



Dreamstudioにてベータ版を一般公開。API提供も開始
画像生成AI「Stable Diffusion」の上位モデル「XL」登場、より短い呪文で描写的なイメージを生成
2023年04月17日 09時00分更新

Stability AIは4月13日(現地時間)、同社が公開している画像生成AI「Stable Diffusion」の上位モデル「Stable Diffusion XL(以降、SDXL)」をリリースしたことを発表。同社のウェブサービス「DreamStudio」「ClipDrop」でベータ版を利用できるほか、APIの提供も開始。将来的には従来モデルと同様オープンソースで公開される。
パラメーター数は23億
SDXLのパラメーター数(与えられたデータから適切な出力を生成するために使用する。多いほど複雑なパターンや特徴を学習する能力が高くなる)は、従来モデル(Stable Diffusionバージョン2.1)の9億と比較して2.5倍も多い23億パラメーターとなっており、短いプロンプトでより詳細な画像や構図の生成が可能になるとしている。
また、テキストから画像を生成するだけでなく、画像の一部分だけを編集する「インペインティング」、画像の外側に画像を拡張する「アウトペインティング」、ひとつの画像からそのバリエーションを作成する「Image-to-image」などの機能も備える。
なお、同日にアマゾンから発表されたAWS上で生成AIを扱うクラウドサービス「Bedrock」では、Stability AIの「Stable Diffusion」が利用可能になっているが、SDXLもベータ版から本稼働になれば利用できるようになるだろう。
旧バージョンと比較してみる
Stable Diffusionのバージョンを選択
SDXLのベータ版が公開されているDreamStudioでは新旧のStable Diffusionを使って画像生成を試すことができる。
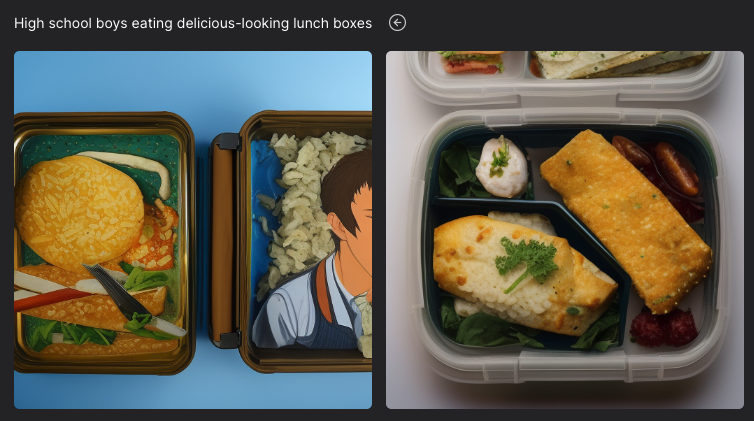
バージョン2.1
試しに「High school boys eating delicious-looking lunch boxes(美味しそうな弁当を食べている男子高校生)」というプロンプトをStable Diffusionバージョン2.1で試してみたものがこちら。いまひとつプロンプトが理解されていない。
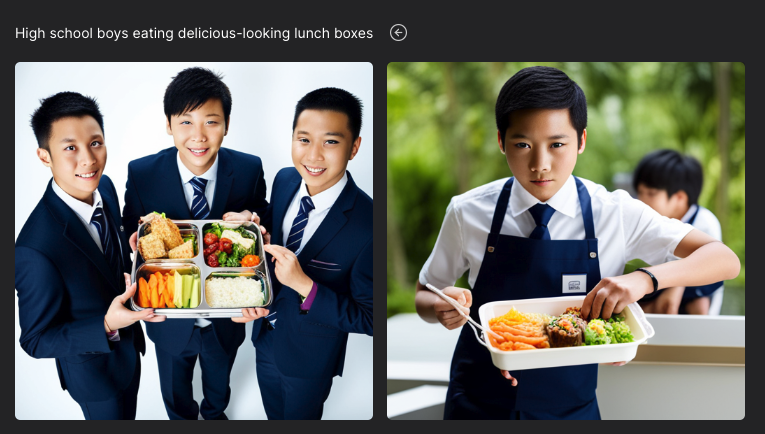
SDXL
同じプロンプトをSDXLで試してみたのがこちら。完璧にプロンプトの意図を理解しているように見える。

バージョン2.1
もう一点、「Beautiful japanese girl who is smiling and drinking water, wearing tank top, standing at japanese city(笑いながら水を飲む日本の美少女。タンクトップ、日本の街中)」というプロンプトをバージョン2.1で試したのがこちら。生成AIイラストでよく見かける漢字風のロゴが不自然だ。背景も日本には見えない。

SDXL
こちらがSDXLが描いたもの。これはかなり日本風の意匠を理解しているように思える。
SDXLモデルが一般公開されれば、Stable Diffusion Web UIを使ってローカルで動かすことも可能になるだろう。
他のモデルに比べて人物描画に関しては少し苦手という印象があったStable Diffusiionだが、今回のバージョンでかなり改善されたと感じた。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります