



ARMの新GPU「Mali-G52」は、機械学習向けの機能を強化
2018年03月10日 10時00分更新
英ARMは、6日に中国・北京で発表会を開催。「Mali-G52」などGPUと、その関連製品4つを発表した。ここではその模様をレポートするとともに製品を解説する。
今回発表されたのはMaliシリーズのGPU2種、ビデオプロセッサー、ディスプレイプロセッサーの計4デバイス
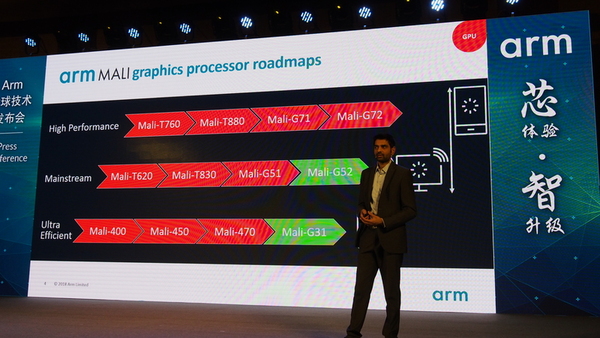
ARMのGPU、Maliシリーズの新コア発表
来年のスマホなどに搭載されるはず
なお、ご存じの方も多いだろうが、ARMはCPUやGPUの設計を販売し、実際の製品の製造はライセンスを受けた半導体メーカーが行なう。具体的なデバイスは、今後半導体メーカーが製品を作ることで市場に登場し、スマートフォンメーカーはそうして作られたSoCを自社製品に搭載する。このため、今回発表された製品が搭載された端末が登場するのは、早くても年末、おそらくは来年に発表されるものと思われる。
あらためて今回発表されたのは以下の4つのデバイスである。
・Mali-G52 GPU
・Mali-G31 GPU
・Mali-D51 ディスプレイプロセッサー
・Mali-V52 ビデオプロセッサー
発表会では、ARM社のマーケッティングプログラム担当シニアディレクター、Ian Smythe氏が登場、メインストリームクラスのスマートフォンの現状から説明を始めた。Maliシリーズは、2017年に12億個が出荷され、159社にライセンスが行なわれたという。スマートフォンのほぼ半数のシェアを持ち、デジタルテレビでは8割のシェアがあるという。
またGPUは、いわゆるAIと呼ばれる機械学習技術での利用が盛んで、スマートフォンでも物体認識や翻訳などさまざまに活用されている。また、VR/MR/ARといった仮想現実や強化現実、混合現実と呼ばれる分野でも高速なグラフィックスは必須であり、さらに4K動画や動画の上に重ねて表示される半透明のメニューといった高度なUIなど、CPUやGPUへの要求は年々さらに高くなってきている。
こうした状況に対して、昨年ARMは、マルチコア構成の柔軟性を高めるDynamicIQを発表した。これまで同一種のプロセッサコア最大4個に限られていたクラスタ(二次キャッシュを共有する単位)を拡張し、異なる種類のARMプロセッサコアを最大8つまで搭載することを可能にしたものだ。
これにより、高性能コアと高効率コアを組みあわせるbig.LITTLE構成も柔軟性が高まり、高効率コアのみの構成から、高性能コアを複数搭載する構成まで、SoCでの多様なコア構成が可能になった。そのなかで今回のGPUは、メインストリームのスマートフォンや低価格のスマートフォン(消費電力を小さくできると部品やバッテリなどのコストを下げられる)を想定したものだという。
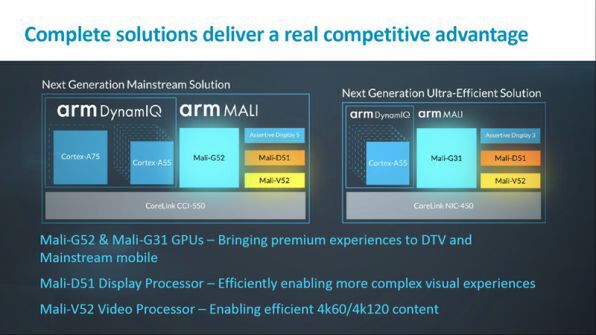
Mali-G52はメインストリームのスマートフォン向け、同G31は低コスト端末向け
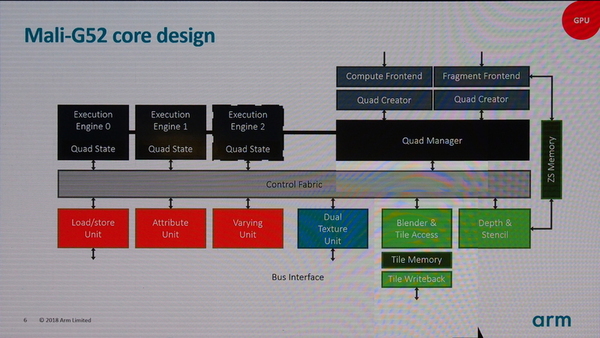
Mali-G52では、GPUコアが内蔵するExecution Engine自体が強化された。一方のMali-G31は、内部は従来のMali-G51を継承するが、ダイ上の面積を20%削減、単位面積あたりの性能を20%改善し、UI処理での性能を12%改善している。簡単に言えば、低コストな用途向けにより効率的に改良されたということだ。
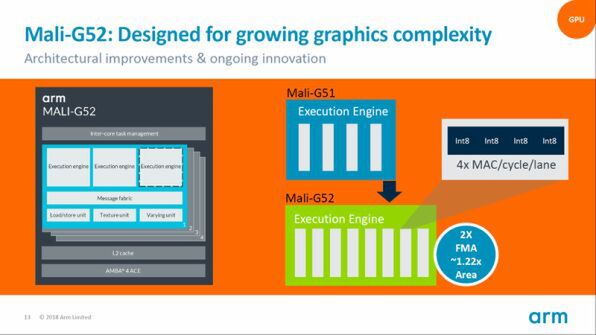
Mali-G52では、GPUコアに内蔵されるExecution Engineが強化され演算パイプラインが4から8に増えた

Mali-G31は、従来のMali-G51と同等の性能ながら、ダイ面積を抑えた
また、同時に発表されたディスプレイプロセッサーのMali-D51は、複数レイヤーの合成表示などを行ない、ソフトウェア側の負担を下げるもので、これによりプロセッサ性能があまり高くない場合でも高品質な表示が可能になる。
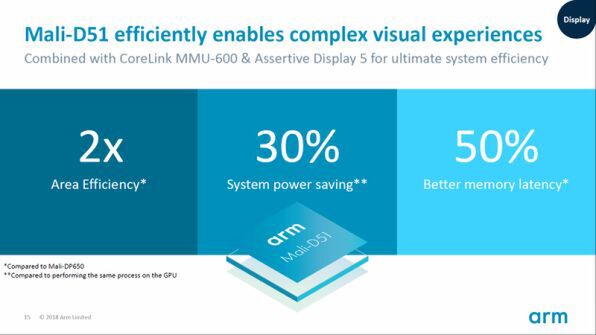
表示制御をするディスプレイプロセッサMali-D51は、前世代のMali-D650に比べて面積効率を上げ、消費電力を削減
ビデオプロセッサーのMali-V52は、動画エンコード/デコード専用プロセッサで、やはりソフトウェア処理の負担を下げ、バッテリ寿命(ソフトウェアで実行するよりも消費電力が下がる)を延長する。こうした機能は、汎用のGPUであれば、最初から組み込まれている例が多いが、ARMの場合には、それぞれを独立したモジュールとすることで、半導体メーカーが組み合わせを選択できるようになっている。
ビデオのエンコード/デコード用のビデオプロセッサMali-V52は、前世代のMali-V61と比較してデコードで2倍の性能を達成しながら、面積を38%削減している
ARMでは、今後、GPUの位置付けをはっきりさせるため、「70」、「50」、「30」というナンバーを使い、ハイエンド/メインストリーム/高効率(低コスト向け)に分類する。従来は、Mali-G51のコア数のバリエーション(MP1~MP6)で、低コストからメインストリームまでをカバーしていた。
今後、MaliシリーズのGPUは、ハイパフォーマンス(ハイエンド向け)のMali-G70シリーズ、メインストリーム向けのMali-G50シリーズ、低コスト向けのMali-G30シリーズと3クラスになる
機械学習向けの機能が加わったMali-G52 GPU
今回の発表の中心になるのは、新しいメインストーリーム向けGPUであるMali-G52だ。現在のMaliシリーズのGPUは、2016年に発表されたMali-G71から始まるBIFROST(バイフロスト)アーキテクチャを採用する。MaliシリーズのGPUには、これまでUTGARD、MIDGARDなどのアーキテクチャが採用されていた。
BIFROSTアーキテクチャは、グラフィックス描画の1スキャンライン分のデータを処理するスレッドを4つまとめた、「クワッド」同時処理する「Execution Engine」を最大3つ搭載するGPUコアを利用する。今回の改良は、そのExecution Engineに対するものだ。

Mali-G52のGPUコアは、最大で3つのExecution Engineを持つ
これまでのBIFROSTアーキテクチャは、Execution Engineに4つの演算パイプライン(レーン)があり、4スレッド(1クワッド)を並列処理することができた。しかし、Mali-G52は、レーンを8とし、8スレッド(2クワッド)を同時処理することができる。
G52のExecution Engineは同時8スレッドの並列処理が可能になった。さらに8bit整数の積和命令も追加され、4つの積和演算を各レーンで1サイクルで処理できるようになった
なおGPUでは、すべてのスレッドに対して同一の命令列(プログラム)を実行させるのが一般的。汎用CPUのSIMD(Single Instruction Multiple Data)と同じことだが、ARMでは、これをSIMT(Single Instruction Multiple Thread)と呼ぶ。グラフィックスであれば、こうした仕組みで描画に必要な演算をするのだが、最近では、汎用演算にGPUを使うことが増えており、Maliシリーズでも、スレッドに対する処理で、行列演算のような複雑な演算をする。
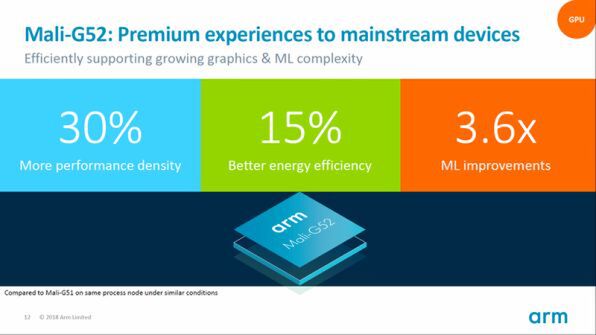
Mali-G52の演算パイプラインは、前世代のG51のものをベースに強化され、機械学習向けの機能が追加された。具体的には、8bit整数値(INT8)に対する演算処理命令で、各パイプラインあたり、4つの積和演算(乗算したあとに加算する計算で行列演算などで使われることが多い)を1サイクルで実行できるようになった。INT8形式のデータは、機械学習では、学習済みのニューラルネットワークによる推論を高速化する場合に使われる。ARMによれば、機械学習での性能向上は従来のMali-G51の3.6倍になるという。

機械学習でG52は、従来のG51の最大3.6倍の性能がありながら、単位面積あたりの性能は30%向上し、同性能ならば、G51よりもサイズを小さくできる
SoCでの組み込みを想定するMali GPUでは、実装面積(実際に半導体を作ったときにダイ上で占めるサイズ)も問題となる。アプリケーションプロセッサやキャッシュ、周辺回路などを一緒に1つのダイに乗せるSoCでは、GPUのサイズが大きくなると、SoCのコストが上昇してしまう。ARMでは、G52はG51と比較して、単位面積あたりの性能が30%向上したという。このため、G51と同等の性能をより小さい面積で実装できる。
また、多くのSoCのターゲットがスマートフォンなどのモバイルデバイスであることを考えると、省電力性も大きなポイントとなる。これに対して、Mali-G52はG51と比較して、同条件で15%改善されたという。
Mali-G52では、コア数1~4のバリエーションが可能で、コア数に応じてL2キャッシュは、64~512KBで構成可能だ。16ナノメータープロセスでは動作クロックは850MHz、ピクセルスループットは6.8ギガピクセル/秒秒となる。
Mali-G31は、基本的にはG51を継承する。G31のコアは、Execution Engineを1(シングルピクセルシェーダーコア。1MP)また2(デュアルピクセルシェーダーコア。2MP)持つ2種類があり、最大3コアの組合せでG51と同じく1MP~6MPを構成する。ただし、再設計により、ダイ上のサイズや単位面積あたりの性能が向上している。

Mali-G31のGPUコアは、G51と同等だが、単位面積あたりの性能が向上しており、同等性能ならばサイズを小さくできる
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります