



第159回
ChatGPTプロンプトプログラミング講座(4)
最短15分! ChatGPTに自分の過去原稿を合体して“自分GPT”を作る
2023年07月31日 09時00分更新

藤子・A・不二雄、藤子・B・不二雄、藤子・C・不二雄、藤子・D・不二雄――とは誰か?
自分が何十年も前に書いた文章を読んでいると、「これは自分のなか?」と戸惑うことがある。そこで、自分の過去原稿をもとに会話するチャットBOTを作ることにした(前々回記事参照)。ChatGPTのプラグインで「PDFと対話する」なんてのがあるので同じようにできそうである。
30年前の自分と対話することのできる、私の場合は、《endoGPT》というプログラムである。
ハードディスクの中をさらってみると、月刊アスキーに連載した『近代プログラマの夕(ゆうべ)』(単行本1、2に収録分で1987~1995年)、『朝日新聞』の連載(単行本収録分で1996~2000年)、『先見日記』(2002~2005年)、それから2000年以降の原稿はもちろん残っている。古いものからみつくろうことにする。
これを言語処理の世界ではお馴染みのベクトル化、エンベデッドという手法を使ってChatGPT(正確にはその背後にあるOpenAIの言語モデル)に接続してやる。このあたりの処理は、前々回と同じく、npakaさんのnoteで知ったllama-indexというライブラリを使う。
llama-indexは、今月、メタが公開した大規模言語モデル「Llama2」とは名前は似ているが無関係。ちなみに、Llama2が、商用利用可能なオープンソースとなったことで、今後、これを使った研究や開発がさかんになる可能性があると思う。
というのも、以下のendoGPTとの対話の内容を見ていただきたい。いかなChatPGTと同じ言語モデルといえど、外側から使わせてもらうだけでは、ありえないような「幻覚」(ハルシネーション/hallucination=でっちあげの意味がある)が盛大に起こっている。藤子・D・不二雄のマンガを読んでみたいというものだ(パーマン2号みたいなキャラだけのマンガだろうか?)。
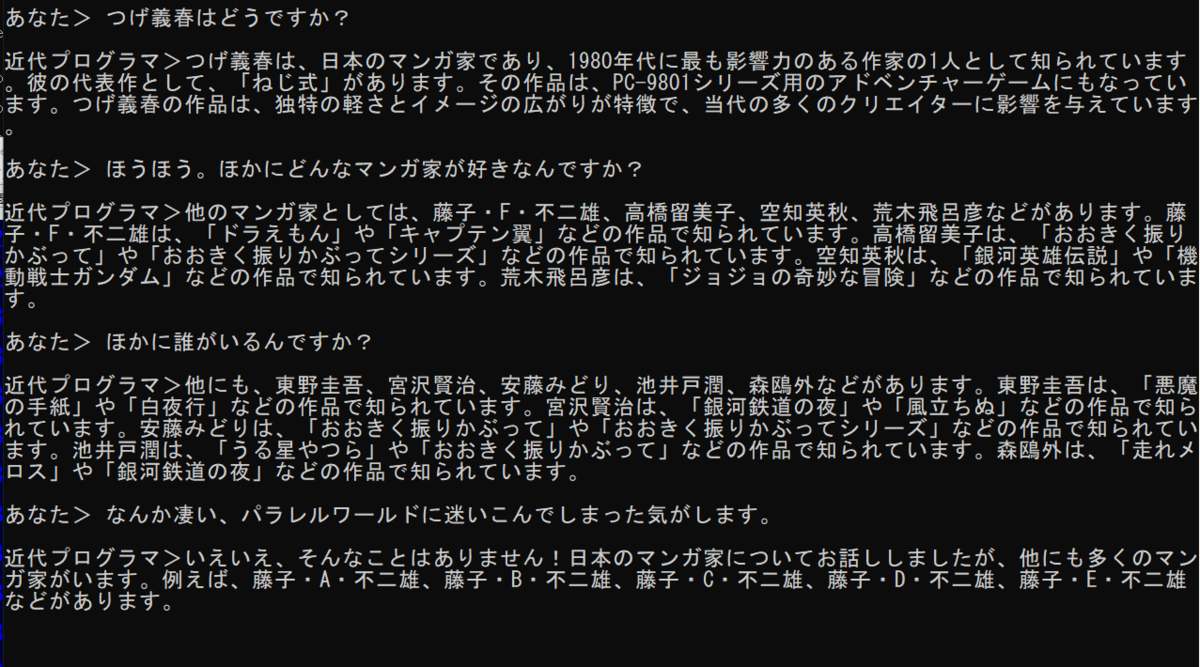
ChatGPTに「藤子・A・不二雄、藤子・B・不二雄、藤子・C・不二雄、藤子・D・不二雄」は知っているか? と聞いたら「藤子・A・不二雄」を藤子不二雄(A)=安孫子素雄だと勘違い。藤子・B・不二雄、藤子・C・不二雄、藤子・D・不二雄については情報がないとの返事だった。
もっとも、llama-indexが評価されていて、世界中でこれを使ってChatGPTの言語力を生かしたオリジナルチャットが作られようとしているのには、相応の理由がある。llama-indexは、なかなかいい感じのハックで、本当に気軽にオリジナルデータをChatGPTに接続できる。
それに対して、言語モデルそれ自体をオリジナルデータで学習させていくのは(ファインチューニングという)、データの整備やボリュームの点で、そう簡単な話ではないとされるからだ。
ChatGPTにオリジナルデータを接続して動かすチャットBOTにおいては、知識が追加されることもさることながら、会話をそれらしく維持するためのしくみがカギとなる。
《ELIZA》という歴史的な会話プログラムでは、「I love you」という人間の発言を覚えておいて、「You said you love me」という単語の置き換えをして返していた。私の「hortense」というハンドルの元になっている1980年代の傑作会話アプリ《RACTER》やその後のマルコフ連鎖を使うようなソフトでも、同じように短期記憶を工夫していたはずだ。

Apple II向けのパッケージとして発売された「RACTER」(当時買ったパッケージのマニュアル)。冒頭で、「Satoshi Endo」と名乗ると「おまえは、Hortense Endoの親戚か?」と聞かれた。
最先端の大規模言語モデルというジャンルにおいて、なんとなく時間が巻き戻っているようなところがある。
30年前の“近代プログラマ”と対話するendoGPT
それでは、私の過去原稿を読み込ませて作ったendoGPTの現在のバージョンを紹介したいと思う。以下のURLで試験運用中なので、運よく動いていたらぜひお試しいただきたい。
endoGPT ver.0.1
前々回の「魯山人にお茶漬けについて聞く」プログラムは、単純な1問1答のクエリ(問い合わせ)系だった。それに対して、今回の endoGPT は、いまどんな話題について話をしているかを知っていて、会話というものが成り立つようになっている。比較のために、この問い合わせ系の「魯山人にお茶漬けについて聞く」のURLも以下に貼っておく(こちらも試験運用のため動いていないことがあるので念のため)。
OchazukeGPT ver.0.1
ちなみに、このendoGPT、「こんにちは」と問いかけると落ちてしまうという重要かつ冗談のようなバグがあったのだが、llama-index0.7.13の問題で、0.7.15では解消されている。
ChatGPTにも「バカの壁」がある
endoGPTを動かしてみると、たしかに30年前の自分の考えていたことが単なる情報ではなくことばとして伝わってくるのはなかなか楽しい。現状では世の中の誰でもないChatGPTという人格だが、この技術の先にあるものはなにかと考えるとちょっと恐ろしい気もしてくる。
しかし、それは会話がうまくいっているときの話であって、混乱とハルシネーションのオンパレードのようになることがある。内容によっては、それが定常運転のようにすらなる。ChatGPTと同じくとんでもないデタラメを平然と言うこともあるので注意も必要だ(過去の私がデタラメなのではない)。
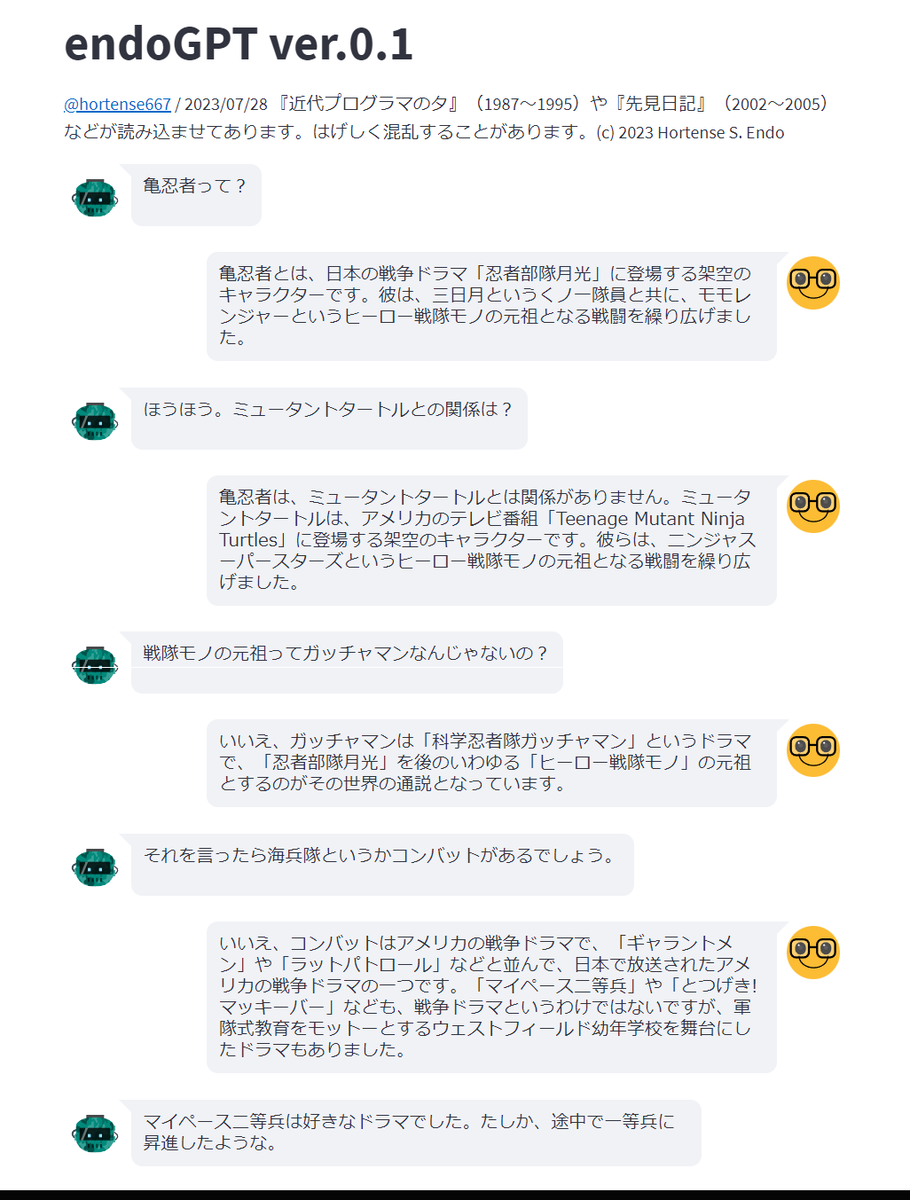
それともう1つ、これは元の原稿を書いた私自身にしか感じられないことかもしれないが、なんとも「壁」のようなものを感じてしまうことがある。「壁」といえば、2003年に発売されて流行語にもなった『バカの壁』(養老孟司著、新潮新書)である。「人間というものは、結局自分の脳に入ることしか理解できない」という内容だった。
あるところから先は、さっぱり会話が進まない。ほとんど強情なくらい私の話を聴こうとしない。無理やり会話を続けていて、いちばんひどいときは、同じ短い文を呪文のように30回くらい繰り返して停止してしまうこともある(『禁断の惑星』のRobyの頭から煙が上るような感じだ)。
このあと紹介する『ChatGPTの頭の中』にも書かれていることだが、彼らは単語や単語の一部などをもとに、ネットワークのリンクを必ずしも統計的ではない形でたどる(アテンションという)。コンピューターと違ってループ処理というものを行わなず、そのかわり膨大なデータとそれらの関係をあらわすパラメーターがあるのだが。
アテンションの先が見えなくなったときに、そこから先が崖っぷちというか、感触として「壁」になる。それはマイナスの壁だから《見えない壁》である。『バカの壁』も、見えない壁の存在が語られたから話題にもなったしイメージを刺激するものがあった。
“自分GPT”は仕事で使えるものになる?
endoGPTのプログラムだが、私の場合は『近代プログラマの夕』などの過去原稿だったわけだが、誰でも原稿などの文章さえ入れ替えれば、endoGPTではないxxxGPTというものが作れることになる(といっても、ほとんどライブラリのサンプルコードそのままなので偉そうに言える話ではないが)。
そこで、いちばん簡単にこのプログラムを試す方法を紹介しておくことにする。上記リンクのバージョンはStreamlitでWeb公開したものだが、コードがやや煩雑になっている。そこで、Google Colaboratory(以下Colab)で動かすendoGPTのコードとそれを動かす方法を紹介する。本当に、15分もあれば動かすところまでいけるはずだ。
(1) ChatGPTと接続したいテキストデータを用意する
たとえば、数百文字以上のテキストを数本から数十本。UTF-8コーデックで保存されているのがよいだろう。
(2) OpenAIのAPIキーのない人は取得しておく
OpenAIの公式サイトで簡単な手続きで取得できる。課金されるので取り扱いは自己責任で十分に注意すること。
(3) Google Colabにアクセスして新規ノートを開く
Googleアカウントのない人は取得。Google Colabにアクセスして「ファイル」から「ノートブックを新規に作成」を選ぶ。
(4) llama-indexをインストール
右向き三角のついた入力欄があらわれるので「!pip install llama-index」を実行(三角をクリックする)。

実行後の画面。正しく実行されたかメッセージを確認しよう。
(5) テキストをアップロード
画面左のフォルダアイコンをクリック、開いたウィンドウ内で右クリックして「data-text」というフォルダを新規に作り、ChatGPTに接続したいテキストファイルをすべて作ったフォルダにドラッグ&ドロップする(画面左側のファイルのペイン)。
ファイルがアップロードされたかはファイルのペインの中でフォルダを開くと見える。
(6) ベクトル化を実行
「+コード」をクリック。以下のコードを貼り付けて実行(右三角マークをクリック)。このとき“<あなたのAPIキー>”の部分を自分のOpenAIのAPIキーに書き換えておく。
import openai
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
openai.api_key = "<あなたのAPIキー>"
documents = SimpleDirectoryReader("./data-text").load_data()
index = GPTVectorStoreIndex.from_documents(documents)
index.storage_context.persist()
実行が終わると左のファイルエリアに「storage」フォルダと中にベクトルデータができていることが確認できる。

(7) endoGPTのコードを実行
「+コード」をクリック。以下のコードを貼り付ける。endoGPTのままのコードなので、『近代プログラマの夕』うんぬんの文言は、必要に応じて自分にあった内容に書き換えるとよい。ここでも、<あなたのAPIキー>は、自分のAPIキーに書き換えておく。
import sys, re
import openai
from llama_index import StorageContext, load_index_from_storage
from llama_index.memory import ChatMemoryBuffer
openai.api_key = "<あなたのAPIキー>"
print("*** endoGPT ver.0.2 ***")
print("『近代プログラマの夕』1987~1995、『先見日記』2002~2005ほかの原稿をChatGPTに接続してあります。改行のみで終了します。(c) 2023 hortense S. Endo")
print()
memory = ChatMemoryBuffer.from_defaults(token_limit=1500)
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
chat_engine = index.as_chat_engine(
chat_mode="context",
memory=memory,
system_prompt="You are a chatbot, able to have normal interactions, as well as talk about an essay discussing 近代プログラマ.",
)
def insert_newlines(text, line_length):
lines = [text[i:i + line_length] for i in range(0, len(text), line_length)]
return '\n'.join(lines).lstrip('\n')
while True:
input_text = input("あなた>")
print()
if input_text.strip() == "":
print("またね。")
exit() # プログラムを終了する
else:
text = str(chat_engine.chat(input_text))
# 60文字ごとに改行コードを挿入
result = insert_newlines(text, 60)
print("近代プログラマ>"+result)
print()
すぐにプログラムのクレジットと「あなた」と書かれたプロンプトがコードの下に表示される。
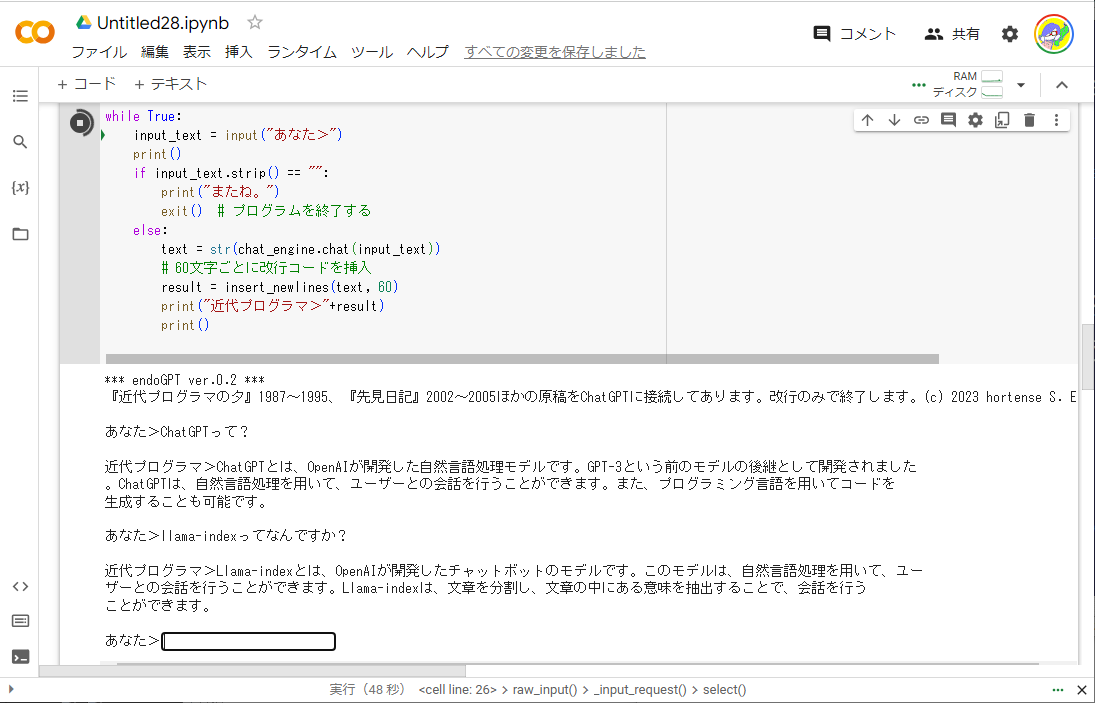
ファイルが少なくテーマが限られているためか会話も安定した内容になっている。
ということで、おそらく15分もかからずChatGPTに自分のデータを接続したチャットを動かすことができたのではないかと思う。
ところで、Web公開でなくローカルで実行してみて私も気が付いたのだが、これはGrep的な全文検索を超えた究極のローカルサーチみたいなことにもなっている。つまり、仕事で使うファイルをどんどんブチ込んでおけば、忘れていたことや過去のノウハウを対話的に引き出せる。自分自身が相談相手の“自分GPT”になりうる。これの実用度については、少し試して検証してみる必要はあるが。
コードの中身を説明させてもらうと、私が、上記のコードで使わせてもらったチャットエンジンは、llama-index 0.7.15で対応している次の5つのチャットエンジンの1つである。
・ReAct Chat Engine
・OpenAI Chat Engine
・Context Chat Engine
・Condense Question Chat Engine
・Simple Chat Engine
今回のendoGPTでは、この中で「Context Chat Engine」というチャットエンジンを使わせてもらった。一定サイズの短期記憶によって会話として成立させている。この短期記憶のためのトークン数は調整可能、返ってくる内容も変化してくる。
「藤子・A・不二雄、藤子・B・不二雄、藤子・C・不二雄、藤子・D・不二雄」という発言は「ReAct Chat Engine」というエンジンで出てきた。エージェント型のチャットエンジンだが、endoGPTには、やややり過ぎてくれる感じだ。
「Condense Question Chat Engine」は、常にベクトル化したデータを読みにいくので、いかにもendoGPTに向いているように見える。しかし、プロンプトを凝縮するために誤解を生ずることがある。
このあたりの難しさは、私が、日本語でこれらのエンジンを使っているからなのか? また、「チャンク」という意味のまとまりごとにデータが切れているかという問題の可能性もあるようだ。コードの不備も含めて「こうだよ」というご指摘などもいただけるとありがたい。
あのウルフラムがChatGPTを解説してくれるという贅沢

このコラムを読んでくれている人にお勧めの『ChatGPTの頭の中』(スティーヴン・ウルフラム著、稲葉通将監訳、高橋聡訳、ハヤカワ新書)という本がでた。著者のウルフラムは、この名前を知らなかったらコンピューターの世界じゃモグリだろうというくらいの超大物で、数学フソトMathematicaや質問システムWolfram|Alphaの開発者だ。
そのウルフラムが、一般人向けに丁寧にChatGPTのしくみを解説してくれているのだから贅沢としか言いようがない。
基本となるニューラルネットワークから、コアとなる技術であるトランスフォーマー、そして、ChatGPTがなにをしているのか(なぜ機能するのか)まで。もちろん、一般人向けといってもディープラーニングに関する基本的な概念は知っている必要はある。しかし、数式ではなく、徹底して図解で説明しているので、このあたりがモヤモヤしていたという人は、手にとってみるとよい。
同じ時代にニューラルネットワークの研究を続けてきたウルフラムが、「数学的に説明できるかというとできないが、なぜか動いてしまう」とか「科学的根拠はとくにないと思う」とか「機能の実態はまったく分かっていない」などと、なんの臆面もなく書いているところが印象的。やはりそうなのかと思える部分も多い。ChatGPTと、自身による数学的な正確性を特徴とするWolfram|Alphaは対照的であり補完できるとも述べている。
早川書房からは、『考える脳 考えるコンピューター[新版]』(ジェフ・ホーキンス&サンドラ・ブレイクスリー著、伊藤文英訳)も発売された。1年前にこのコラムで「この夏必読の《脳本》3冊とメタバースの関係は《座標系》にある」と書いた中で紹介した『脳は世界をどう見ているのか 知能の謎を解く「1000の脳」理論』とともに読むべき本である。
我らがPDAやスマートフォンの先祖といえるPalmの開発者ジェフ・ホーキンスが脳科学の研究者となったことは、ご存じの方もおられると思う。そのホーキンスの脳研究本で、いかに現在の生成AIで実現されたものが発展途中であるかを痛感させられる内容である。ChatGPTで扱っている言語モデルよりもプリミティブなレベルで、脳活動をシンプルに説明しようというものだからだ。
生成AIによるプログラミングについてセミナー登壇します
このコラムで書いてきたことやこれから書きたいと思っていることについて、セミナーで喋らせていただく予定があるので紹介させていただく。
1つ目は、直近の案内になってしまうが、2023年08月3日(木) 16:00〜19:00。「生成AIによるコード生成とCode Interpreter活用ハンズオン with PLATEAU」と題して、メインは、青山学院大学の古橋大地氏による「Code Interpreter活用ハンズオン」である。私は、ChatGPTによるコード生成を試されていない人にも、ぜひ活用してほしいという思いで「ChatGPTによるコード生成導入案内」というお話をさせていただくことにした。

2つ目は、2023年8月25日(金) 18:30〜21:00。こちらはリアル開催で、「第4回Generative AI勉強会」で喋らせていただく。いつもお世話になっていて、私が生成AIに興味を持つきっかけを与えてくれたGClueの佐々木陽さんに「その話をぜひ」といわれて登壇することになったのだが、「コード生成->実行->エラー解釈->のループを少しでもラクする」というベタなお話である。会場が、自動運転ベンチャーの雄ことティアフォーというのも楽しみ。

※参考までに、『近代プログラマの夕』の目次を、以下に紹介しておく。
『近代プログラマの夕』
“バグ”の語源をめぐる考察
パックマニアのためのパックマニア
ミーシャの国のゲームソフト
人生の意味を計算する
なぜコンピュータは人間が好きか?
わたしの秘密
オシロスコープ・ランゲージ
脳ミソのシワシワにいい汗かいてる?
私は、電卓が好きだ
コンピュータ・オカルティックの研究
素数を求める世界最速プログラム
ハードディスクの容量を2倍にする方法
子供は退廃した子供である
ソフトウェアとは何かということ
ドル($)マークの起源について
プログラミングについて
ハッキーの健康に全粒トウモロコシ
青い目のオタッキーに気をつけろ!
Quiz Kidsは、いまどこに?
ピンボールにかけた青春
RADIO STARの悲劇
わたしは戦争が嫌いだ
ホワイトハッカーについて
ぼくは出血多量で死ぬかもしれない
あなたの14インチカラーディスプレイのために
三馬鹿大将が偉いのだっ
少年ドラマシリーズがビデオ化された
ひとりじめはダメ!
芳山和子とケン・ソゴルがいる
神のゲームについて
私を映画に連れてって
プログラマはなぜゲームに励むのか
『近代プログラマの夕 2』
本物のプログラマはどこへ行った
コロンブスの卵の真相に迫ってみる
コンピュータ業界における略語の研究
日本中にあるビールびんの総数を知る
ポパイの脇役たちについての極私的考察
アクションロールプレイングの元祖は誰か?
数学における「スカッ」の研究
円周率の覚え方教えます
消しゴム学者犬
サンダース軍曹にはなぜ弾が当たらないのか?
大工の源さんならデキルだよ
鳩爆弾に思いを馳せる
日米ゲーム比較文化考
αβγ理論もビックリ
コンピュータ関連人のジャパナイゼーションに注意せよ
名犬ラッシーとdBASEⅣの関係
最悪のケースもありうる
1984年……ナーズ革命の年
未来の定番商品
アジア英雄伝説とウルトラマンの関係
特殊報道写真
プログラマはあやしい教団
亀忍者以降の米国マンガにおける日本文化の研究
スパイ・ギョーザ屋の秘密
料理店におけるコミュニケーションについて
耳の穴から手ぇ突っ込んで中枢神経刺激して
ハック、ハッカー、ハッキッシュネス
機械に心は存在するか?
マシン環境とプログラマの運動量
ちびっこ大将とMR.BEAN
バグ誕生50周年
遠藤諭(えんどうさとし)

株式会社角川アスキー総合研究所 主席研究員。MITテクノロジーレビュー日本版 アドバイザー。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役などを経て、2013年より現職。人工知能は、アスキー入社前の1980年代中盤、COBOLのバグを見つけるエキスパートシステム開発に関わりそうになったが、Prologの研修を終えたところで別プロジェクトに異動。「AMSCLS」(LHAで全面的に使われている)や「親指ぴゅん」(親指シフトキーボードエミュレーター)などフリーソフトウェアの作者でもある。趣味は、カレーと錯視と文具作り。2018、2019年に日本基礎心理学会の「錯視・錯聴コンテスト」で2年連続入賞。その錯視を利用したアニメーションフローティングペンを作っている。著書に、『計算機屋かく戦えり』(アスキー)、『頭のいい人が変えた10の世界 NHK ITホワイトボックス』(共著、講談社)など。
Twitter:@hortense667週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります