



東京大学発・ELYZA、GPT-3.5(text-davinci-003)匹敵、最高水準の日本語LLM
2023年08月31日 12時35分更新

東京大学松尾研究室発のAIスタートアップELYZAは8月29日、メタが開発・公開した大規模言語モデル(以下LLM)「Llama 2」をベースにした、70億パラメータの日本語LLM「ELYZA-japanese-Llama-2-7b」を含む4モデルを開発、商用利用可能な形で一般公開した。
多言語の能力を日本語に引き継ぎ学習量を削減

「ELYZA-japanese-Llama-2-7b-fast-instruct 」のデモ
現在サイバーエージェントやLINEなど複数の企業が日本語LLMの開発に取り組んでいるが、日本語の特殊性、日本語データの不足、計算リソースの不足などの理由でまだ小規模なものにとどまっている。
そこで同社は、英語をはじめとした他の言語で学習されたLLMの能力を日本語に引き継ぎ、日本語の学習量を減らすことで、開発を加速させることができるのではないかと考え、開発を始めた。今回発表となったモデルはその成果の一つだ
4モデルを公開
公開されたモデルは全部で4つ。
メタの「Llama 2」をベースに、OSCAR(フリーの日本語テキストデータセット)やWikipedia等に含まれる日本語テキストデータからなる約180億トークンの日本語による追加事前学習を行なった「ELYZA-japanese-Llama-2-7b」。
そこにELYZA独自の高品質な指示データセットを用いた事後学習を施し、複数ターンの対話にも対応することが可能な「ELYZA-japanese-Llama-2-7b-instruct」、なお、事後学習において、GPT-4やGPT-3.5-turboなどの出力は一切含まれていない。
さらに上記の2モデルに対して、1万3042個の日本語の語彙追加により効率化および高速化を行なった「ELYZA-japanese-Llama-2-7b-fast」と「ELYZA-japanese-Llama-2-7b-fast-instruct」。
4モデルとも70億パラメータのモデルで、公開されている日本語のLLMとしては最大級となる。
ライセンスはメタの「Llama 2 Community License」に準拠しており、ポリシーに従う限り、研究および商業目的での利用が可能になっている。
人力ブラインドテストで最高評価を獲得
ELYZAは日本語LLMの性能評価を人力で行なうための多用なタスクを含む小規模なデータセット「ELYZA Tasks 100」を作成、モデルと同時に一般公開している。
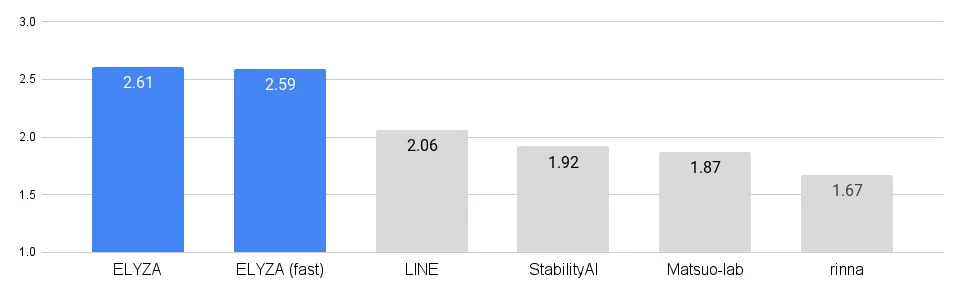
同データセットによる人力評価の結果、他の公開されている日本語モデルと比較して最も高いスコアを獲得している。なお、評価は3人によるモデル名を隠したテストの結果を平均して算出している。
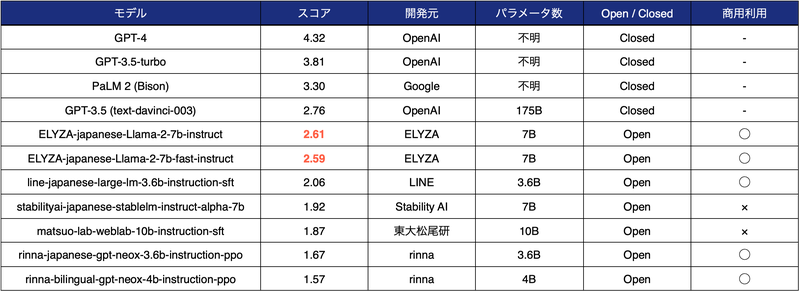
参考までにOpenAIの「GPT-4」や「GPT-3.5-turbo」、グーグルの「PaLM」などのクローズドなLLMと比較するとまだ及ばないものの、一世代前の「GPT-3.5 (text-davinci-003)」に匹敵する性能となっており、日本語の公開モデルのなかでは最高水準と言える。
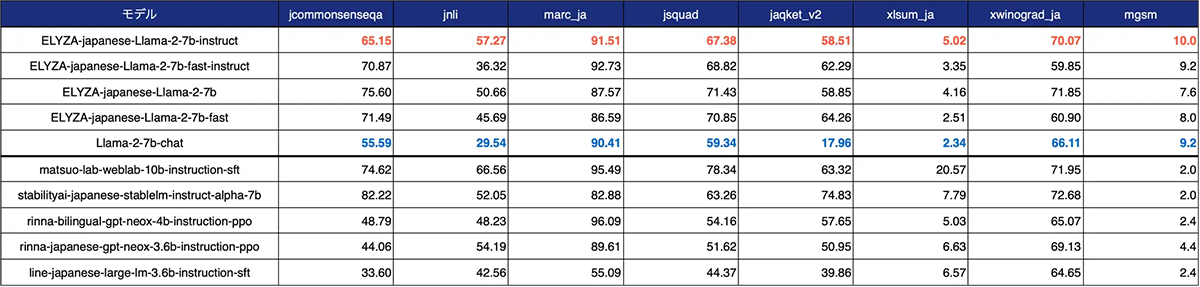
さらに、「lm-evaluation-harness」による評価では、すべての項目においてベースとなった「Llama-2-7b-chat」を上回るスコアを記録している。
さらなる大型モデルも開発中
同社はすでに130億、700億パラメータのモデルの開発にも着手しており、どちらも公開を検討している。今後も「モデルやノウハウの公開を通して、研究室やスタートアップ、個人などでも日本語LLMの研究開発に取り組める土壌を整えることで、日本語LLMの研究を加速させること」を目指すという。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります