



グーグル、高クオリティかつ高速なテキスト画像生成モデル「Muse」を発表
2023年01月05日 15時00分更新
グーグルは1月2日、従来のモデルよりも大幅に効率的でありながら、最先端の画像生成性能をもつテキスト画像AI生成モデル「Muse」を発表した。

Museで生成された画像
競合モデルと同クオリティかつ超高速化
近年「Stable Diffusion」やOpenAIの「DALL-E 2」など、テキストから画像を生成するAIは驚くべき進化を見せている。グーグルもすでに「Imagen」と「Parti」という画像生成AIを発表しているが、「Muse」はそのどれとも異なる新しいモデルだ。

実際、1画像(512×512)あたりの生成時間はMuseが1.3秒となり、Stable Diffusion 1.4の3.7秒を明らかに上回っている。
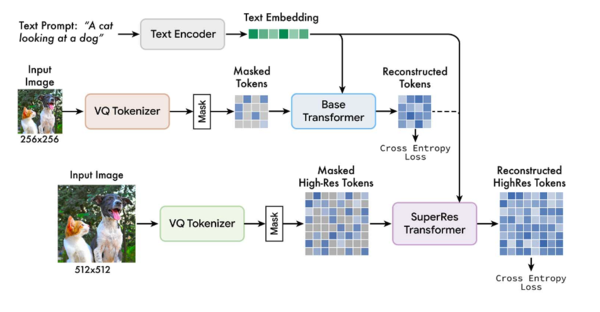
モデル概念図
高速化の理由としては、ImagenやDALL-E 2などの拡散(diffusion)モデルと違い、量子化された画像トークン(学習用画像のセット)を使用することでサンプリングの反復回数を減らしていることと、Partiなどの自己回帰(autoregressive)モデルにはない並列デコードで効率を高めているためとしている。
テキストだけで複数の物体をコントロール

テキスト「A croissant next to a latte with a flower latte art」
また、1から画像を生成するのではなく、あらかじめ用意した画像を編集することもできる。上記作例では「皿に置かれたケーキとカップに入ったカフェオレ」の写真を元画像として用意し、そこに「花のラテアートが描かれたカフェラテの隣にあるクロワッサン(A croissant next to a latte with a flower latte art.)」というテキストを入力することで、皿やカップはそのままにクロワッサンと花のラテアートの部分だけが編集されている。
マスクを使えば修正も書き足しも自由自在
さらに画像中の一部の要素だけを指定する「マスク」機能を使えば、マスク内だけを修正(Inpainting)したり、逆にマスク内はそのままに外側だけを書き足す(Outpainting)ことができる。

テキスト「Hot air balloons」
修正の例。上記の画像ではマットで指定された部分のお城がカットされ、代わりにテキストで指定された熱気球(Hot air balloons)が現れた。

テキスト「Beautiful fall foliage; the gazebo is on a lake」
書き足しの例。上記の画像ではマットで指定された建物はそのままに、周囲の背景がテキスト(Beautiful fall foliage)の指定通りに変更された。
今年は画像AIの実装が続くか?
現状グーグルはAIのデータセットにバイアスがかかる危険があるとして、一部(Imagenのみ米国限定でベータ版が利用可能)をのぞいて画像生成AIを公開していない。

「Image Creator」
一方、OpenAIに10億ドル出資しているマイクロソフトは、昨年10月に検索エンジン「Bing」に画像生成AI、DALL−E2を「Image Creator」としてすでに実装(日本では利用不可)しており、一部報道では「ChatGPT」を使った検索の強化も予定されているという。
もちろんAppleやAmazonといったライバル達もAI関連技術への莫大な投資を続けている。去年大きな注目を浴びた画像生成AI技術だが、このぶんだと今年はさらなる革命的な進化と実際のサービスへの実装例を多く見ることができそうだ。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります