



Stability AI、日本語に特化した汎用言語モデル「Japanese StableLM Alpha」を発表
2023年08月10日 17時30分更新

Stability AI Japanは8月10日、70億パラメータの日本語向け汎用言語モデル「Japanese StableLM Base Alpha 7B」および、指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」を一般公開した。
7500億トークンのテキストデータで学習
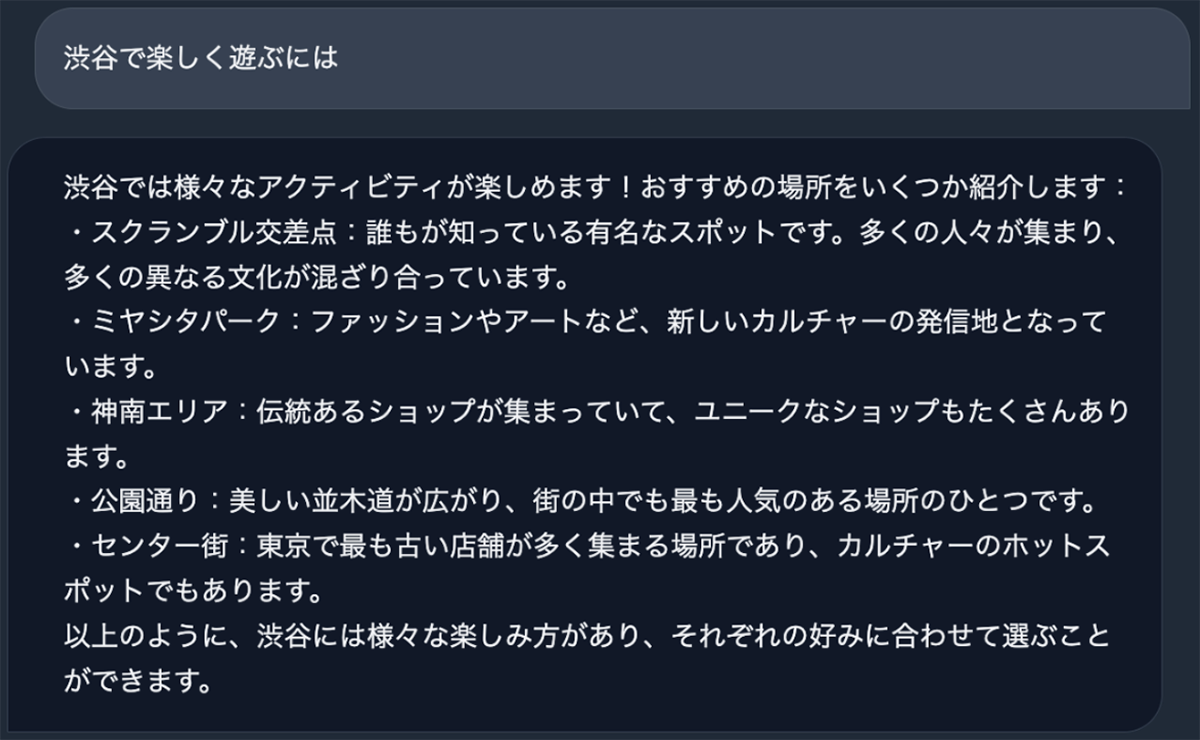
Japanese StableLM Base Alpha 7Bの回答例
・Japanese StableLM Base Alpha 7B:汎用言語モデル
「Japanese StableLM Base Alpha 7B」は、ウェブを中心とした主に日本語と英語の大規模なテキストデータ(内2%はソースコード)のべ7500億トークンを用いてテキスト生成を学習したモデル。
学習データには、公開されているデータセットに加え、Stability AI Japanが作成した独自のデータセットや、EleutherAI Polyglot project の日本語チームおよびStable Community Japanのメンバーの協力のもとで作成したデータが含まれているという。
本日公開されたStability AI Japanの日本語7Bモデル
— Bit192 Labs 【AIのべりすと / Tone Sphere】 (@_bit192) August 10, 2023
「Japanese StableLM Alpha」に
当社から約150GBの独自データセットを提供しました。
今後、国内のオープンソースAIの発展に向けて、Bit192からも様々な取り組みを行っていきます。https://t.co/2Mpsiw3f6b
データ中には、小説生成AI「AIのべりすと」の開発元であるBit192 Labsが提供した約150GBの独自データセットも含まれていることが明らかにされている。
・Japanese StableLM Instruct Alpha 7B:指示応答言語モデル
「Japanese StableLM Instruct Alpha 7B」は上記のモデルに追加学習をし、ユーザーの指示に反応できるようにしたモデル。追加学習にはSupervised Fine-tuning(SFT:教師あり微調整)を採用しており、複数のオープンデータセットを利用している。
両モデルはどちらもHugging Face Hubで公開されており、Japanese StableLM Base Alpha 7Bは商用利用可能なApache License 2.0ライセンスでの公開、Japanese StableLM Instruct Alpha 7Bは研究目的での利用に限定した公開となる。
日本語チャットボットでは最高性能

EleutherAIのlm-evaluation-harnessをベースに、日本語言語理解ベンチマーク(JGLUE)のタスクを中心として、文章分類、文ペア分類、質問応答、文章要約などの合計8タスクで評価をしたところ、Japanese StableLM Instruct Alpha 7Bのスコアは54.71を達成し、他のモデルを大きく引き離している。
日本語に特化した、今までないチャットボット「Stable Chat(日本語版)」を開発します!
— Stability AI 日本公式 (@StabilityAI_JP) February 20, 2023
世界トップクラスの技術、大規模GPUクラスター、オープンコミュニティの力など… 私たちの強みを生かした透明性の高い最高の大規模言語モデル(LLM)を構築します。
1/2
Stability AI Japanは今年の2月に「日本語に特化したチャットボット、Stable Chat(日本語版)を開発する」旨のツイートをしている。
Japanese StableLM Alphaを使用した日本語特化チャットボットの登場も近そうだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります