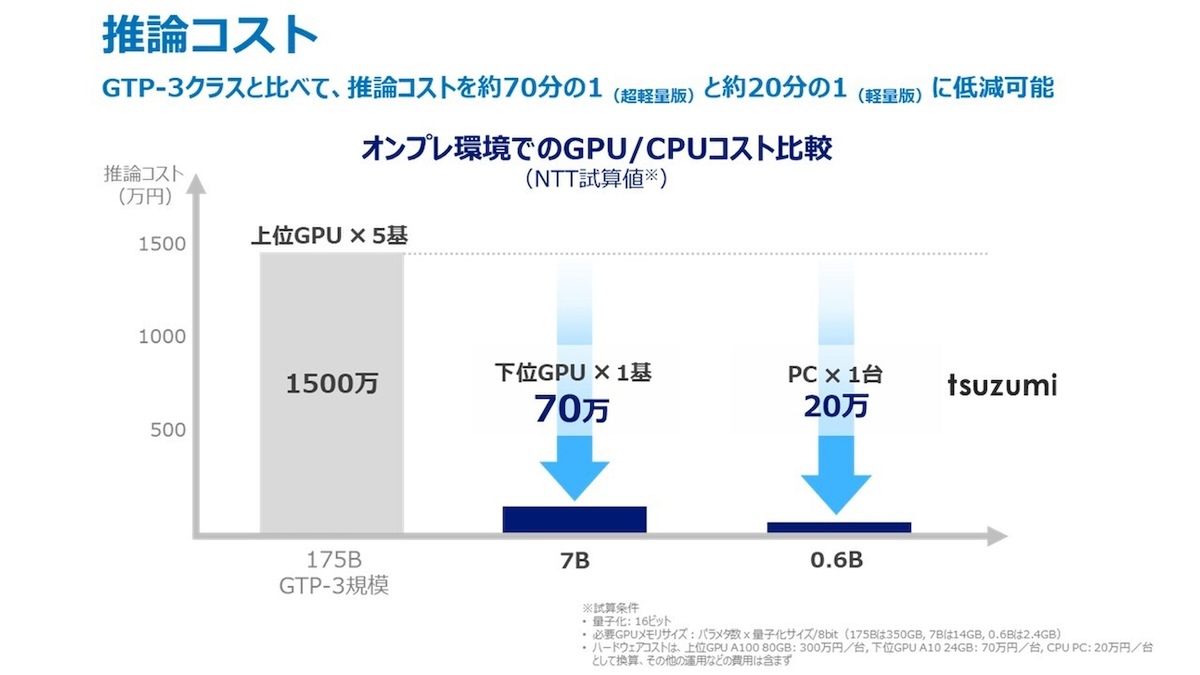
推論コストの比較
また、利用実態にあわせ、ベースとなるモデルに「アダプタ」と呼ばれるサブモジュールを接続する仕組みを採用。AIに細かいチューニングを施す際、ベースモデルのパラメーターを固定したまま、アダプタ側のパラメーターのみを変化させることで、計算コストの高いベースモデルの再学習を回避しつつ、AIに知識を学ばせることができる。
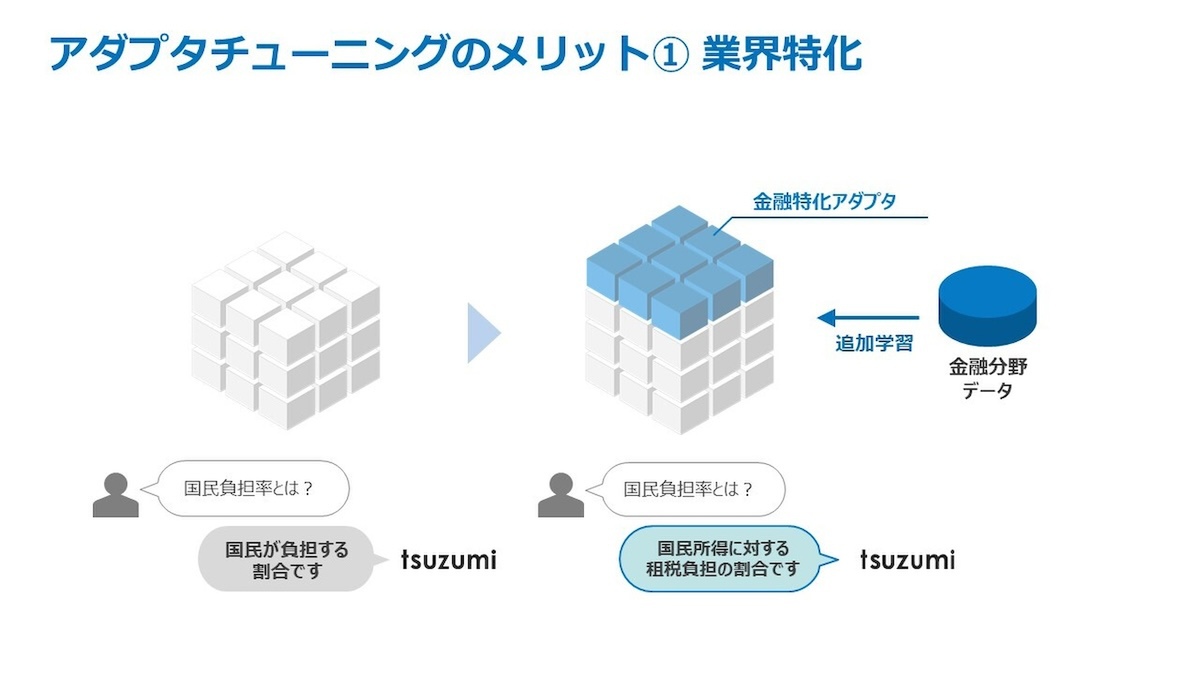
アダプタによるチューニングの例(1)
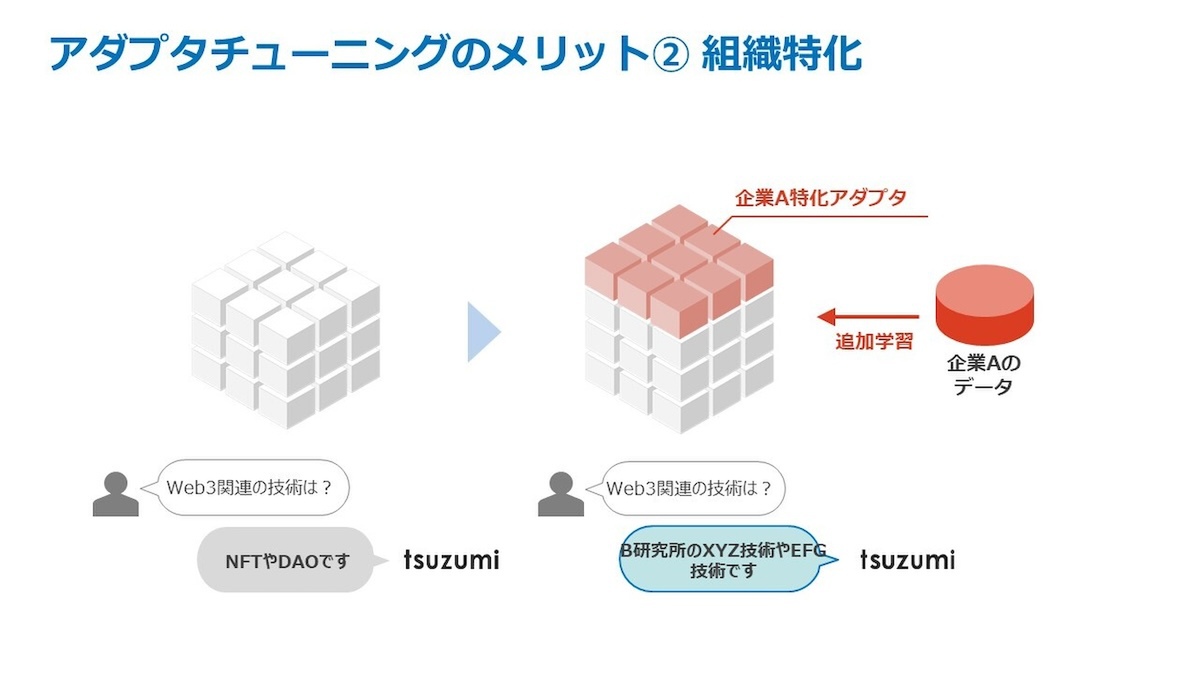
アダプタによるチューニングの例(2)
同社は今後、tsuzumiのマルチモーダル対応も予定。グラフィカルな表示や音声のニュアンス、顔の表情などを理解し、人間側の置かれた状況も理解した上で、人間と協調して作業できるようにすることも目指すという。
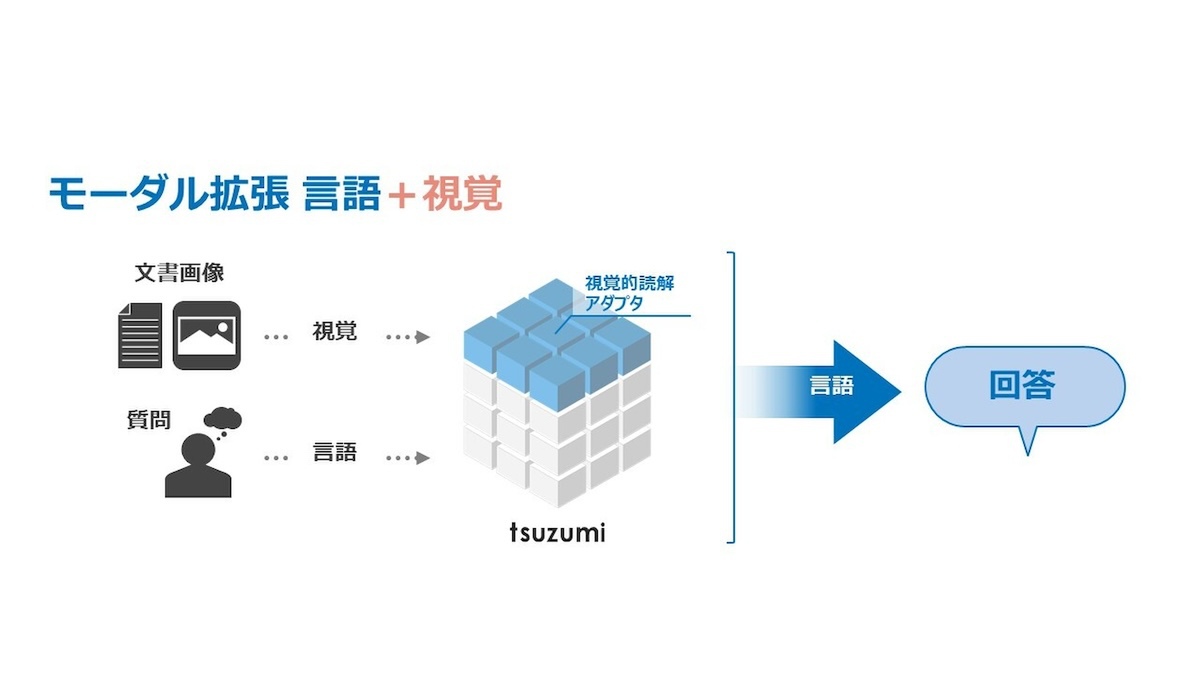
マルチモーダル対応のイメージ
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります