



電気を利用せずに光信号のままイーサネットをスイッチングできる
さて、先程4096個のTPU v4を3Dトーラス構造で接続すると説明したが、これは厳密には正しくない。実際のTPU v4 Podは、64個のTPU v4を4×4×4の3Dトーラスで構成し(これをCubeと呼ぶ)、このCube同士をさらに4×4×4の3Dトーラス構成としてつなぐ、という構成である。
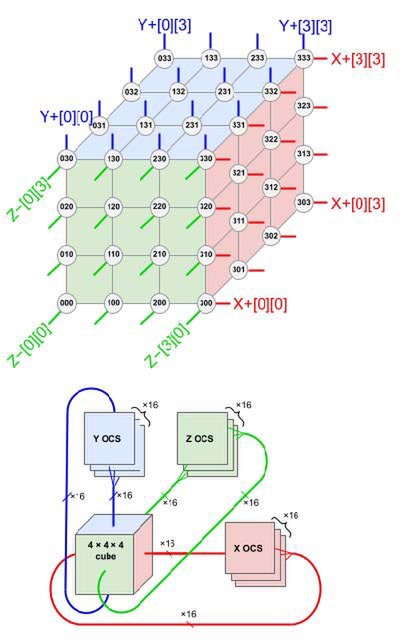
上がCubeの中身、下がCube同士の接続方法である
このCube同士の接続にはイーサネットのスイッチを介することになるのだが、このスイッチであるPalomar OCS(Optical circuit switches)は、なんと電気を利用せずに光信号のままMEMSミラーを利用する構成になっている。
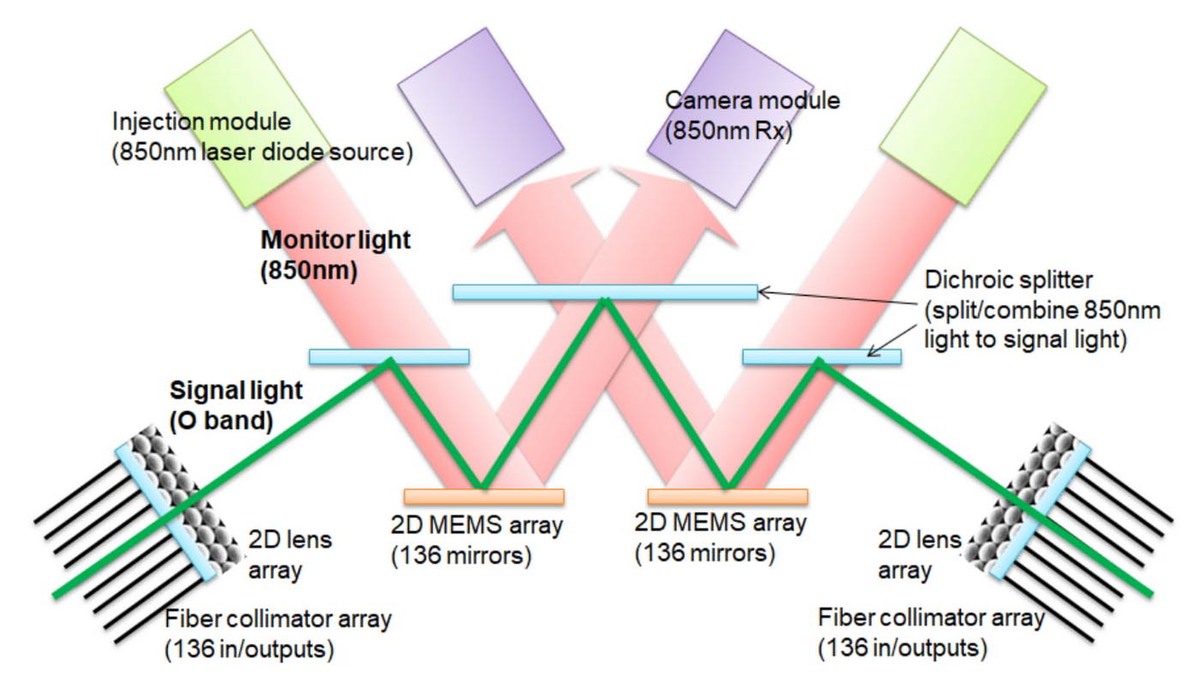
入出力の波長はO Band(1260~1360nm)ということで、実際には1310nmあたりを使う100GBASE-FR1あたりが利用されているのだろうか? ちなみに136ポートのうち8ポートはスペアやメンテナンス用とのこと
通常、イーサネットのスイッチというのは光信号入力→光/電気変換→電気信号ベースでスイッチ→電気/光変換→光信号出力という形で実装されている。これに対しPalomar OCSは2つのMEMSミラーを利用してスイッチを行なう、つまり光/電気変換や電気/光変換をせずにスイッチングを行なう仕組みである。
GoogleによればこのPalomar OCSの価格はTPU v4 Pod全体の5%未満、消費電力は3%未満とされ、InfiniBandに比べてはるかに安く、低消費電力を実現できている。実際高速なスイッチの場合、スイッチチップそのものの消費電力だけでなく光/電気の双方向変換に結構な消費電力を費やしているから、MEMSミラーの駆動だけで済むPalomar OCSは非常に優秀と言える。
もっともその分、2つのMEMSミラーと3つのハーフミラー(このハーフミラーは、MEMSミラーの制御や確認のために利用する850nm帯のレーザーを通し、それ以外は反射する)を通るから、それなりに信号が減衰する。短距離用のxBASE-SRではなく、中長距離用(つまりもともとの光信号の強度が高い)のxBASE-FRもしくはxBASE-LRを前提にしているのは、Palomar OCSの損失が少なくない可能性が高い(*1)。
ところでこのPalomar OCS、パケットの中身を見て切り替える機能はない(そもそも入力パケットの中身を判断する機能がない)。Palomar OCSは事前プログラミング方式で、稼働させるニューラルネットワークに合わせてトポロジーを変更する用途であり、一応ミリ秒単位で構成の変更は可能であるが、動的に切り替えるという用途には適さない。
ただ、特に大規模のニューラルネットワークで動的に構成を切り替えるという使い方はあまりない(同時に複数のネットワークを稼働させる、などではまた別だが)ことを考えれば、レイテンシーと消費電力・コストを抑える良い仕組みと言える。
このTPU v4の性能、Googleによれば例えばレコメンデーションではTPU v3の3倍、CPUの10倍の性能であるとしており、MLPerf Training 2.0での結果ではNVIDIAのA100ベースのシステムと比較して最大1.87倍高速で、消費電力は最大1.93倍少ないと主張している。
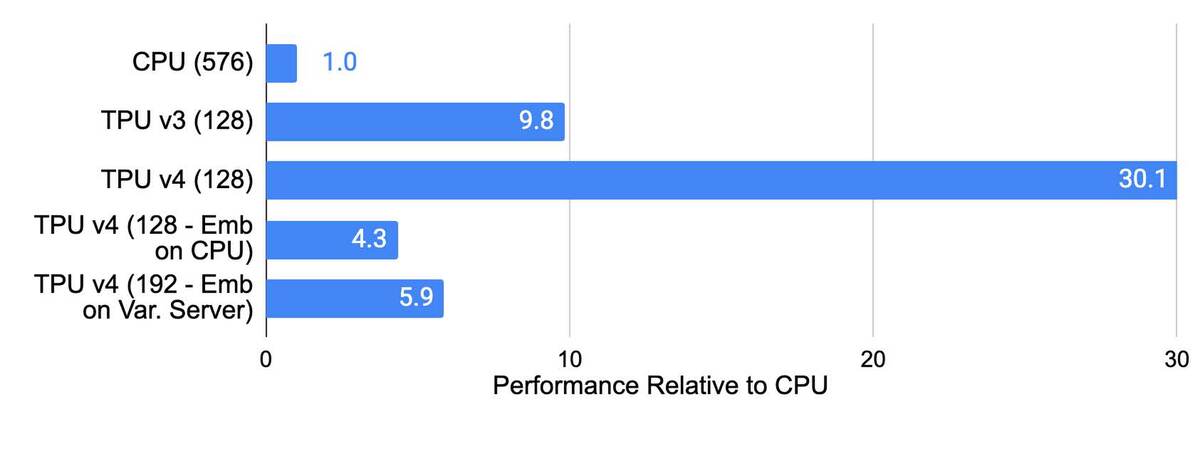
()内の数字はコア数。576コアのCPUだけで稼働させた場合が1.0である。Emb on CPUというのはEmbedding(自然言語を計算可能な形に変換すること)をCPU側で行なった場合を指す
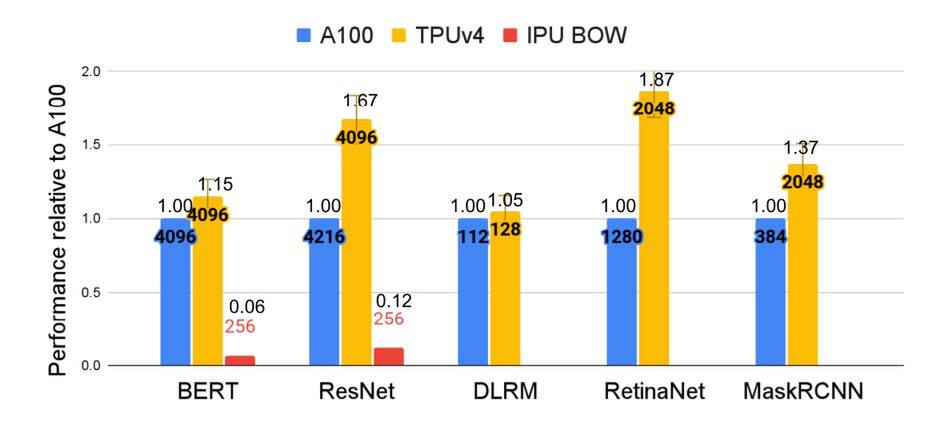
MLPerf Training 2.0での結果。GraphCoreのIPU BOWはBERTとResNetの結果しか登録していないとのこと。性能比には結構バラつきがあるが、とりあえずA100より遅い結果のものはない

消費電力。こちらは1枚のA100あるいは1個のTPU v4でBERTなりResNetを実施した場合の数字なので、上の結果とそのままリンクするわけではない
ちなみにもはやA100は最新製品ではなく、現行はH100だったりGH200だったりするわけだが、これに関してのGoogleの主張は、同じ7nmプロセスで製造した製品同士の比較であり、H100との比較はTPU v4の後継製品で行なうべき、というものである。
今年のGoogle I/OではTPU v5の話は特になかったことを考えると、登場するのは来年あたりだろうか? TPU v1が2015年、v2が2017年、v3が2018年、v4が2020年だったことを考えると、そろそろ出てきてもおかしくない時期である。さてH100をどの程度上回る性能になるだろうか?
(*1) 制御用に850nm帯のレーザーを使う関係で、ハーフミラーで分離しやすい1310nmを利用した、という可能性もなくはないが、だとすれば制御用を1310nmにして信号は850nmという選択肢もあったわけで、そちらではないということはやはり減衰がバカにならない可能性の方が高い。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります