



Stability AI Japan、最高水準の日本語言語モデル2種を公開
2023年10月25日 14時00分更新

Stability AI Japanは10月25日、日本語タスクを用いた性能評価でトップクラスの性能を示す日本語向け大規模言語モデル(LLM)「Japanese Stable LM 3B-4E1T(およそ30億パラメーター)」と「Japanese Stable LM Gamma 7B(およそ70億パラメーター)」を商用利用可能な「Apache 2.0」ライセンスでリリースした。
英語モデルをベースに継続事前学習
今回発表されたモデルは同社が2023年8月に公開した「Japanese Stable LM Alpha」シリーズと異なり、もともと英語モデルとして制作・公開された「Stable LM 3B-4E1T」「Mistral-7B-v0.1」をベースに、日本語を主としたデータを用いて更に事前学習を実行した継続事前学習(Continued Pretraining)と呼ばれるアプローチで日本語の能力を追加している。
継続事前学習にはWikipedia、mC4、CC-100、OSCAR、SlimPajama(Books3を除く)などの日本語と英語データのべ約1000億トークンが使用されている。
全モデルが商用利用可能
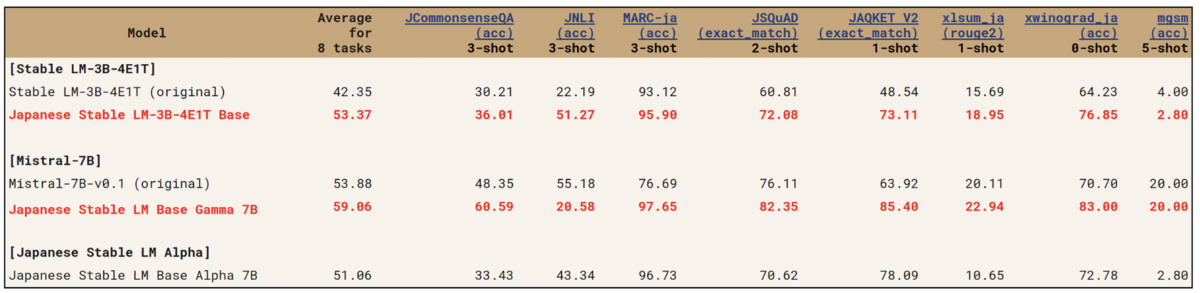
「Japanese Stable LM 3B-4E1T(30億パラメーター)」は比較的小規模なモデルであるにも関わらず、2023年8月に公開した「Japanese Stable LM Alpha(70億パラメーター)」を上回る性能を発揮している。
また、「Japanese Stable LM Gamma 7B」のベースとなる、Mistral AI が2023年9月に公開した「Mistral-7B-v0.1」は、130億パラメーターを持つメタの「Llama-2 13B」を全項目で上回っており、その性能をそのまま活かすことに成功している。
全モデルが商用利用可能な「Apache License 2.0」公開されており、自由に推論や追加学習を行なうことができる。今後は様々なAPIやクラウドサービスへの搭載も計画しているという。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります