



産総研、世界トップレベルの生成AIの開発を開始
2023年10月19日 17時45分更新
プロジェクトの概要
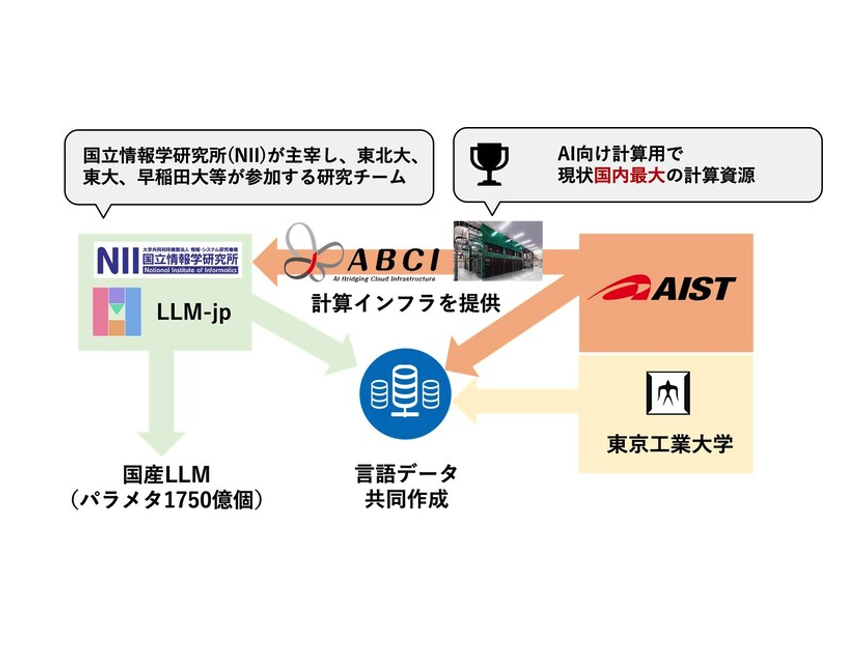
産業技術総合研究所(産総研)は10月17日、東京工業大学(東工大)、国立情報学研究所が主宰する勉強会「LLM-jp」と共に、世界トップレベルの生成AIの基盤となる大規模言語モデル(LLM)の開発を始めると発表した。
開発の第一段階として、OpenAIが提供する「GPT-3」と同等の規模、1750億個のパラメタ数をもったLLM構築に着手。産総研は、LLM構築に必要な計算資源「AI橋渡しクラウド(ABCI)」を提供するほか、東工大、LLM-jpと協力して開発に必要な高品質かつ大規模な共有データセットを構築する。
国産LLMを開発する理由について産総研は、日本以外の企業や研究機関がクローズドな環境で開発したLLMは、構築の過程がブラックボックス化しており、権利侵害や情報漏えいの懸念を払拭できないと指摘。こうしたリスクを避けるために、透明性が高く安心して利活用できる国産LLMを開発する必要があると説明している。
同日現在、具体的な開発スケジュールは未発表だが、同LLMの完成後はLLM-jpにて、オープンに利用できるかたちで公開される予定だ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります