



またしばらく間が空いてしまったがAIプロセッサーの話をしよう。今回はGoogle TPU v4である。Google TPUそのものはこのAIプロセッサシリーズの最初の回で説明した。この時にはGoogle TPU v1~v3までに触れたが、2021年のGoogle I/O 2021で後継となるGoogle TPU v4が発表された。この発表の概略は動画の2分11秒あたりから一瞬だけ紹介されている。
そのGoogle TPU v4は2021年後半から一般にも供用が開始されている。供用、というのはGoogle Cloud TPUサービスという形での提供と言う意味で、チップ自身の販売はなされていない。
そのGoogle TPU v4、発表時にも概略の説明はあったのだが、今年の4月にGoogle自身がそのGoogle TPU v4の詳細を公開した。こちらは論文も出ており、今年6月に開催されたISCA 2023で発表されている。というわけで、この詳細の説明や論文をベースにGoogle TPU v4(以下、TPU v4)について解説したい。
演算性能がTPU v3からほぼ3倍にアップしたTPU v4
TPU v4そのものはTPU v3の延長上にある。下の画像が論文に示されたTPU v3とTPU v4の比較であるが、製造プロセスがTSMCの16FF+からN7に変わり、動作周波数も微妙に向上(940MHz→1050MHz)、トランジスタ数も倍増している。
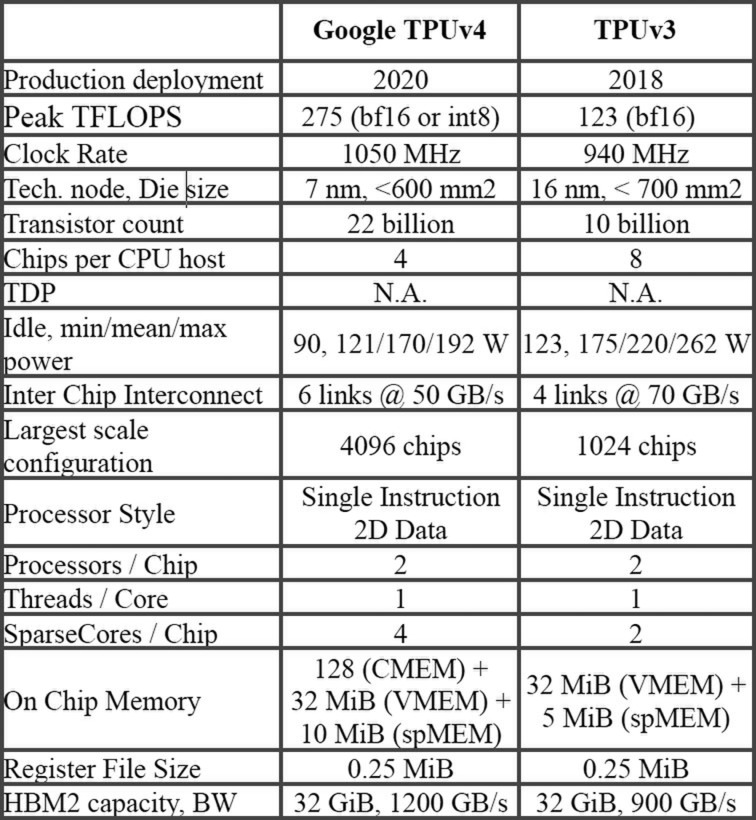
アイドルが90Wと高いのは、おそらく積極的なPowerGatingなどは施していないためだろう。使われ方を考えれば、x86のように「遊んでいるユニットを積極的にOffにする」という余地がないためとも考えられる
基本的なアーキテクチャーはTPU v1から変わっていないが、MXU(Matrix Multiply Unit)のサイズがTPU v1では256×256の64K/サイクルだったのに対し、TPU v2~v4では128×128の16K/サイクルに縮小され、ただしTPU v2とv3ではこれが2つ、TPU v4では4つ搭載される。
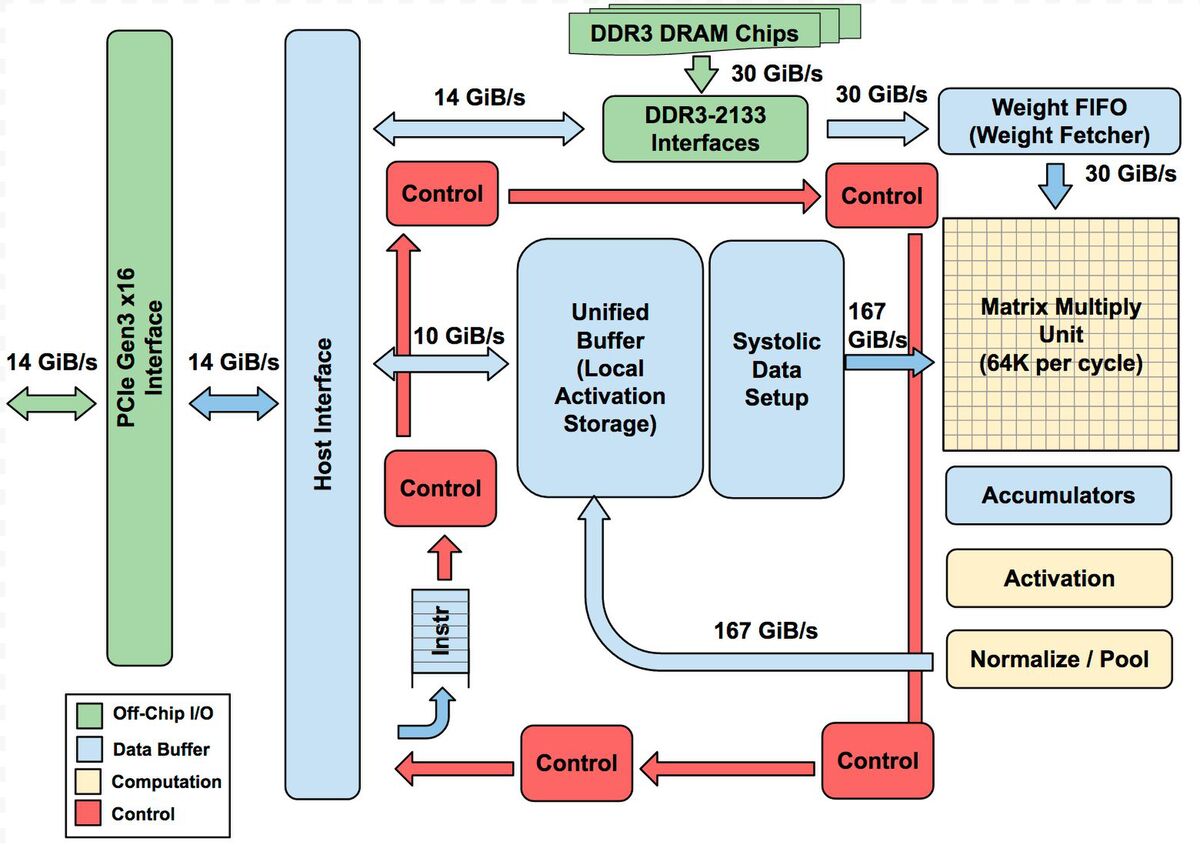
TPU v1のアーキテクチャー
ただし、v2以降ではTensor Core(つまりTPU v1の図全体)が1チップに2つずつ搭載されるので、MXU全体の規模としてはTPU v1~v3までは64K/サイクル、TPU v4では128K/サイクルになっている計算だ。
結果として演算性能はTPU v3のほぼ倍になる275TFlopsに引きあがっている。ちなみにTPU v3まではBF16のみのサポートだったが、TPU v4ではINT 8もサポートされている。もっともどの程度INT 8を使うのか? というのは微妙なところで、メインはBF16になりそうである。
なぜか? という話も論文に出ている。すでに2021年後半からTPU v4によるサービスがスタートしているわけだが、そのサービスでの学習ワークロードの90%以上がTPU上で行なわれている。2022年10月の時点で、そのワークロードの58%はTransformerモデルだった。このうち26%がBert、31%はLLM(Large Language Modelだった。
またTPU上で行なわれた学習の24%はレコメンデーションモデルだったとなっている。要するにTPU(v4だけでなくv3などもだろうが)の主要な用途は学習向けであって、推論処理よりは多少精度が必要になる。
特に学習の場合INTでは桁が足りないので、指数を利用できるFP16なりBF16でないとまずい(FP32の方がより良いだろうが、このあたりは精度と学習速度のバーターになるだろう)という話だ。今だとここにFP8を使ってどこまで精度を落とさずに済むかの検証をしているところだが、設計年度が2020年なのでまだFP8のサポートがないのは致し方ない。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります