



レアゾン・ホールディングスは1月18日、世界最高レベルの高精度日本語音声認識モデルおよび世界最大1万9000時間の日本語音声コーパス「ReazonSpeech」を無償公開した。
音声コーパスとは音声データとテキストデータを発話単位で対応付けて集めたもの。深層学習で音声認識モデルを作成する材料として使用され、量と品質が音声認識の精度を大きく左右する。
「ReazonSpeech」の構成
ReazonSpeechは、OpenAI Whisperに匹敵する高精度な「ReazonSpeech音声認識モデル」、テレビの録画データなどから音声コーパスを自動抽出する「ReazonSpeechコーパス作成ツール」、世界最大1万9000時間の高品質な日本語音声認識モデル学習用コーパス「ReazonSpeech音声コーパス」の3つからなり、いずれも無償にて公開、商用利用も可能になっている。
世代を重ねて育てたコーパス
ReazonSpeechのコーパスは、ワンセグ放送の録画データから作成ツールを使って自動抽出している
通常、音声コーパスを構築するには音声と字幕テキストを対応付ける膨大なアライメント処理が必要になる。既存の音声認識モデルを利用すれば自動化できるが、その結果得られた音声コーパスは、元の音声認識モデルやその学習に用いた音声コーパスのライセンスの影響を受けてしまう。
そこでReazonSpeechは、最初に自由なライセンスで利用可能な「Mozilla Common Voice」という音声コーパスから構築した音声認識モデルでアラインメント処理を行い、そこで得られた音声コーパスを元にして再度アラインメント処理を実行する、という過程を幾世代も重ねることによって少しずつ音声コーパスのサイズを増やしたという。現在のサイズは1万9000時間だが、今後さらに規模を拡大する予定だ。
このような手順を経て作成した日本語コーパスを使い、音声処理のためのオープンソースツールキット「ESPnet」に学習させて構築したのが「ReazonSpeech音声認識モデル」だ。
OpenAI Whisperと同等の認識スコア
日本語音声認識デモ
ReazonSpeechのプロジェクトウェブサイトには、ReazonSpeech音声認識モデルを用いた文字起こしサービスのデモが用意されており、5秒ではあるが実際に試すことができる。いくつか短い文で試してみたが、いずれもほぼ意図通りに文字起こしが完成した。
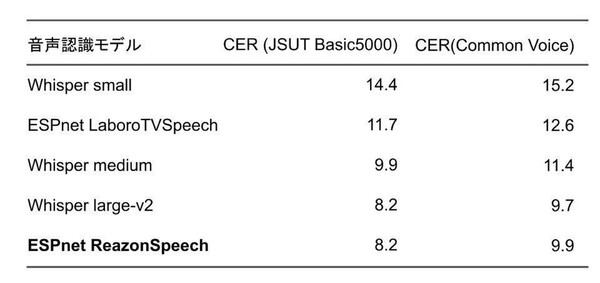
音声認識精度の比較
上記の表はReazonSpeech音声認識モデルと、他の主要な音声認識モデルであるOpenAI Whisper、LaboroTVSpeechとの精度比較結果だ。単位となるCER(Character Error Rate )の数値が低いほど認識精度が高い。
商用/非商用問わず自由に利用できる
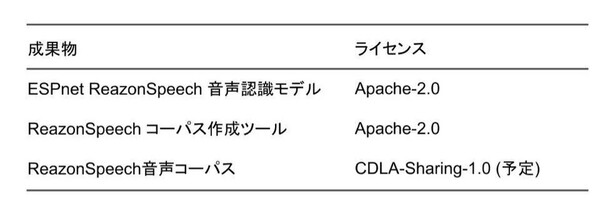
ReazonSpeechの音声認識モデルと音声コーパス作成ツールはApacheライセンス2.0にて公開されるので、商用・非商用を問わず自由に利用・改変・再配布可能。同様のコーパスの構築・共有活動に参加することもできる。
音声コーパスは、現著作権者の権利を侵害しないことを前提とするCDLA-Sharing-1.0ライセンスを予定している。このライセンスは、著作権法30条の4によって機械学習モデル構築のための使用に限り利用が認められている。
深層学習を用いた音声認識モデルの開発には、大規模な音声コーパスが必須となるが、これまで日本語で自由に利用可能なコーパスは量が少なく、日本語における音声認識技術の普及を妨げる大きな要因となっていた。無料かつ高品質なReazonSpeech日本語コーパスの登場は研究者にとって朗報となるだろう。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります