



声で話しかけると、カレンダーにスケジュールを追加してくれたり、電話をかけてくれたり、最寄りの人気レストランを探してくれたりもするSiri。TVCMでは、クッキーモンスターが「Hey Siri!、タイマーを14分にセット」(手が汚れていても使えることをアピール)などとやっていますし、雑談でとんでもなく気の利いた受け答えをすることが話題になったりします。
Siriは、2011年、iPhone 4Sの登場とともにiOS 5に搭載されて以来、スマートフォンを一段と便利に魅力的にしてくれたと思います。また、iOS 10ではついに開発者向けに API が公開され(利用可能な機能はごくごく限定されていますが)Siriと連携したアプリの広がりも期待されています。
Siri以外にも、「OK Google」でおなじみのGoogle 音声検索・操作(Android、iOS、Web対応) や、NTTドコモの「しゃべってコンシェル」、マイクロソフトの「Cortana」、Yahoo! の「音声アシスト」など、音声で検索・操作できるサービスが次々始まっています。
前回の「LINEでメッセージが届けられるしくみ」に続き、今回は Siriの動きをのぞいてみることにしましょう。前回同様、Siri の全体像についての詳細は公開されていませんので、あくまで「ざっくりいえば」 「このように動いている」という、挙動から確認できるおおまかな推測であることをご承知おきください。
なお、Siri の元となったDARPA(国防高等研究計画局)の CALO プロジェクトの論文は「Design and Implementation of the CALO Query Manager 」(2006)で見ることができます。
話している相手はネットワーク越しのサーバー
まず基本的なこととして、Siriで話しかけているとき、スマホ単体で全ての返事をしてくれているわけではありません。

Siriは、スマホ単体で動いているのではない。
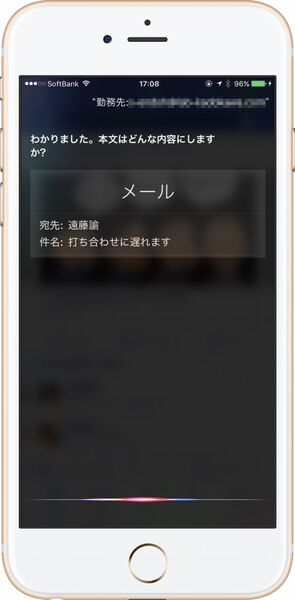
このことは、「機内モード」をオンにして、ネットワークを一切遮断した場合、Siriそのものが使えないことからも確認できます。
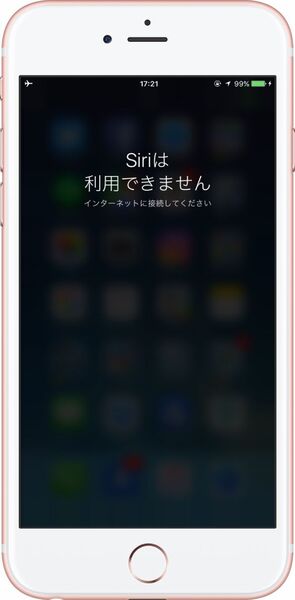
ネットワークにつながっていないと、Siriそのものが使えない。
つまり、Siri に話しかけている時には、ネットワークを経由して、外部のサービスに接続していることが分かります。相手をしてくれているのは、iPhoneそのものではなく、iPhoneを介したネットワークの先にあるAppleのサーバー、というわけです。
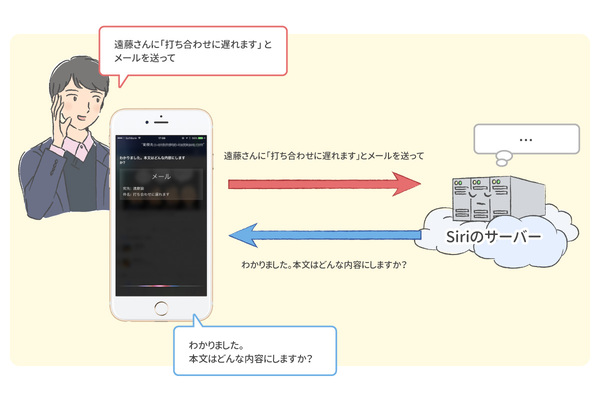
Siriは、ネットワーク経由で、サーバーにアクセスしている。
余談ですが、Wiresharkなどのネットワークパケット採取・解析ツールというものを使うと、接続先のサーバーが guzzoni.apple.comであることも分かります。
サーバーに送られているデータはなにか?
ここで、ひとつの疑問がわきます。SiriでiPhoneに向かって話しかけているとき、サーバーにはいったい何が伝えられているのでしょうか?
Siriは、iPhone以外では使えないようになっていますから、Siri起動直後のサーバーとの通信を開始したタイミングで、話しかけているiPhone固有の識別番号を送っていると考えられます。先ほどのWiresharkを使ってパケットを眺めてみると、確かにSiriを起動した直後に、Appleのサーバーと接続し、なにやらやりとりをしているように見えます(暗号化されているので、中身までみることはできません)。ともあれここで、端末認証を行い、Siriの使用開始に先立ってサーバーと接続認証を行なっていると思われます。
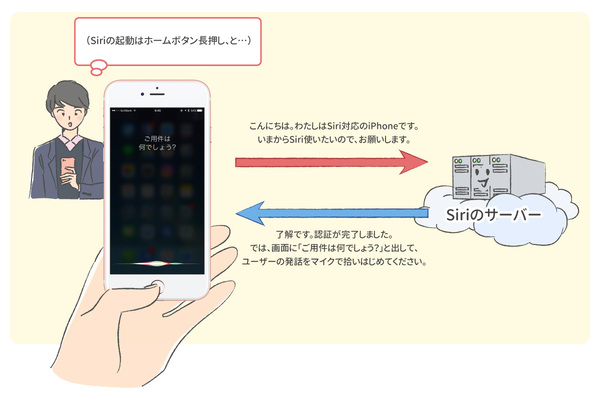
iPhoneはSiriのサーバーに接続認証を行い、接続が確立するとこの画面になる。
さて、次は、実際に話しかけるわけですが、この時にサーバーに送られているものはなんでしょうか。話かけた内容をiPhoneで文字列に変換したテキストデータでしょうか? それとも、話かけた音声データそのものでしょうか?
確かに、iPhoneのキーボードには、音声認識用のボタンがありますので、iPhoneでテキストデータに変換して、それをサーバーに送っていると考えることもできます。
ところが、「機内モード」にするなどして、ネットワークを一切利用不可な状態にすると、音声認識用ボタンはグレーアウトして使用不可になっていることが確認できます(実は、英語などごく一部の言語では、ネットワークがなくても音声認識による文字入力機能は利用可能です)。
ネットワークにつながっていないと、日本語音声認識そのものも使えない。
つまり、Siriを利用しているときには、iPhoneに話している音声そのものがサーバーに送られていることになります。そして、サーバー上で、送られてきた音声データが文字列データに変換され、iPhone に送り返され、その文字列が iPhone上に表示されているのです。
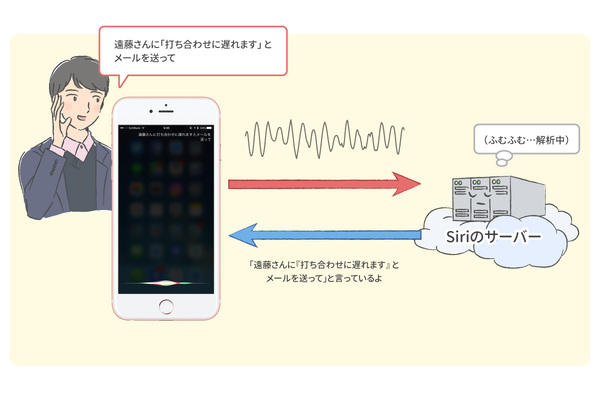
Siriに話かけると、音声データがサーバーに送られ、サーバー上で文字列に変換されている。
サーバーはどんな処理をしているか?(1)
では、サーバー上では、音声はどのように変換されていくのでしょうか? まず、音声としてのデータを、テキストとしてのデータに変換します。これは音声認識と呼ばれます。Siriでは、Nuance Communications社が持つ音声認識技術を使っていると言われています。
一般的に音声認識には、音響モデルと言語モデルというものが使われます。音響モデル は、音の波形データと、それらをテキストとして書き起こしたもの、その2つを大量に持っています。こういう波形だと 「あ」、こういう波形だと「い」というように覚えておいて、話かけた波形をもとに音素(ひらがなやアルファベット、発音記号など)に変換するために使います。どんな人のいろんな発声でも正しく認識するために、大量の音声データを使って、統計的に処理(こういう音声データの場合は、この音素の確率が高い、など)するための仕組みとなっています。
それに対して 言語モデル は、単語そのものを集めた辞書と、単語の並び方の知識を確率的に表現した辞書を持っています。これらを使って、音素の並びから最もありそうな文章となるよう、統計的に処理して(この音素の並びだと、この漢字やかなの並びになる確率が高い、など)文字列に変換するための仕組みです。
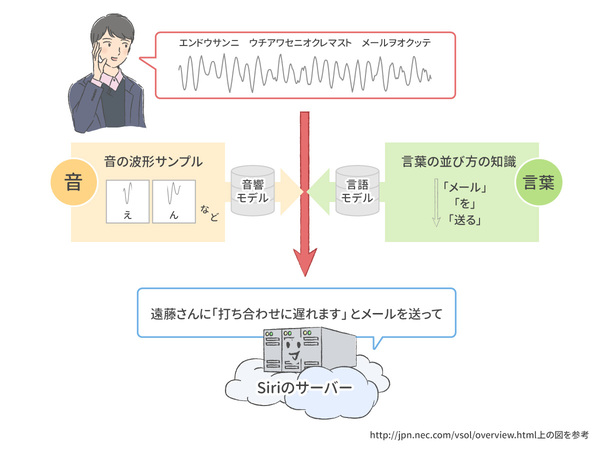
大量データを統計的に使って、音声データがテキストデータに変換される。
英語のような、単語や品詞の区切りがはっきりしている言語とは異なり、日本語は名詞や動詞、助詞などがひとつながりで表現されますので、辞書と統計的モデルを使って単語や品詞に分割していきます。これを形態素解析と言います。日本語用形態素解析で有名なのは「MeCab」ですが、iOSや macOSにも採用されているそうです。
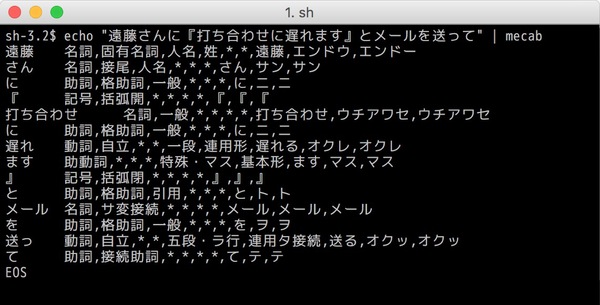
オープンソースソフトウェア「MeCab」で、実際に形態素解析を行った結果
なんだか不気味な(笑)出力ですが、ともあれ入力された文章が解析され、品詞単位に分割されているのが見てとれるとおもいます。
ここまでで、「 endōsanni uchiawaseniokuremasu to mēruwookutte」という発話内容が、「遠藤さんに、打ち合わせに遅れます、とメールを送って」という日本語文字列に変換されました。
少し難しそうな話が続きましたが、要するに、Siriのサーバー上でこれらの処理が高速に行われ、音声がテキスト文字列に瞬時に変換され、発話中にそのつどiPhoneに送られ、発話内容が表示されているわけです。話している最中に、つぎつぎと文章がそれっぽく変化していくのを眺めていると楽しいですが、その裏ではこんなことが行われているわけですね。
サーバーはどんな処理をしているか?(2)
さて、テキストデータにめでたく変換されたわけですが、もちろんここで終わりではありません。このあと、話かけた内容の意味を読み解く工程に入ります。主要な行程は構文解析と意味解析です。
構文解析とは、分割された品詞のそれぞれが、どのように関わりあっているか、を分析する処理です。日本語の場合は係り受け解析などとも呼ばれます。MeCab と同じく日本発の、係り受け解析器 「CaboCha」で、さきほどの文章を解析してみましょう。
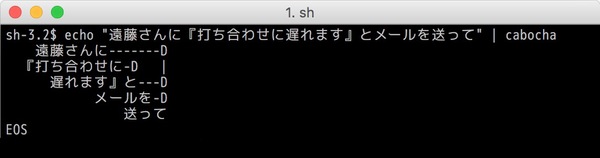
オープソンソースソフトウェア「CaboCha」で、実際に係り受け解析を行った結果。
ちょっと分かりにくいかもしれませんが、この出力が意味しているのは、こんな内容です。
遠藤さんに → 送って
打ちあわせに → 遅れます、と
打ちあわせに遅れます、と → 送って
メールを → 送って
このように、文章の論理的な構造を把握する処理が行われるわけです。この処理を行うことで、文章の意味をより正確に把握するのに役立ちます。
そして最後に意味解析が行われます。文章の意を読み解く処理、正確には、発話者(ユーザー)が、何をして欲しいか(そして iPhoneで何ができるか)の解析が行われます。現在の Siriではニューラルネットワークや機械学習の技術が使われているそうです。ここまでの処理に数秒とかからないというのは、本当にすごい技術ですね。
ところで、Siri などは AI(人工知能)の例として語られますが、本当に知能を持っているわけではありません(「知能とはなんぞや」という哲学的な議論はさておき)。ここまで行われてきたのは、確かにとても高度で高速な情報処理・統計的処理なのですが、そのあとは、Apple の開発者が用意した「アプリやOSを操作するパターン」のどれに最もあてはまるか、という処理になるのです。
- <<何年何月何日何時何分>> に、<<なんとかかんとか>> というスケジュールを追加(「カレンダー」アプリで)<<なんちゃらかんちゃら>> というアプリを開く
- <<あれそれ>> について調べる(Google 検索などを使って web 検索)
- <<現在地>> から <<目的地>> への経路を検索(「マップ」アプリで)
- :
- :
(などなど大量)
このように、意味解析の結果、Appleが用意している操作パターンのどれに合致するかの判断をしているわけなのです。アプリの操作ではなく、情報の検索を求めていると判断した場合には、Siriサーバーが適切な外部のサイト・サービスを使って回答を得る場合もあります。その多くは、質問応答システム「Wolfram|Alpha」にそのまま質問として投げられているようです。
そして、何かの命令や検索のどれにもあてはまらない場合は、雑談のようにユーモアたっぷりの受け答えをしてくれますが、「こう言われたらこう返事する」というルールの大量の積み重ねで構成されている会話エンジンへと割り振られます。人同士の雑談のように自在に会話をしてくれる(ような気にさせてくれる) Siri ですが、実はあの受け答えも同じようにあらかじめ無数のパターンが組み込まれていると思うと、なんだか不思議な気がしますね。「人工無脳」(文末のQ&A参照)という、おなじみの表現も思い出される方もいることでしょう。
サーバーから返ってくる情報はなにか?
さて、冒頭の例に戻りますと、ここまできたら、あとは「命令」に落とし込むだけです。今回の場合は、
- 宛先は遠藤さん
- メールのサブジェクトは「打ち合わせに遅れます」
- メールの本文は指定されていない
- その内容のメールを送る
- 送る際には(iPhone の)「メール」アプリを使う
という内容に落とし込まれます。これらの内容が、サーバーから iPhoneに送り返されてくる、というわけです。
iPhoneに登録されている連絡先から「遠藤さん」にあてはまりそうな内容を探しあて、宛先メールアドレスはそちらから取得します。今回の場合は、メール送信に必要な情報(宛先、サブジェクト、本文、使用アプリ)のうち、メールの本文のみが決定していない、と判断されました。
これを受けて「メール」アプリは、Siri を使ってメール本文の音声入力を促すようなプログラムがされています(本文が指定されていない時は本文を確認する、宛先が指定されていない時は宛先を確認する、など)。その結果、やっと「わかりました。本文はどんな内容にしますか?」というメッセージが画面に表示されるのです。
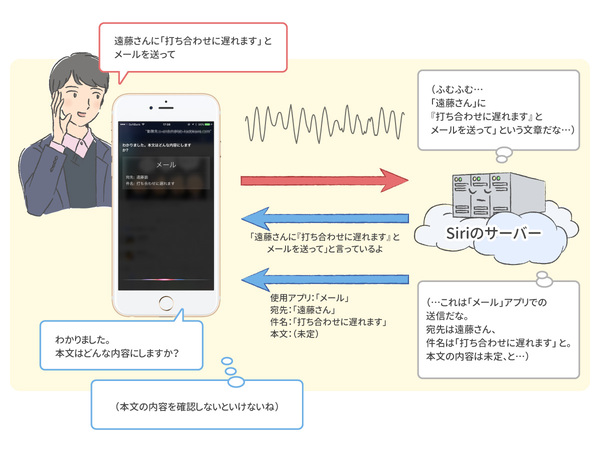
さまざまな処理を経て、「本文はどんな内容にしますか?」という状態に到達する。
同様に、iPhoneの連絡先に同じ苗字の遠藤さんが2人以上いる場合は、宛先も確定できないので、「どの遠藤さんですか?」と、選択を促してくれます。
高度な技術の組み合わせ、けど原理は意外とシンプル?
今回は Siri の動作原理の推測を行いながら、音声認識・自然言語処理について、本当に表面的ではありますが、ざっくりとみてきました。半世紀以上前から行われてきた自然言語処理の研究成果を巧みに組み合わせ、機械学習やニューラルネットワークなど最近の技術も最大限活用して効率化・精度向上をはかっている近年の音声対話システム。いちから自分でプログラムをつくりあげるのは大変ですが、こうやって過去現在のさまざまな技術や知見の集大成として、Siriなどがあると思うと、あの不思議な受け答えにも今までと違った感慨を覚えるかもしれません。
疑問をぶつけてみようQ&A
Q.説明の中で「人工無脳」という言葉が出てきました。それは、どんなものですか?
A.「人工無能」(または「人工無脳」)とは、英語では「chatterbot」と呼ばれます。「お話しボット」(「ボット」は「ロボット」の短縮形)という意味ですね。
これの元祖といわれるのが、1966年、ジョセフ・ワイゼンバウム氏によって作られた「ELIZA」というプログラムです。キーボードを使って人間と対話するように作られたプログラムですが、相手がコンピューターだと言われても真剣に対話する人が少なくなかったそうです。
ところが、実はこのプログラムは、人間が入力した文章からキーワードを抜き取り、あらかじめ決められたルールによって変換して返事を返しているだけだったのです。一見、人工知能のように見えますが「知能なんて持ってない」という意味で、日本語では「人工無能」と呼ばれるようになりました。
(ELIZA と同じプログラムを Emacs Lisp というプログラミング言語で書いたバージョンのソースコードはhttps://www.csee.umbc.edu/courses/471/papers/emacs-doctor.shtml で見ることができます。
JavaScript 版は http://www.masswerk.at/elizabot/ で試すことができます)。
その後、過去の会話内容から自動で学習していく機能なども備え、より自然に見える(しかし知能を持っているとはいいがたい)会話になっていきました。日本語のものでは
など開発されてきました。
最近ではマイクロソフトの女子高生AI「りんな」 も話題になりました。これは検索エンジン Bing、機械学習プラットフォーム、ビッグデータ解析などを組み合わせて実現されているものです。
その一方、人工無脳の「人間らしさとかより、メッセージで命令を受け付け処理してくれる会話ロボット」としての利用価値に注目が集まり、とくに今年に入って LINEボットやFacebook Messenger bot などを利用したサービスも気軽に作れる環境が整ってきました。エンジニアに人気のチャット Slack 向けにも Hubotというボット作成フレームワークがあります。
画面から入力項目を入れてアプリを操作するよりも、メッセンジャーの文字入力や音声入力のほうが、人々が気楽に使えるからのようです。
Web上には、驚くほどたくさんの参考例が転がっていますので、お手軽に自分なりの人工無脳的なボットを作ることが可能です。ぜひ楽しくチャレンジしてみてください。
筆者紹介――松林弘治(まつばやしこうじ)
1970年生まれ。大阪大学大学院基礎工学研究科博士後期課程中退。龍谷大学理工学部助手、レッドハットを経て、ヴァインカーブにてコンサルティング、カスタムシステムの開発・構築、オープンソースに関する研究開発、書籍・原稿の執筆などを行う。2014年からフリー。Vine Linuxの開発団体Project Vine副代表。ボランティアで写真アプリ「インスタグラム」の日本語化に貢献。2015年に「子どもを億万長者にしたければプログラミングの基礎を教えなさい」(KADOKAWA/メディアファクトリー)を出版。
週刊アスキーの最新情報を購読しよう
本記事はアフィリエイトプログラムによる収益を得ている場合があります