



グーグル、大規模言語モデル「PaLM 2」モバイル端末で動作する軽量モデルなど計4サイズを発表
2023年05月11日 16時25分更新

グーグルは5月11日、同社が主催する開発者会議「Google I/O 2023」において、AIチャットボット「Bard」などの基盤となる大規模言語モデル(LLM)の最新版「PaLM 2」を発表した。
PaLM 2には、「Gecko」「Otter」「Bison」「Unicorn」という 4 つのサイズが用意されており、特にGeckoは非常に軽量なため、モバイル端末でも動作し、オフラインの状態でも十分な速さでインタラクティブアプリケーションを構築できるという。
言葉のニュアンスを捉える

PaLM 2は複雑なタスクをシンプルなサブタスクに分解することができ、PaLMなどの従来のLLMよりも人間の言葉のニュアンスを理解することを得意とするため、なぞなぞや慣用句など、あいまいな意味や比喩的な表現を理解することができる。
また、数式を含む科学論文やウェブページなど広範なデータセットを使ってトレーニングされているため、ロジック、常識に基づく推論や数学に関する能力が向上しているという。
多言語対応能力が向上
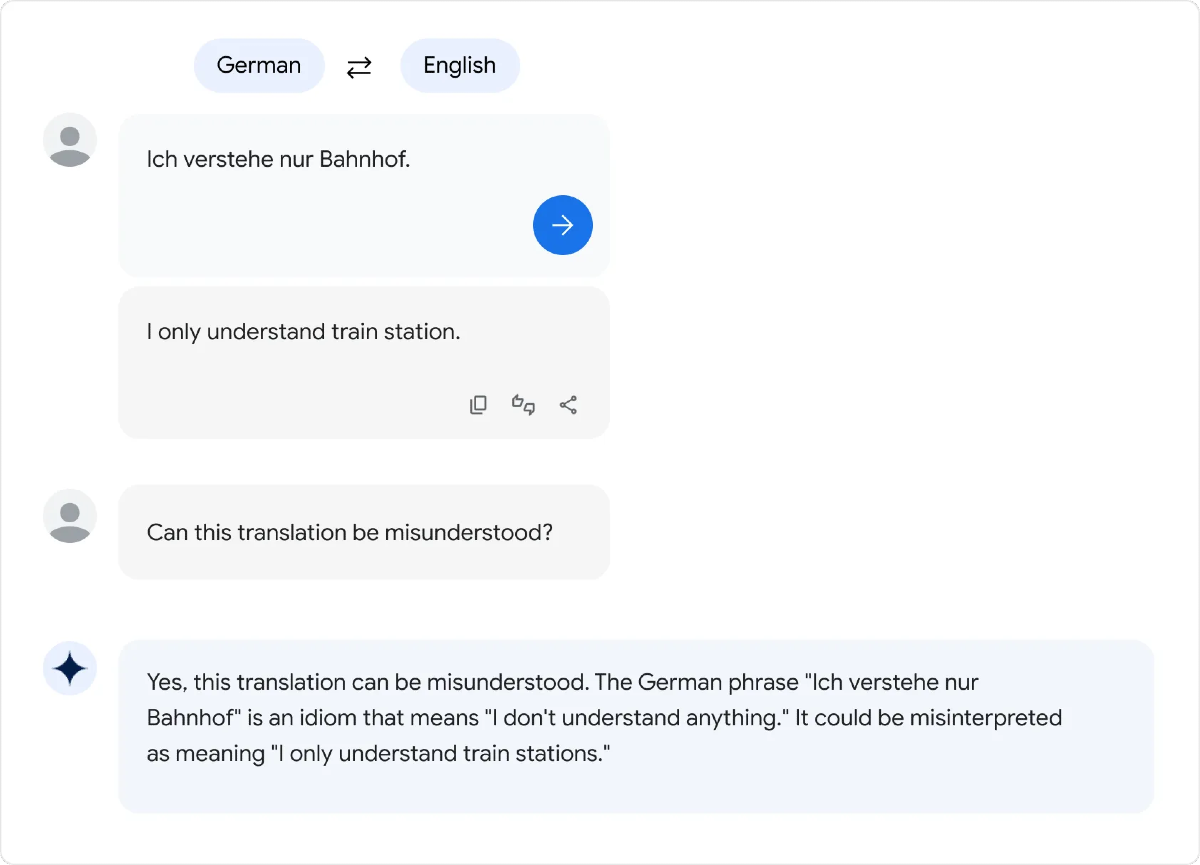
100以上の言語を含む多言語テキストでトレーニングされているため、上級レベルの言語能力試験で「習得」レベルに合格するなど、PaLMと比べて多言語タスクに優れているという。
コーディングも得意
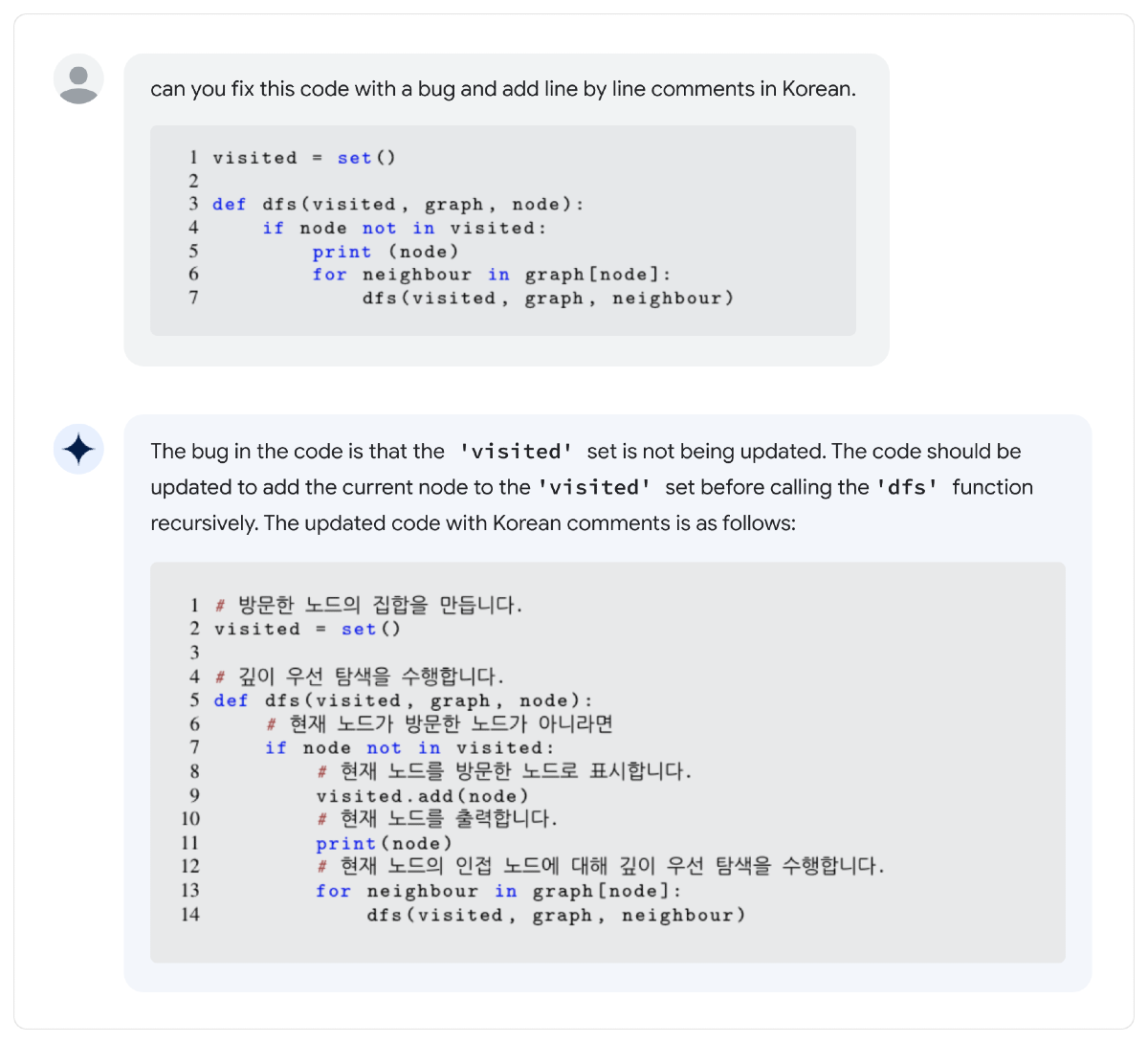
PaLM 2は、公開されている大量のウェブページやソースコードなどのデータセットで事前学習しているため、PythonやJavaScriptなどのメジャーなプログラミング言語だけでなく、Prolog、Fortran、Verilogといった比較的マイナーな言語でコードを生成することも可能になっている。また、言語間の翻訳もできるようだ。
PaLM 2を構築する3つのポイント
PaLM 2は、大規模言語モデルにおける3つの異なる研究成果を統合することで、前身であるPaLMを大幅に改良している。
ひとつは「計算最適化スケーリング」
モデルサイズとトレーニングデータセットサイズを互いに比例させスケールさせることによって、PaLM 2はPaLMよりもサイズが小さいにも関わらず、推論の高速化、パラメータの減少、コストの低減など、全体としてより優れた性能を発揮するようになっている。
次に「データセットミックスの改善」
これまでのLLMは、ほとんどが英語だけのテキストで構成されたデータセットで事前学習を行っていたが、PaLM 2はコーパスを改良し、数百の言語およびプログラミング言語、数式、科学論文、ウェブページなどから、より多言語かつ多様な事前学習用混合データセットを使用している。
そして「モデルのアーキテクチャと目標の更新」
PaLM 2は、アーキテクチャを改良し、多様なタスクで学習を行ったため、単にテキストを生成するだけではなく、様々な汎用的能力を獲得している。
各種ベンチマークでも好成績
PaLM 2は、WinoGrandeやBigBench-Hardなどの推論ベンチマークタスクにおいて、最先端の結果を達成している。また、従来の大規模言語モデルPaLMよりも大幅に多言語化されており、XSum、WikiLingua、XLSumなどのベンチマークでより良い結果を達成している。さらに、ポルトガル語や中国語などの言語において、PaLMやGoogle Translateよりも翻訳能力を向上させているという。
なお、Google I/Oでは「Google Workspace」との統合、医療情報のデータを使って学習した「Med-PaLM 2」、セキュリティユースケース向けにトレーニングされた「Sec-PaLM」など、PaLM 2を搭載した25以上の製品と新機能も発表されている。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります