



第740回
Meteor LakeのNPU性能はGPUの7割程度だが消費電力が圧倒的に少ない インテル CPUロードマップ
2023年10月09日 12時00分更新
今回はMeteor LakeのAI周りについて解説しよう。といっても、これまでも何回か紹介している。連載686回で説明したようにMeteor Lakeに搭載されるものは、2022年まではIntel VPUと称しており、Meteor Lakeに先立ちRaptor LakeにはAI M.2モジュールとして提供されてここでアプリケーションの先行開発が行なわれることになっていた。

Meteor LakeとRaptor LakeではAI M.2モジュールを提供してアプリケーションの先行開発が行なわれる
映像処理時のCPU/GPU負荷を下げる
Intel VPU
そのNPUというかVPU、元になったのはインテルが2016年に買収したMovidiusのMyriadシリーズVPUである。もともとMyriadシリーズはVision Processor Unit、つまり映像処理用プロセッサーとして発表されており、2011年には最初のMyriad 1が発表される。
2014年には後継となるMyriad 2がやはり映像処理用のプロセッサーとして発表。ところがその2年後の2016年にはMyriad 2がそのままAIプロセッサーとして再発表され、その直後にインテルに買収された格好だ。このMyriad 2の内部構造は連載566回で紹介している。
さて、インテルの買収後に第3世代製品であるMyriad Xが投入されている。変更点は以下のとおりで、SHAVEエンジンとNeural Compute Engineの組み合わせで1TOPSの推論処理性能を持つとされている。
- SHAVEコアを12基→16基に増量
- CXM Memory Fabricを2MB・400GB/秒→4MB・450GB/秒に大容量化/高速化
- 製造プロセスをTSMC 28nm HPM→TSMC 16nm FFCに微細化
- 外部メモリーI/FをLPDDR2/3→LPDDR4に
- 新たにLEON4(SPARC V8互換プロセッサー)×2を管理用に搭載
- 新たにNeural Compute Engineを搭載
このMyriad XはNeural Compute Stick 2に搭載された他、M.2モジュールの形でも提供されている(いた)。
さらにインテルはこのMyriad Xをベースに、Keem Bayと呼ばれるSoCも開発していた。2019年のIntel AI Summitで発表されたこのKeem Bayは、Myriad X単体の最大10倍の処理性能を実現する(ただし内部構造を変更というよりは、単純にVPUを10個積載する格好である)もので、またArmのCortex-A53を4コア(1.5GHz)搭載し、単体でLinuxが起動するものだった。
今回Meteor Lakeに搭載されたNPUは、Myriad Xのコアをさらに改良したうえで、デュアルで搭載した格好になる。

はっきりとは明示されていないが、2つのNeural Compute Engineにそれぞれ別のネットワークを動かすことも、1つのネットワークを2つに分割して動かすことも可能な模様
まずこの中のMACアレイは畳み込み処理や行列演算などを最大2048 Ops/サイクルで処理可能とされる。MAC処理の場合は2 Ops/サイクル相当になるから、演算性能は4096 OPS/サイクル。仮にこのNPUが1GHzで駆動されたとすると、それだけで8TOPSの処理性能になる勘定だ(MACアレイは2つあるため)。
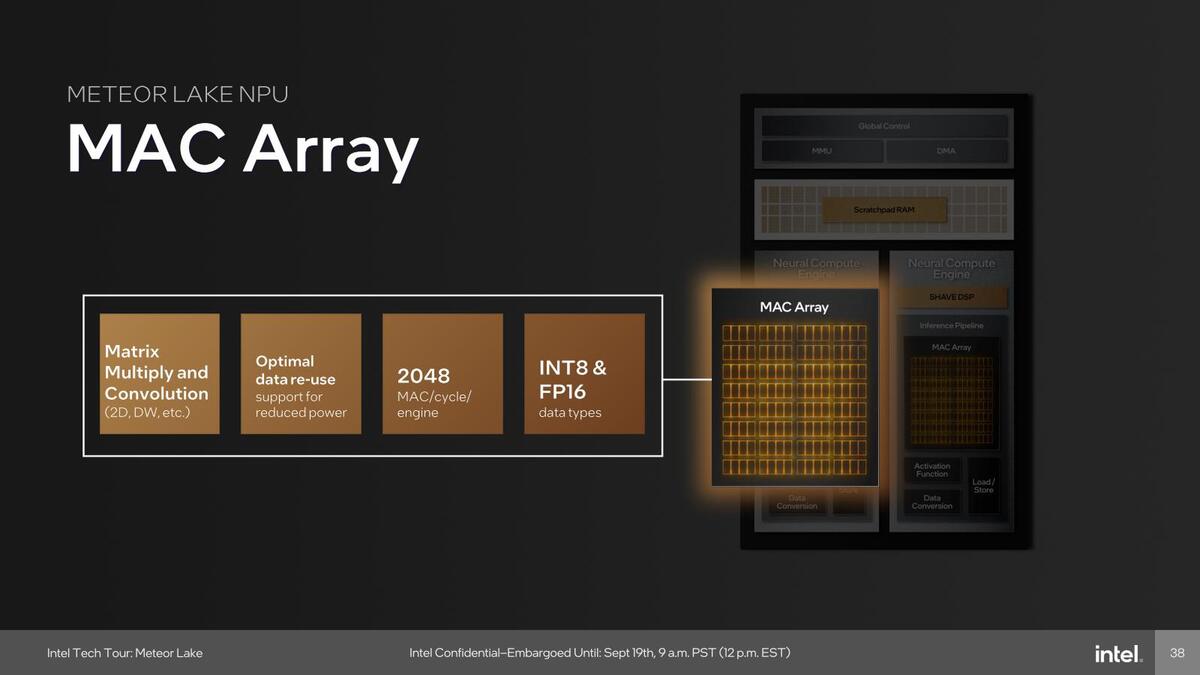
Myriad XではこのMACアレイのことをNeural Compute Engineと称していたわけだが、Meteor LakeではこのMACアレイにSHAVEコアまで含めた全体をNeural Compute Engineと称するようになった
またアクティベーションに関しては、従来はSHAVEコア側で行なっていたが、Meteor Lakeでは専用のユニットが実装されたことで、より高効率化が図られている。

特にFPに関しては複数のアクティベーション関数が提供されるとしている。ただ実際になにが提供されるのかはまだ定かではない
またData Conversion Unitが新たに追加されている。これも従来はSHAVEコアを使って行なっていた処理で、こうしたものをすべて専用ユニットにしたことで通常の畳み込みニューラルネットワークであればSHAVEコアをほぼ利用せずに処理が可能になったと見られる。
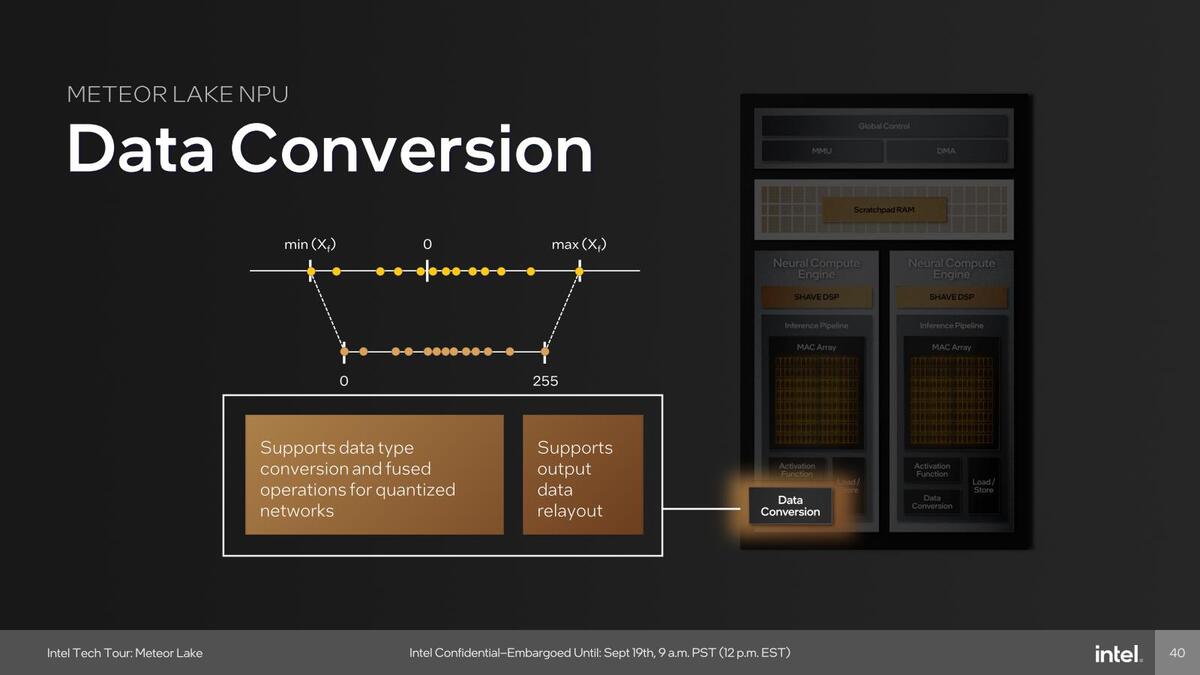
畳み込みの前段階で、データを扱える範囲にとどめるための処理となる
ではSHAVEは省かれたか? というとそんなことはなく、むしろ強化されている。VLIWエンジンそのものはデュアルとなり、されにINT 4などのデータ型にも対応、さらにFP32での演算機能を強化したとしている。

アクティベーション関数はやはり一般的なものに限られるので、特殊なものに関しては引き続きSHAVEコアを使って処理する形になるのだろう
少し意外だったのはMACアレイそのものはINT 1/2/4やFP8/BF16などには未対応なことで、こうしたものはSHAVEコアを利用して処理する形なのは変わらない。つまりMAC アレイはすでにネットワークの構成などが決まっているものを高速に処理することに特化しており、新しく出てくるネトワークはSHAVEコア側で処理する形になる。
これそのものはごく一般的な手法であるが、INT 1/2やFP8はともかくINT 4/BF16あたりまではMACアレイ側でもサポートしていると思ったのだが、このあたりは設計開始時期にも絡んでくるのかもしれない。この第4世代、投入されるのは2023年末であるが、設計開始そのものはMyriad Xが完成した2017年あたりと想像されるためだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります