



第740回
Meteor LakeのNPU性能はGPUの7割程度だが消費電力が圧倒的に少ない インテル CPUロードマップ
2023年10月09日 12時00分更新
OpenVINO以外のソフトウェアが使える
さてハードウェアに関してはおおむねこの程度しか情報が開示されていないが、ソフトウェアについても説明しておきたい。
もともとMyriad 2/Xの場合、ソフトウェアフレームワークとしてはOpenVINOを使うことを強く推奨していた(事実上他に選択肢がなかった)わけだが、Meteor Lakeでは広範なアプリケーションに対応する必要があり、そこでOpenVINOだけ、という選択肢はさすがに存在しないと判断したためか、ずいぶん複雑なソフトウェアフレームワークが提供されることになった。
Meteor Lakeでは基本的に以下の4種類のAPIが提供される。
| Meteor LakeのAPI | ||||||
|---|---|---|---|---|---|---|
| API | 概要 | |||||
| WinML | Windows Machine Learningのこと。基本はMLASライブラリー経由でCPUを利用することになるが、オプションでDirectMLを呼び出して使うこともできる。 | |||||
| DirectML | 基本はGPUを呼び出して使うことになるが、Meteor LakeではここでNPUを呼び出すオプションが追加された。 | |||||
| ONNX RT | こちらは利用時にOpenVINOないしDirectMLのどちらかを指定する形で利用する。OpenVINOなら基本NPUで、DirectMLならGPUでそれぞれ処理する。 | |||||
| OpenVINO | 基本はNPUを利用するが、今回GPUを利用するオプションが追加された。 | |||||
一番柔軟性が高いのがWinMLを使った場合で、CPU/GPU/NPUのどれを使うことも可能である。DirectML/ONNX RT/OpenVINOではGPUないしNPUを選択できる。おそらくONNX以外はデフォルトがDirectML→GPU、OpenVINO→NPUになっており、オプションを追加しないとこのデフォルトが使われるのだろう。
この場合、GPUがDirectMLに対応できる機能が必要になる。具体的にはDirectX 12のShader Model 6.4で提供されるDot-Products 2/4をハードウェアで実行できる必要がある。この詳細は次回説明するが、Meteor LakeのGPUはXMX(Matrix Engine)を持たない代わりに、Xe CoreにDP4Aの機能を追加してこれをカバーしている。
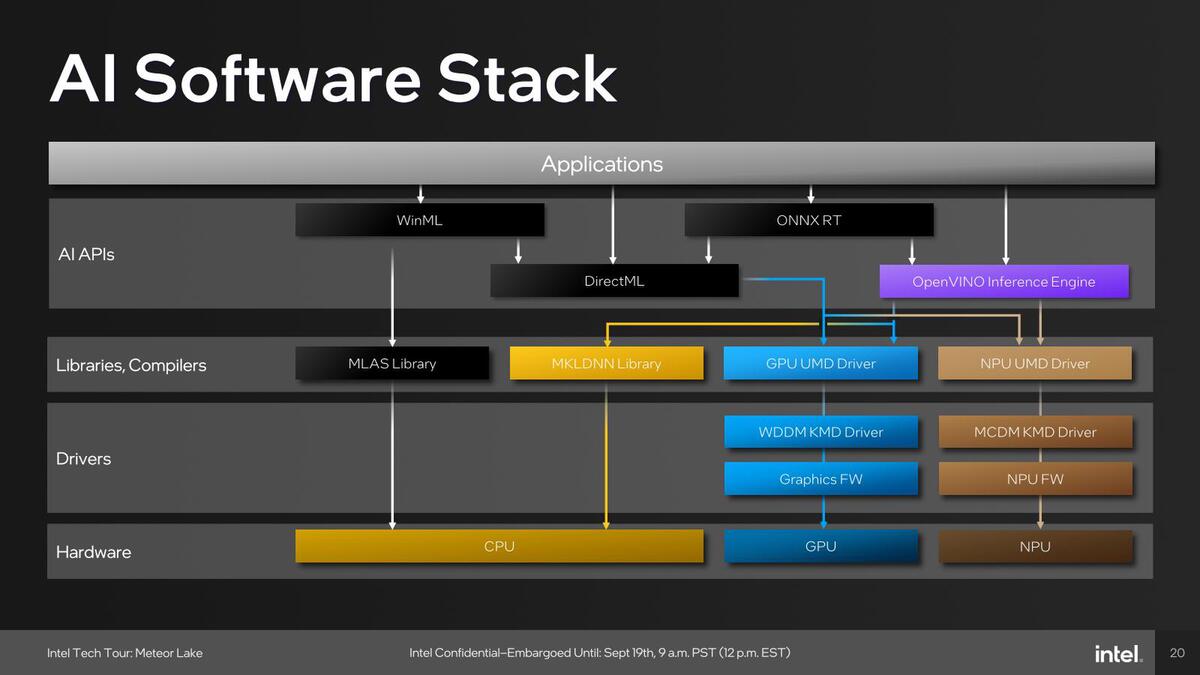
気になるのはMeteor LakeにディスクリートGPU(ビデオカード)を装着した場合にOpenVINOがGPUを呼び出せるかどうかである。なんとなく厳しそうな気もする
アプリケーション例としては、例えばMicrosoft Teamsで利用しているWindows Studio EffectsはOpenVINOをNPUのみで利用、Adobe Creative CloudはDirectMLをGPUで利用、ビデオ分析系はOpenVINOをNPUないしGPUで利用と、アプリケーションごとに使うパスが異なっている。
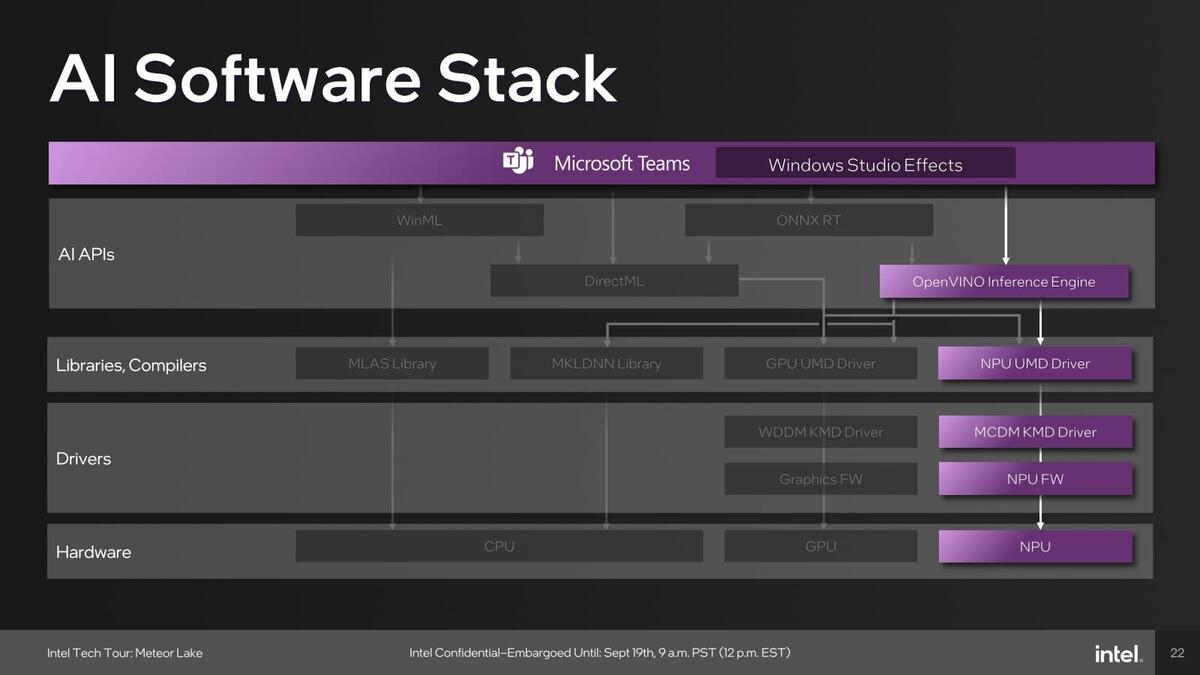
Microsoft TeamsのWindows Studio EffectsはOpenVINOをNPUのみで利用。将来はGPUでも使えるのかもしれないが、少なくとも現状ではNPUのみが利用されるらしい
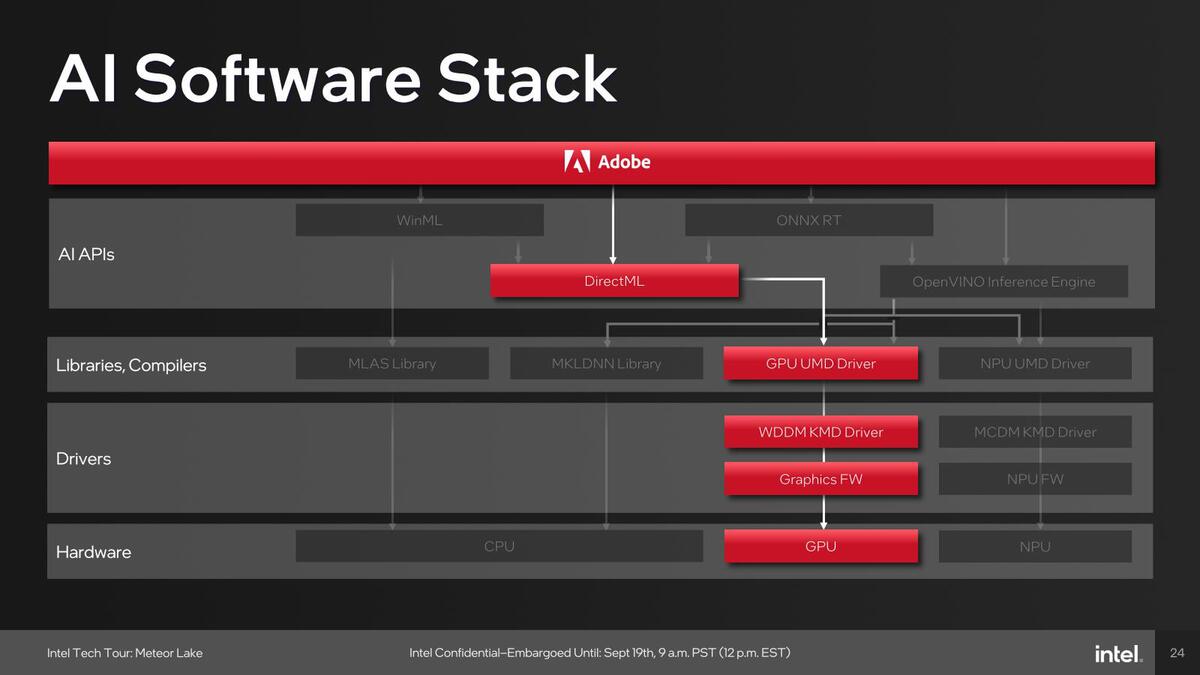
Adobe Creative CloudはDirectMLをGPUで利用。これも将来はNPUで使えるのかもしれないが、後述するベンチマークの結果で見る限りはGPUの方が性能が出そうである
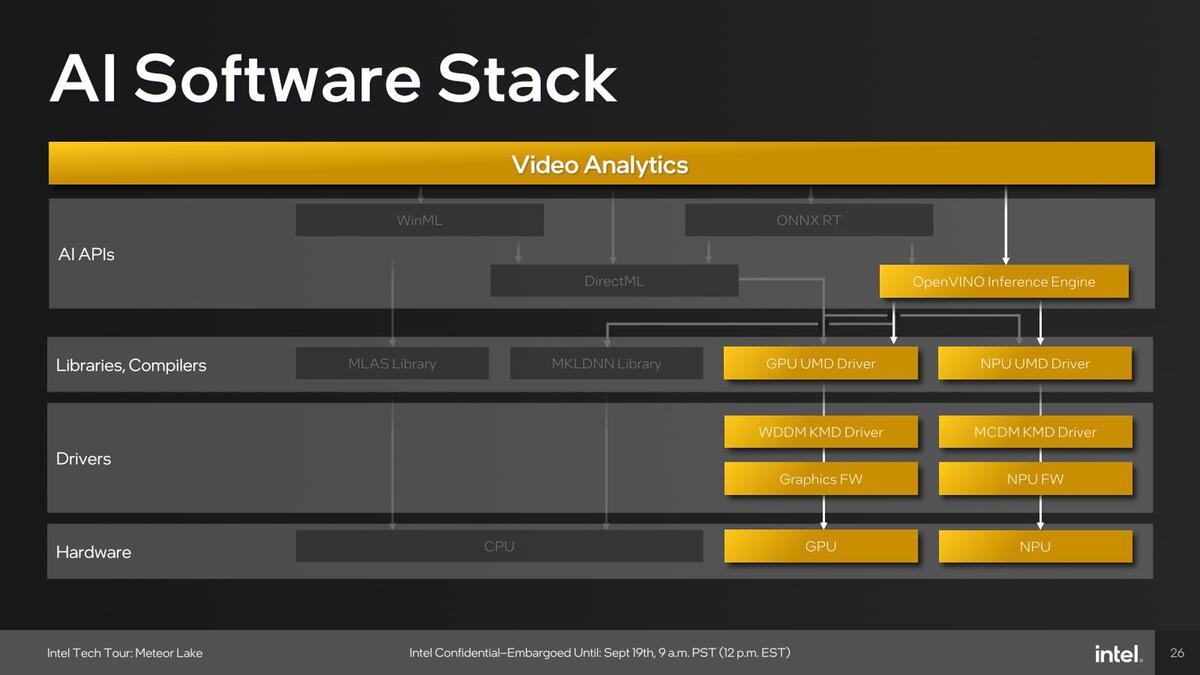
ビデオ分析系はOpenVINOをNPUないしGPUで利用。こちらは具体的なアプリケーション名が示されていないが、おそらく複数のビデオ分析ソフトウェアの構成をまとめたものと思われる
WinMLが全然ないのは、デフォルトCPUでの処理だから遅くて使い物にならないし、GPUなどを使うならDirectMLで十分、というあたりが理由であろう。
そのNPUの性能であるが、Stable Diffusion v1.5を使っての結果が示された。
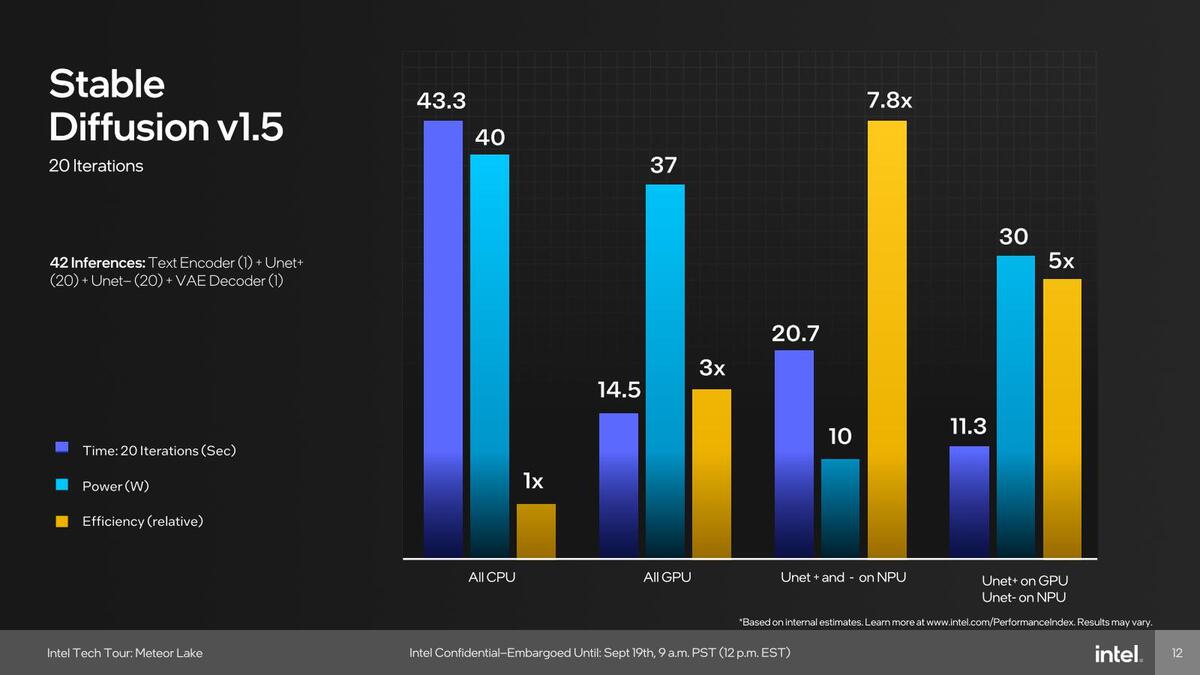
効率は性能/消費電力比=(1÷所要時間)÷消費電力=1÷(所要時間×消費電力)と思われるのだが、この数字をそのまま使うと1:3.23:8.37:5.11となり、傾向は正しいものの微妙にずれがある。おそらくTime/Powerの数字はある程度丸めてあるのだろう
比較は以下の4パターンで、処理性能(というか所要時間)と消費電力、効率を示したものだ。
- すべてCPUで処理
- すべてGPUで処理
- Unet+とUnet-をNPUで処理(その他はCPU)
- Unet+をGPUで、Unet-をNPUで処理(その他はCPU)
おもしろいのは、絶対性能という意味ではGPUとNPUの併用が最高速で、次いでGPUのみとなり、NPUを使った場合はCPUの半分程度の所要時間でしかない。つまりピーク性能そのものはStable Diffusionの結果だけで言えば、NPUの性能はGPUの7割程度に過ぎない計算で、それほど高いものではない。
ただし消費電力はNPUのみの場合が圧倒的に少なく、GPUを使うと相応に増える。要するにNPUは性能/消費電力比を高く取るような構成になっているわけだ。この理由の1つは、NPUがSoCタイルに搭載されていることもあるだろう。
SoCタイルはなるべく省電力になるように構成されており、ピーク性能を追求するような実装にはできない。そうした構成はGPUタイル(TSMC N5)の方が得意である。なので「(ACアダプターをつないだ環境での)性能優先ならGPU、(バッテリー駆動での)性能/消費電力比優先ならNPU」といった使い分けになるものと考えられる。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります