



画像生成AI「Stable Diffusion XL(SDXL)」の使い方 初めてなら「Fooocus」がオススメです
2023年09月14日 09時00分更新
シンプルなプロンプトを支援する「Style」たち
画面最下部にある「Advanced」にチェックを入れると右側に新たなUIが現れる。より細かい設定ができるようだ。
「Setting」タブ
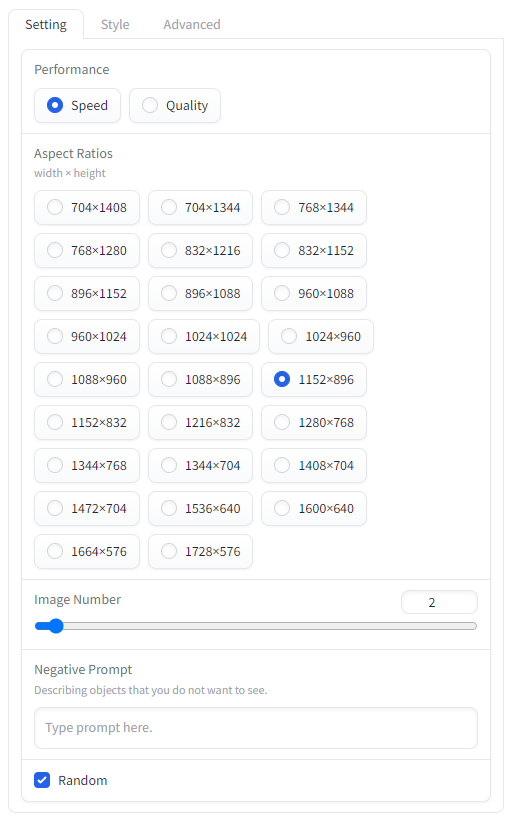
「Setting」タブ
「Setting」タブには基本的な設定項目が並んでいる。
・Performance
「Speed(生成速度)」と「Quality(品質)」のどちらを優先するか選べる。デフォルトは「Speed」だ。
・Aspect Ratios
画像サイズを選択する。デフォルトは「1152×896」
・Image Number
生成する画像の枚数。
・Negative Prompt
ネガティブプロンプトはここに記入。
・Random デフォルトではチェックが入っているが、外すとSeed値を入力できるようになる。
「Style」タブ
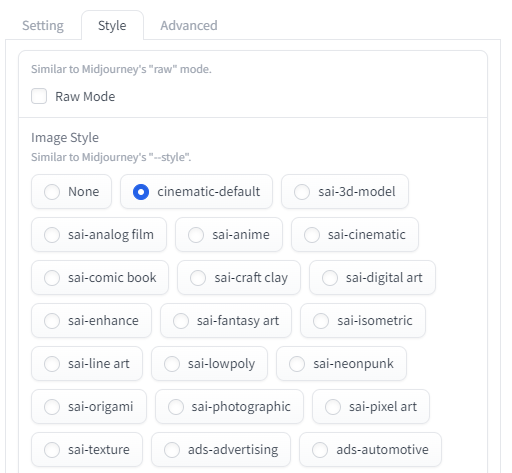
「Style」タブ
Fooocusは、プロンプトの代わりに「Style(スタイル)」を選ぶだけで画風のコントロールができるようになっている。
「Style」タブには「Midjourney」の「Raw Mode」を再現するチェックボックスと、大量に用意された「Style」を選択する画面が表示される。
では「Thai ancient temple and big budha statue」という共通のプロンプト、共通のSEEDでいくつかスタイルを適用してみよう。

「Raw Mode」にチェック
「Raw Mode」にチェックを入れ、スタイルは「None」にした画像がこちら。入力したプロンプトに近い「素」の状態と言える。

「Cinematic-default」
デフォルトスタイルの「Cinematic-default」。光沢や陰影が豪華になっている。

「Rococo」
「Rococo」スタイルは「ロココ調(18世紀のブルボン朝後期におけるフランスの文化・芸術の表現形式)」ということだろう。

「sai-origami」
「sai-origami.pn」は、折り紙アートのようなスタイル。
他にも9月10日現在、およそ180個を越えるスタイルが用意されており、今後もどんどん追加されていきそうな勢いだ。
「Advanced」タブ
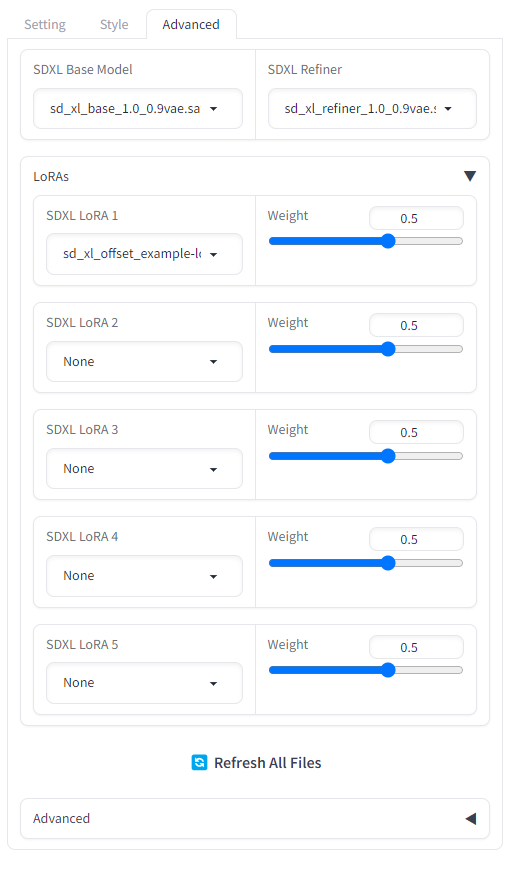
「Advanced」タブ
「Advanced」タブでは、ベースモデル、リファイナーモデル、そしてLoRAを選択できるようになっている。
新たなモデルを追加したい場合は「\models\checkpoints」に、LoRAは「\models\loras」にそれぞれ配置しよう。なお、LoRAはSDXL対応のものが必要になる。
画像のメタデータは無し、情報は「log.html」に
作成した画像は「\outputs\」フォルダー内の「2023-09-10」といった日付の名前のフォルダーに保存される。
通常生成AIが生成した画像には、プロンプトや使用モデルなどがメタデータの形で埋め込まれていることが多いが、Fooocusで生成された画像には、メタデータが埋め込まれていない。
これはFooocusの作者、lllyasviel氏のハッカー的思想から来ている「表現者のプライバシーは守られるべきだ」という考えが根底にあるようだ。(参考)
同じ画像を再現したい場合など詳細を見たい場合は、フォルダー内に自動生成される「log.html」というHTMLファイルを開く。
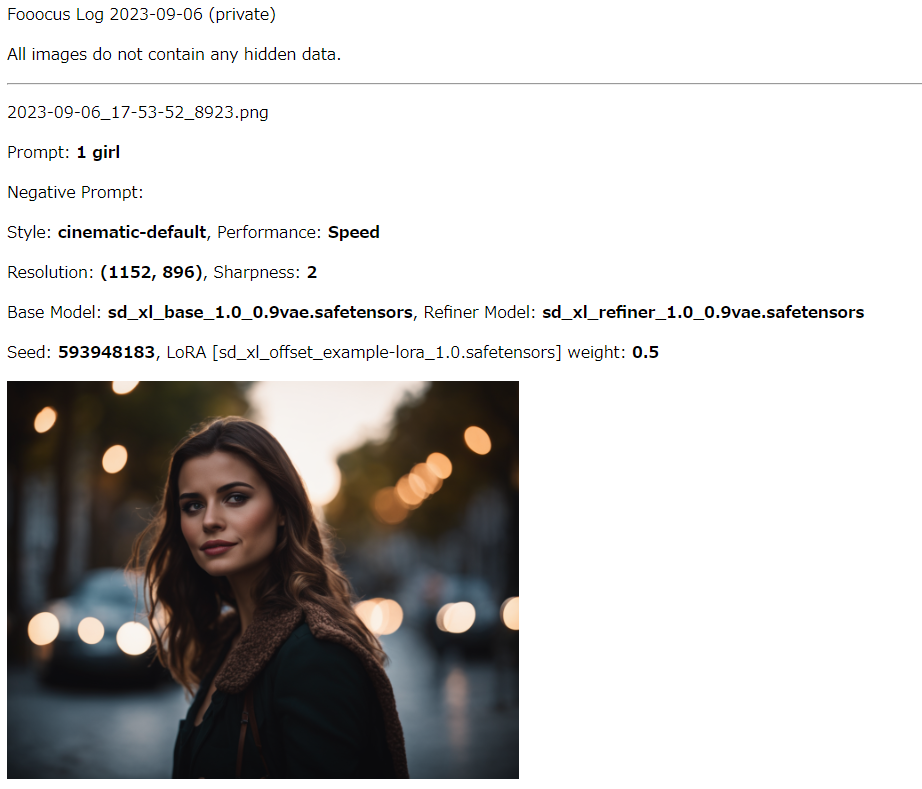
すると、プロンプトや使用モデル、スタイル、画像サイズ、シード値などの各種データが表示される。
まとめ
これまでStable DiffusionのUIとして利用してきたWebUIは、スクリプトはもちろんだが、モデル、VAE、Sampler等の選択、Step数、Clip Skip、CFG Scale、などの各種パラメーターの調整、ControlNetやLoRAを使ったポーズや要素の指定など、とにかく調整できる要素が多く、直感的というよりも、時間をかけて練りに練った設定を最適化し、大量の失敗作の中から究極の1枚を見つけ出し、さらにその1枚を元にアップスケールや「img2img」といった手法を駆使して磨き上げていくというイメージだ。
それはそれで楽しいものの、最初に無料版の「Midjourney」を触ったときの「え?たったこれだけでこんなイラストができるの?」といった驚きとはむしろ反対の方向性に進んでいるようには感じた。

「Fooocus」のコンセプト
今回試したFooocusのreadmeファイル冒頭には、作者lllyasviel氏によるFooocusのコンセプトが書かれている。
そこには、「Stable Diffusionから学んだようにオフラインで使用可能なうえオープンソースで無料」でありながら「Midjourneyから学んだように、手動での微調整が不要で、ユーザーはプロンプトと画像だけに集中すればよい」とある。
初心者にとってのポイントは「(画風はスタイルに任せて)プロンプトと画像だけに集中すればよい」だろう。しばらくはFooocusで改めてプロンプト、ひいては自分が作製したい画像について集中して試してみることにしよう。
次は仏像ではなく美少女を生成するぞ!!!
田口和裕(たぐちかずひろ)

1969年生まれ。ウェブサイト制作会社から2003年に独立。雑誌、書籍、ウェブサイト等を中心に、ソーシャルメディア、クラウドサービス、スマートフォンなどのコンシューマー向け記事や、企業向けアプリケーションの導入事例といったエンタープライズ系記事など、IT全般を対象に幅広く執筆。2019年にはタイのチェンマイに本格移住。
新刊:7月19日発売「ChatGPT快速仕事術」、好評発売中:https://amzn.to/3r6ASOv
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります