




Stability AIとCarperAIラボは7月21日(現地時間)、大規模言語モデル「FreeWilly1」および「FreeWilly2」を非商用ライセンスのもと公開した。前者はメタの「Llama」、後者は「Llama 2」というオープンソースのLLMをベースに開発された。
訓練にはマイクロソフトの「Orca Method」を使用
FreeWilly1は、オリジナルの「LlaMA 65B」ベースモデルを、FreeWilly2は「LlaMA 2 70B」ベースモデルを活用し、新しい合成データセットを標準的なAlpaca形式のSFT(教師あり学習による微調整)で微調整されている。
本モデルのトレーニング方法は、マイクロソフトが論文で発表した「Orca Method」に影響されている。この方法は、小さな言語モデルに大きな言語モデル(この研究ではGPT-4)のステップバイステップ推論プロセスを学習させることで、モデルの能力とスキルを改善させるものだ。
FreeWillyは60万点(Orca論文のわずか10分の1)という少ないデータセットで訓練されたにもかかわらず両モデルとも様々なベンチマークにおいて卓越した推論能力を発揮したという。
各種ベンチマークで好成績

一部の項目ではChatGPTを凌駕
この表は、Stability AIの研究者による評価と、AIや機械学習のコミュニティで知られる「Hugging Face」が運営するオープンソースLLMの性能ランキング「Open LLM Leaderboard」の結果をあわせたものだ。
FreeWilly2は、「HellaSwag」というAIが物語の続きを予測する能力を競う指標でChatGPTのスコアを超えている。
最下段の「llama-30b-instruct-2048」というモデルは、韓国のAIスタートアップ「Upstage AI」がLlamaをベースに作成したものであり、7月18日に発表されたばかりのLlaMA 2のスコアを初めて上回ったことで話題になった。

Open LLM Leaderboard(Hugging Face)
Hugging Faceのランキングを見ると、FreeWilly、FreeWilly2共に多くの指標でLlaMA 2のスコアを上回っていることがわかる。
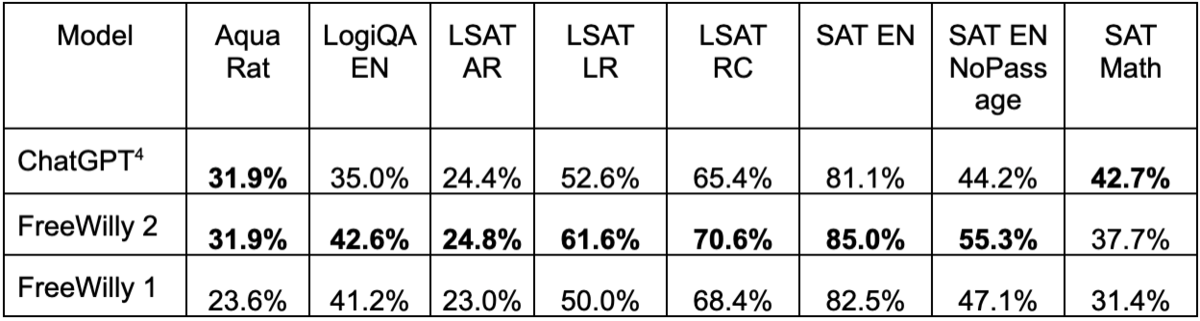
AGI Eval
また、「AGIEval」というベンチマークでは論理的推論能力を評価する「LogiQA(英語)」やアメリカの法学部入試テスト「LSAT」、大学進学用テスト「SAT」などの各項目でChatGPTの能力を上回っている。(ただし数学テストだけは大きく下回っている)。
Stability AIはFreeWillyについて、責任あるリリースに重点を置いていることを強調。社内のレッドチームがテストを実施したうえ、外部からのフィードバックを促している。
軽量かつ非商用利用が可能な高性能LLMはバジェットが限られている研究者にとって福音となるだろうか。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります