



電王・Ponanza開発者が語る、プロの定跡を揺らした将棋プログラム発の新戦法“左美濃急戦”
2016年11月08日 10時00分更新
こんにちは、将棋プログラム「Ponanza」の作者、山本一成です。今回は将棋プログラムの「機械学習」に大きな変化をもたらしている“評価”についてをメインに話したいと思います。
将棋プログラムは大きく分けて、2つの部分から成り立っています。それは“探索”と“評価”です。“探索”とは、つまり“読むこと”で、将棋プログラムは1秒間に何百万もの局面を読めます。前回の並列化は、この“探索”の強化のお話でした。
そして、その読んだ局面の良し悪しを判断するのがもうひとつの部分、“評価”です。この“評価”が正しくできないとせっかくの“探索”が無駄になってしまうので、将棋プログラムにおいてこの“評価”作業はすごく重要なのです。
昔は年単位でかかっていた“評価”作業
将棋の局面をどのように評価すればいいか。
これは将棋プログラムにとって昔から重要なテーマでした。昔はそれこそ職人のように、開発者がひとつひとつ丁寧に評価のパラメーターをチューニングしていました。例えば、金は○点、銀は△点などの駒の価値、コマの位置関係、手番といった要素をひとつずつ手作業で調整していくのです。それゆえ、このチューニングは年単位の時間を要す、大変手間も時間もかかる作業でした。
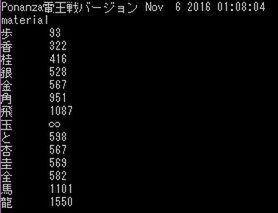
Ponanzaにおける駒の価値。飛車・角、馬・龍の価値が高めで、将棋をある程度やったことがある人の常識的な駒の価値とほぼ一致してると思います。
しかし、現在ではその評価のパラメーターに機械学習を用いるようになりました。具体的には、プロが指した局面を最も良い局面、それ以外の局面を悪い局面としてプログラムが自動的に学習するようになったのです。この進化でプログラムの作成時間は大幅に減りました。そして、そのノウハウの蓄積によって従来やっていた手作業の評価よりも強い将棋プログラムが開発できるようになりました。
また、近年はPonanzaを含む多くの将棋プログラムは、自分自身の探索結果から自分自身を強化し始めました。プロの指し手の模倣だけではなく、自分自身でしっかり読んで考えるようになったのです。良かった局面、あるいは思いのほか悪かった局面があった場合、それをフィードバックして自分自身を修正していくのです。
面白いことにこの自己学習の過程は人間の学習過程に似ています。最初は右も左もわからない中、先生から教えられた解法を学び、レベルが上がってくると自分自身でもっと良質な解法を考えていくようになるのです。「先生はこうしろって言ったけど、自分はこっちのほうがいいと思う」といった具合です。
プロの矢倉離れを引き起こした将棋プログラム発の新戦法
囲碁界の話をすると、Googleの「アルファ碁」が世界レベルのイ・セドル氏を破ったことは、多くの読者にとって記憶に新しいところでしょう。このアルファ碁も最初はプロ棋士同士の棋譜、あるいは非常に強いプレーヤー同士の棋譜から学習し、その後自分同士の対戦結果を利用して学習を進めていました。これによって今まで人間が見たこともないような局面、手筋を発見できるようになったのです。
プロの将棋界においてもまさに同じことが起こっており、今、新戦法の多くは将棋プログラム由来だと言われております。例えば、将棋プログラムが発見した戦法のひとつに“左美濃急戦”と呼ばれるものがあります。この発見によって、プロ棋士の十八番、“矢倉戦法”は急速に指されなくなってきているほど、強力な新戦法です。また、将棋プログラムが積極的に指す手で“48金と29飛の組み合わせ”や“飛車先を切らない”など、プロの世界では主流ではなかった戦法に光があたるようになりました。
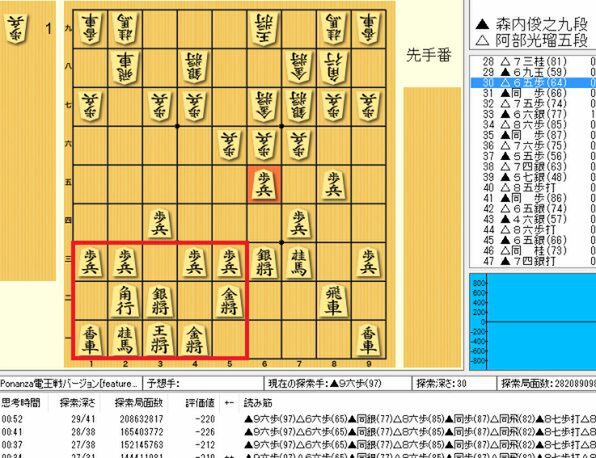
“左美濃急戦”。赤線で囲った部分が左美濃と呼ばれる部分です。棋譜は矢倉の大家森内九段に新人の阿部五段が左美濃急戦を使い圧勝したときのもの。
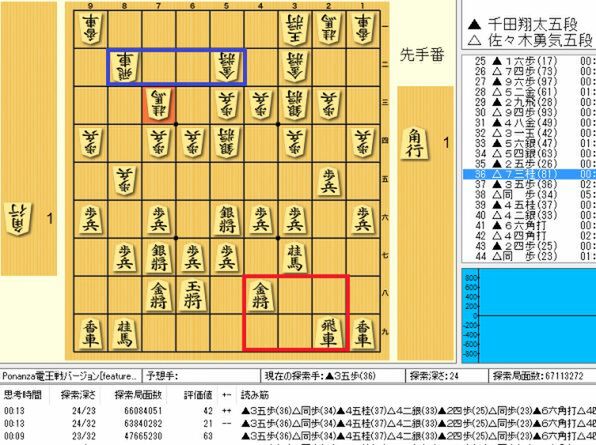
“48金と29飛の組み合わせ”(赤)。以前から存在していた形ではあるのですが、プロの世界の主流にはならなかった戦法でした。しかし、Ponanzaなどがこの形から積極的に攻める手を見せて以後、プロ棋界では流行しています。従来形(青)とどちらが主流派になるか、今プロ棋界で激闘が繰り広げられています。
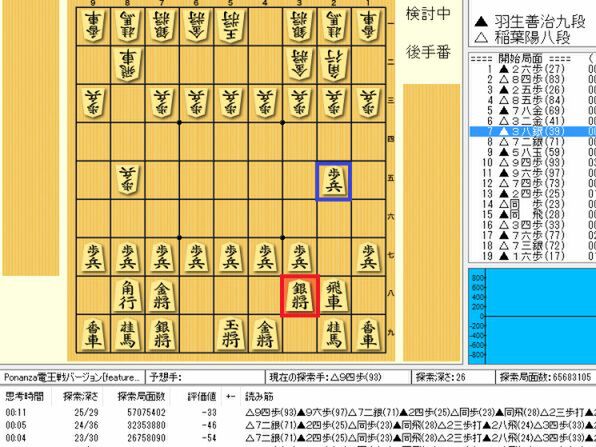
“飛車先を切らない”。将棋プログラムの新手というわけではありませんが、プロ棋界では「飛車先交換三つの得あり」と言われていました。しかし、将棋プログラムは飛車先の歩を交換することにあまり積極的ではないところを見て、プロ棋界でもさほど積極的に飛車先を交換したりせず(青)に、他の駒に手を回すこと(赤)が増えました。
そして面白いことに、多くの将棋プログラム開発者は自分たちのプログラムが新しい戦法を指していることにほとんど気がついておりませんでした。むしろ、熱心な将棋プログラムのフォロワー達によってそういった戦法が発見され、実際に使われるようになったのです。
2016年現在、多くの将棋プログラムはプロ棋士の手を教師にするのではなく、自分自身の探索結果から自分自身を改良していく方向性に舵を切っています。この方向性はおそらく今後覆ることがなく、いかにプログラムがプログラム自身を改良できるかが大事になっていくでしょう。
以前は“悪手”と判断されていたものでも“好手”となる可能性
そもそも、機械学習もそのコンセプト自体はもう何十年も前からあったものです。しかし、その当時はマシンのパワーが非力だったので昨今のような強いプロ棋士を負かすような強い将棋プログラムは生まれませんでした。現在の将棋プログラムが機械学習で十分な成果を上げたのはまぎれもなく、コンピューターの進化があったからです。
Ponanzaの場合は、イッペイさんの大紅蓮丸やさくらインターネットの200コアを超えるCPUを使ったコンピューターで機械学習しています。アルファ碁に至ってはそれを遥かに超える計算量のマシンを使用しています。この途方もない計算量を使って、初めて現実的に将棋や囲碁で機械学習ができるようになったのです。つまり、問題はコンセプトやアイディアではなく、それができるマシンパワーが揃ったのがごくごく最近ということです。
最後に自戒を込めたお話をしようと思います。今でこそ“ディープラーニング”という名前で定着していますが、ディープラーニングという手法は昔からあった“ニューラルネットワーク”とほぼ同じものです。ニューラルネットワークはすごく昔からある手法で、鳴り物入りで登場しました。
しかしその後、代替手法のほうが成果を上げることが増え、私がプログラミングを始めた8年ほどの前の時点では、ただ名前と理論がカッコイイだけの悪い手法という評価になっておりました。少なくとも私はそのように認識していましたし、同じように考えていた研究者は多かったと思います。つまり、当時は圧倒的に悪い“評価”がなされてました。
ですが現在、ディープラーニングと名前が代わり、大ブレイクしています。“評価”ががらりと変わったのです。この転換の原因は、長年下火にも関わらず頑張って研究を続けてきた方達がいたというのも大きな理由ですが、当時はマシンパワーが足らず非効率だったものが、コンピューターの進化で効率的になったからです。私自信も当時は悪い評価を下していたのに、今では必死でディープラーニングの勉強をしています。
つまり、今はナンセンスだと思われる技術や方法論でも、周辺技術の蓄積とマシンパワーの向上でうまくいくようになるかも知れないということです。今ダメなものでもずっとダメとは限らないということです。将棋プログラムが何年も当たり前だとされてきたプロの定跡を揺らしたように、機械学習の方法ももっと現在とは違う手法に注目が集まる日が来るかもしれません。そう考えると、私は現在の“評価”が絶対ではないと、肝に銘じておきたくなるのです。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります