



さらにPCに近い性能を持つスマホが登場する!? Arm「Cortex-A77」
2019年06月15日 12時00分更新
英Armは5月27日、次世代のハイエンドプロセッサとなる「Cortex-A77」を発表した。

Cortex-A77は「モバイルデバイスの性能を再定義する」という表現が用いられている。ちょっと過激だが、確かに性能が向上しており、高度な利用にも耐えるプロセッサになりつつある
Cortex-A77はARMv8.2アーキテクチャに準拠し、32bit命令(Thumb命令を含む)、64bit命令の実行が可能なプロセッサ。最大4MBのL3キャッシュ、256または512KBのコア単位のL2キャッシュ、64KBの命令、データ分離キャッシュを備え7nmプロセスでの製造をターゲットにしている。また、big.LITTLEアーキテクチャではbig側となり、Cortex-A55との組合せを想定している。
A77は、前世代であるA76に対して20%の性能向上を果たしたという。
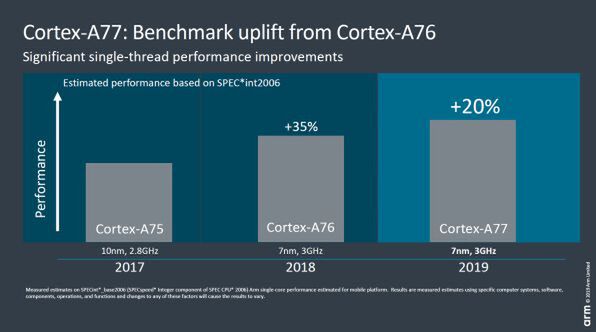
Cortex-A77は、前世代のA76に対して同一クロックで20%の性能向上を達成している
なのにダイサイズの増加は17%程度と、それほど大きくならずに済んでいる。Armが実施したベンチマークによれば、整数演算では20%程度だが、浮動小数点演算など最大35%の性能向上する場合もあるという。このほか、ベンチマークなどには現れないが、仮想マシン支援機能なども引き続き改良されている。
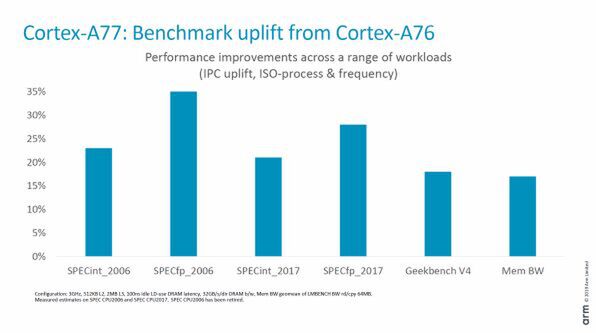
浮動小数点演算など他のベンチマークでも、20~35%程度の性能向上があるという
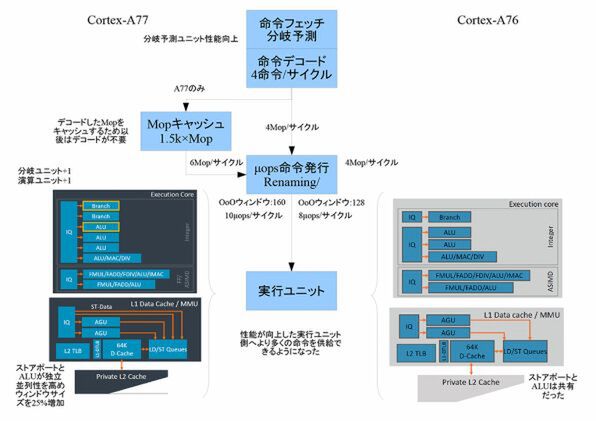
Cortex-A77は、アウトオブオーダー実行、スーパースケーラー構造のアプリケーションプロセッサーだ。Cortex-A76をベースに演算ユニットの増強やマクロ命令(Mop)キャッシュなどを追加した。簡単に言えば、A76に比べると、1サイクルにより多くの命令を演算ユニットに送り込むことができるようになった。これにより、大きな改良が見られない浮動小数点演算などでも、性能が向上している。では細かく内部を見ていくことにしよう。
Cortex-A77と前世代のCortex-A76を比較する
Cortex-A77は、アウトオブオーダー実行をするスーパースケーラー構造のCPUコアで、ARMv8の32bit、64bit命令をMop(Macro Operation)に変換する。Mopは「μop」(μoperation、マイクロ命令)を複数融合したFused μopからなる。命令は1度Mopに変換され、さらに発行時にμopに分解されて発行される。
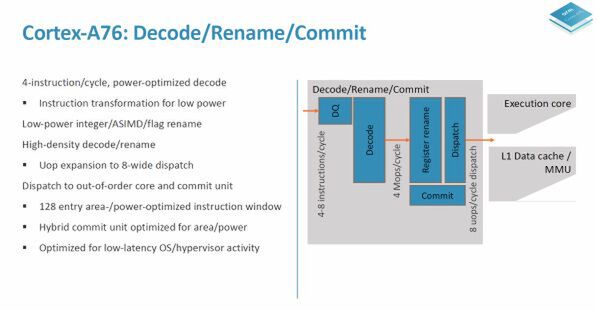
Cortex-A77の内部構造は、A76とよく似ている。
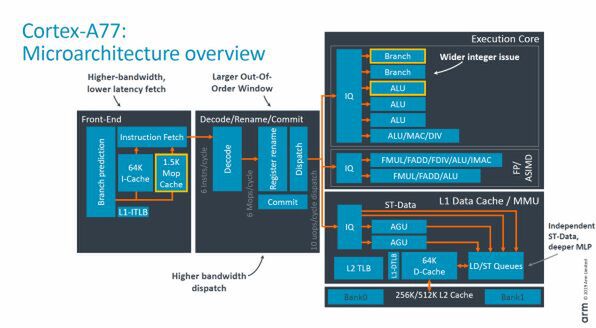
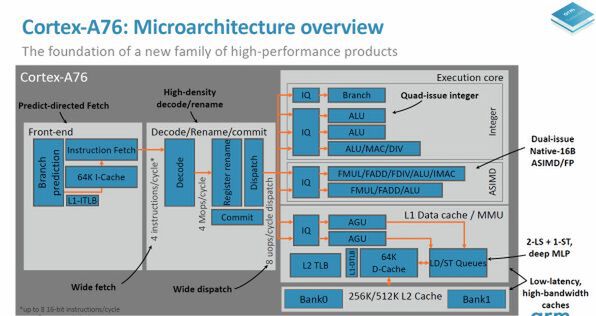
Cortex-A77とCortex-A76のCPUコアのブロック図はよく似ている。A77のブロック図で黄色い線で囲まれた部分が今回追加された部分
このブロック図での違いは、「フロントエンド」「演算ユニット」「ロードストア/データキャッシュ/MMUユニット」にある。演算ユニットでは、整数演算のALU(Arithmetic and Logic Unit、単純な整数/論理演算などを行なうユニット)が1つ追加された合計3つ。
これとは別に乗除算などの複雑な演算をするユニットが1つある(これはA76も同じ)。また、ブランチ命令を処理するBranchユニットが1つ追加された。これにより1サイクルに2つのブランチ処理をできるようになった。アウトオブオーダー実行では、分岐命令の処理は、性能に大きく影響を与える。なお、A77では、分岐命令の処理に使われる分岐予測ユニットの精度やバンド幅も向上している。
また、データの読み出し(ロード)、書き込み(ストア)をする部分も改良され、ストアデータとAGU(Address Generation Unit、アクセスするメモリアドレスを計算するALU)がポート共有せず独立したものになった。
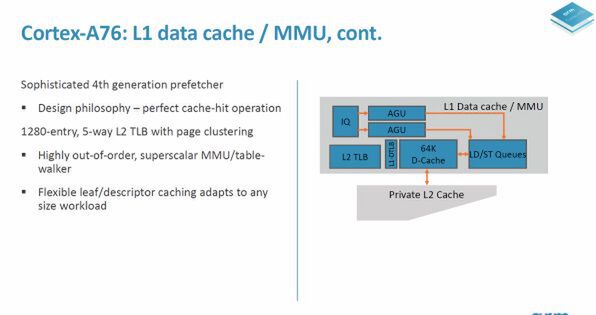

AGUとストアデータの経路が別になり、メモリアクセスの効率が高まった。また、メモリのプリフェッチなどの機能も強化されているという
A76では、2つのAGUと1つのストアデータの経路が共有になっており、1サイクルではどちらか一方の転送しかできなかった。これに対して、A77では、ストアデータのポートが2つ、ALUへのポートが2つ独立したものとなった。簡単にいうと、A77の演算ユニットは、1サイクルで同時に処理できる命令が増えている。
つまり、より高速な実行のためには、より多くの命令を演算ユニットに送り込む必要がある。そこでA77に追加されたのが「Mop」キャッシュである。
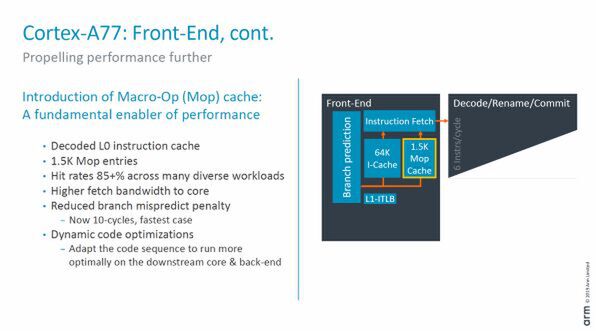
フロントエンド部分では、分岐予測ユニットの精度やバンド幅が向上、さらにMopキャッシュによりより多くの命令を送り込めるようになった
Mopは、ARM命令をデコーダーで変換したもので、後の処理がしやすいように分解整理された命令である。ただし、元のARM命令に対して、大きく増えすぎないように、いくつかのμopを融合して1つのMopにしてある。このようにすることで、デコーダーと命令発行ユニットの間の帯域を小さくできる。
A77は、このデコード済みのMopをキャッシュする。このため、Mopキャッシュにある命令を連続して実行している間は、デコーダーを休ませることができる。デコーダーは、CPUコアの中でも比較的規模の大きな回路で、これを休ませることができると消費電力で大きな違いが出る。このMopキャッシュからは、最大6Mopを1サイクルで命令発行部へ送ることができる。Armによれば、Mopキャッシュのヒット率は85%とし、多くのプログラムで、このMopキャッシュを使った実行ができるとしている。
さらに命令発行ユニット(Rename/Dispatch/Commit)は、最大10μopを1サイクルで発行できる。つまり、実行ユニットに1サイクルで最大10μopを送り込むことができるわけだ。
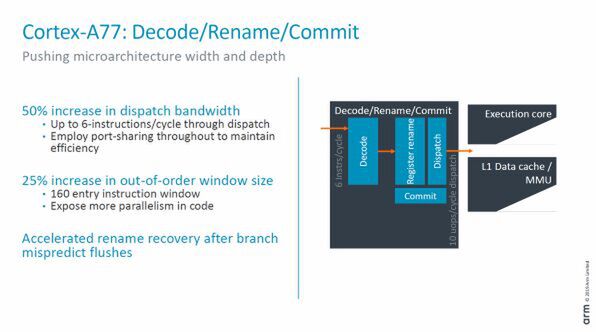
命令デコードと発行部は帯域が拡大し、Out-Of-Orderウィンドウサイズが拡大したため、A76に比べてより多くの命令を送り込める。実際には、このデコーダーの下にMopキャッシュがあり、デコード済みのMop命令を直接発行部に送る
これに対してA76では、8μop/サイクルで、同じサイクルで発行できるμop数は20%少なかった。また、Out-Of-Orderの対象となる範囲(ウィンドウ)が160エントリーにまで拡大されたため、プログラム中のより広範囲の命令に対してOut-Of-Order実行が可能になった。A76ではウィンドウサイズは128エントリーだった。
このあたりをまとめ直したのが、以下の図だ。
A77とA76のパイプラインを簡単にまとめ直してた。簡単に言えば、Mopキャッシュにより最大6Mopを1サイクルで命令発行部へ転送でき、ここから最大10命令を同時に実行ユニットに送り込めるようになった
大まかなパイプラインは、A76と変わらないが、デコーダーから下の部分が強化され、そこにMopキャッシュが設置された。1度デコードしたMopは、デコーダーを通さず、直接命令発行部へ渡る。命令発行部や実行ユニットが強化されているため、A77は、A76よりも1サイクルでより多くの命令を処理できるわけだ。
A77は、実際の製品が登場しておらず、コア構成やクロック周波数が定まらず、その実力は不明ではある。だが、モバイル用途では、Cortex-A76ですでにx86/64のSkylakeに近づいたという評価もある。単純な比較は難しいが、Skylakeではμopsキャッシュから1サイクルで最大6命令の読み出しが可能となっており、構造的にはほぼ同じスペックだ。
もちろん、デスクトップやサーバーも対象とするSkylakeマイクロアーキテクチャのほうが大きなパラメーターを持つ部分も多数ある。たとえば、Out-Of-Orderウィンドウは、224エントリーあり、A77よりも大きい。
全体に見ると、インテルとArmのマイクロアーキテクチャの性能に関係する各種パラメーターは近いものがあり、クロックあたりの性能は近づきつつある。また、Armも、サーバー向けプロセッサであるNeoverseというラインを抱えており、A77のマイクアーキテクチャがサーバー向けプロセッサのベースになる可能性も低くない。そう考えると、A77は相応の性能を持つプロセッサとして登場する可能性が高いと思われる。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります