



あの「Intel Movidius Myriad VPU」を採用!!
まだ知らないの!? UP square + AI Coreでディープラーニング推論を学べ!
2018年10月01日 11時00分更新
時間がかかる「学習」と、速度が要求される「推論」
深層学習の概略をザックリ紹介してきたが、具体的に深層学習とはどのようなものなのだろうか?
ニューラルネットワークを構成する人工ニューロンは、内部に設定されている関数とウェイト(重み)の値に従って複数の入力からひとつの出力を導く。そして人工ニューロン同士をつないだものがニューラルネットワークだ。
最もシンプルなニューラルネットワークは、入力層と出力層というふたつの層からなり、入力層にある種の入力を与えると、ある種の出力を行なう。たとえば手書き文字認識ならば、入力層に文字を描いた画像を与えると、出力層からその文字が何であるかを出力するという具合だ。
深層学習では、入力層と出力層の間に複数の層を入れ込んだネットワークを利用する。入力に対する出力を左右するのは、個々の人工ニューロンに記録されているウェイトの値による。たとえば、手書き文字認識なら文字の画像に対して正しい答えを出力するよう個々の人工ニューロンのウェイト値を調整する必要があるわけだ。
膨大な計算量と時間が必要な「学習」
しかし、膨大な人工ニューロンからなるネットワークのウェイト値を人の手で調整するのは不可能だ。この調整を自動化できたことが「深層学習」という名前の由来にもなっている。
つまり、「学習」を通じて個々の人工ニューロンのウェイト値を調節できるのである。手書き文字認識であれば、文字が描かれた画像をニューラルネットワークに与え続けて正しい出力が高い確率で得られるまで学習を続ける。これにより人工ニューロンのウェイト値が手書き文字認識として機能する値に収束していく。
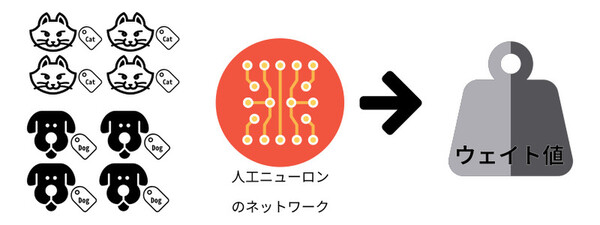
「学習」のイメージ。「学習」を通じて個々の人工ニューロンのウェイト値を調節できる
ニューラルネットワークの精度を上げるためには、ある程度の学習量を要し、膨大な計算量と時間が必要だ。ニューラルネットワークでは並列計算や行列計算が主体になることから、これらを高速に計算できるGPUを搭載したサーバーが学習に利用されることが多い。
処理速度が課題となる「推論」
そして実際の製品には、学習を終えた調整済みのニューラルネットワークを実装することになる。手書き文字認識であれば与えられた手書きの文字を「推論」し高確率で正しい答えを得られるニューラルネットワークを製品に組み込むわけである。
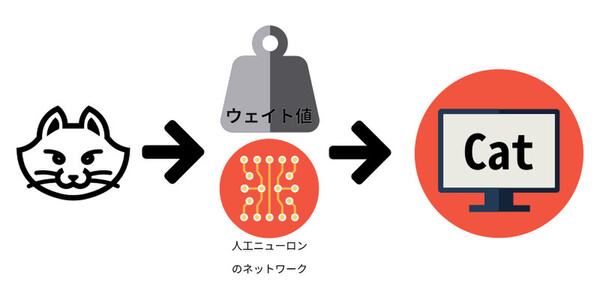
「推論」のイメージ。学習を終えた調整済みのニューラルネットワークに“推論”させる
推論の課題は処理速度だ。人間がインタラクティブに使うことを考えると、手書き文字の推論に1時間2時間といった時間がかかるのでは意味がない。せめて数秒、理想的に1秒未満で手書き文字を認識してほしいところだろう。
ロボットに組み込む障害物の認識といったような用途になると、速度に対する要求はさらに厳しくなる。カメラのフレームレートが60fpsならば1/60秒以内に認識を終えるような性能が望ましいはずだ。
「学習」と「推論」それぞれに特化する方向に進展
以上のように深層学習では、学習と推論というふたつの計算量が多い処理が必要になる。そのため現在では、ひとつの環境で学習・推論両方に対応するのではなく、それぞれに特化した環境も実現されてきている。例えば学習であれば速度向上、「推論」は低消費電力化と小型化といった具合だ。
「学習」では、GPU搭載サーバーで時間を短縮
学習は製品に組み込む前に行なう計算なので、時間的な制約は製品の開発期間や開発工程が許す範囲内ということになる。
もちろん、性能や精度を上げるためにトライ&エラーが必要になることが多いため、学習に1~2ヵ月間といった時間がかかるのは好ましいことではない。そのため、GPUを用いたサーバーを組み合わせ学習の時間を短縮する手法が一般的だ。
「推論」は、“アクセラレーター”を組み合わせ低消費電力化と小型化を実現
一方の推論は、学習に比べると物理的な制約が多い。たとえば、深層学習を組み込むIoT製品は物理的なサイズや消費電力、発熱が小さいことが求められるのが一般的だ。電源に関してはバッテリーで作動する必要があるケースも考えられる。
同時に、前述のように極めて短時間に推論を実行できる必要がある。小さいサイズ、低消費電力、低発熱という条件をクリアしつつ、製品として実用的な推論の速度を得るという難しい課題をクリアしなければならない。
この課題に対する回答のひとつが“アクセラレーター”の活用だ。
深層学習は、くり返し同じ計算が実行されるという特徴がある。従来型のCPUがあまり得意としないタイプの処理なので、CPUを用いて十分な速度を得ようとすると大きな消費電力やサイズが必要だ。
一方、深層学習とアクセラレーターとの相性はよく、深層学習専用のアクセラレーターと、小型低消費電力のCPUを用いることによって、低消費電力化と小型化が容易になる。
週刊アスキーの最新情報を購読しよう