



NEC、日本語性能が世界トップクラスの軽量LLMを開発 社内業務で活用開始
2023年07月07日 12時00分更新

NECは7月6日、パラメーター数を130億に抑え軽量にもかかわらず高性能な日本語能力を持つ大規模言語モデル(LLM)を開発したことを発表した。
オンプレミスでも動作可能
本モデルはNECが独自に収集・加工した多言語データを利用して開発した汎用的なモデル(ファウンデーションモデル)。2023年3月に稼働を開始した国内最大のAI研究用スーパーコンピューターを活用することによって、約1ヵ月という短期間で構築を実施した。

ベンチマークの結果
日本語の知識量や文書読解力を計測する自然言語処理分野で標準的なベンチマーク「JGLUE」で測定したところ、現時点で知識量に相当する質問応答で81.1%、推論能力に相当する文書読解においては84.3%と世界トップレベルの性能を達成している。
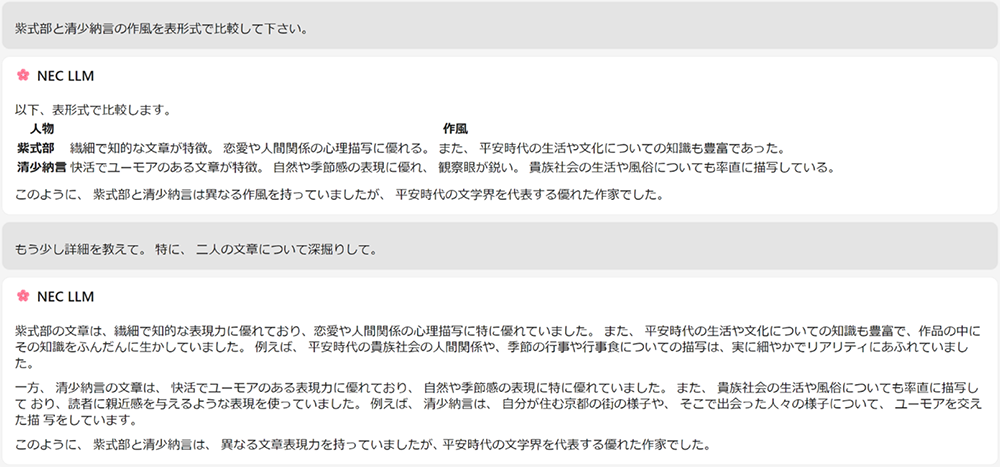
LLMの出力結果例(質問応答)
また、独自の工夫により高い性能にも関わらず本モデルは130億パラメーターと非常にコンパクト。GPU1枚搭載の標準的なサーバで動作可能だ。
これにより、LLMを組み込んだ業務アプリケーションを運用する際も、電力消費やサーバーコストを抑えられるだけではなく、オンプレミス環境でも動作可能なため、秘匿性の高い業務にも対応できる。
NECは本モデルをすでに社内業務で活用しており、文書作成や社内システム開発におけるソースコード作成業務など、様々な作業の効率化にも応用している。
今後はこのモデルを元に、ユーザーのクローズドデータを用いたLLMの開発を強力に推進していくという。
なお、7月4日には情報通信研究機構(NICT)が同じく日本語特化のLLMを発表している。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります