



省電力性能を高めたGPU設計

第4世代GCNアーキテクチャの強化点などを説明するマイク・マンター氏
Polarisファミリーは、それぞれGLOBAL FOUNDRIESの14nm FinFETプロセスで製造され、GPUアーキテクチャーも第4世代のGCN(Graphics Core Next)へと進化している。

GCNアーキテクチャの変遷
グラフィックスアーキテクチャー最大のポイントは、従来の28nmプロセスから半導体プロセスにして2世代分の微細化と、いわゆるインテルが言うところの3Dトランジスタ構造の採用によるリーク電流の低減と省電力化を活かし、消費電力あたりのパフォーマンスを大幅に引き上げたことにある。
Radeon RX 480に採用される“Polaris 10”チップは、わずか234mm2のダイサイズに、2304基のストリーミングプロセッサー(いわゆるRadeonコア)を統合。256bit GDDR5インターフェースを採用し、5TFLOPS以上の性能を150WのTDPで実現する。
| Radeon RX 400シリーズの基本仕様 | ||||||
|---|---|---|---|---|---|---|
| Radeon RX 480 | Radeon RX 470 | Radeon RX 460 | ||||
| 開発コードネーム | Polaris 10 | Polaris 11 | ||||
| GPUアーキテクチャー | 第4世代GCN | |||||
| 製造プロセス | GLOBAL FOUNDRIES 14nm FinFET | |||||
| ダイサイズ | 234mm2 | 124mm2 | ||||
| Compute Unite(CU)数 | 36 | 32 | 14 | |||
| ストリーミング プロセッサー数 |
2304基 | 2048基 | 896基 | |||
| 浮動小数点演算性能 | 5TFLOPS以上 | 4TFLOPS以上 | 2TFLOPS以上 | |||
| メモリーサイズ | 8GB/4GB | 4GB | 2GB | |||
| メモリーインターフェース | 256bit GDDR5 | 128bit GDDR5 | ||||
| 最大消費電力 | 150W | 110W | 75W | |||
| 補助電源コネクター | 6ピン×1 | ー | ||||
| HDMI | 2.0b | |||||
| Display Port | 1.3 HBR3 / 1.4 HDR対応 | |||||
| Radeon新旧製品仕様比較 | ||||||
|---|---|---|---|---|---|---|
| Radeon RX 480 | Radeon R9 380X | |||||
| 開発コードネーム | Polaris 10 XT | Tonga XT | ||||
| GPUアーキテクチャー | 第4世代GCN | 第3世代GCN | ||||
| 製造プロセス | 14nm FinFET | 28nm | ||||
| ダイサイズ | 234mm2 | 359mm2 | ||||
| Compute Unite(CU)数 | 36 | 32 | ||||
| ストリーミング プロセッサー数 |
2304基 | 2048基 | ||||
| ベースクロック | 1120MHz | 970MHz | ||||
| ブーストクロック | 1266MHz | ー | ||||
| メモリーサイズ | 8GB/4GB | 4GB | ||||
| メモリーインターフェース | 256bit GDDR5 | |||||
| メモリクロック(最大) | 8GHz相当(8Gbps) | 5.7GHz相当(5.7Gbps) | ||||
| 最大消費電力 | 150W | 190W | ||||
| 補助電源コネクター | 6ピン×1 | 6ピン×2 | ||||
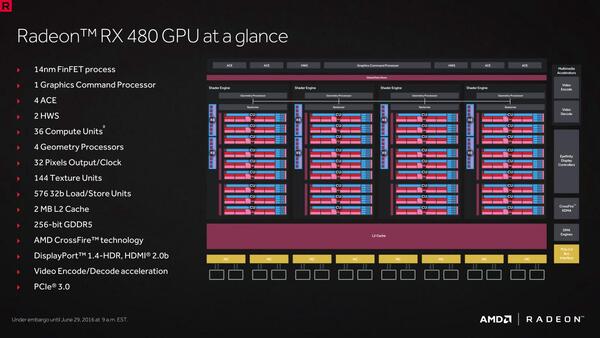
Radeon RX 480のブロックダイヤグラム

Radeon RX 460のブロックダイヤグラム
AMDのGCNアーキテクチャーは、16基の浮動小数点演算ストリーミングプロセッサーを16基束ねたSIMDアレイを4組と、整数演算スカラーユニット、4基のテクスチャーフィルタリングユニット、16基の16基のロード・ストア/テクスチャーフェッチ&フィルタリングユニットで、演算処理を行なう最小単位となるCompute Unit(CU)を構成。Radeon RX 480では、このCUを36基統合し、合計2304基のストリーミングプロセッサーを搭載する。
第4世代のGCNアーキテクチャーでは、L2キャッシュメモリーが従来の倍の2MBに拡張されるとともに、メモリーコントローラーも改良され、2:1、4:1、8:1のデルタカラー圧縮をサポートすることで、メモリー帯域をより有効に使えるようにしている。
また、ジオメトリーエンジンも改良され、描画する必要のないオブジェクトのトライアングル処理を、より積極的に省略することで、テッセレーション性能を向上させている。
それとともに、インデックスキャッシュを追加することで、小さなインスタンシングデータを格納し、ストリーミングエンジン内のデータ移動を最小限に抑えて、ジオメトリー処理の効率を高めている。
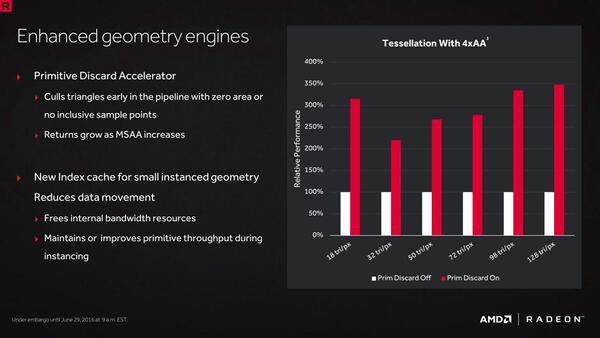
ジオメトリーエンジンの改良により、テッセレーション性能を向上

CUそのものの構成は変わらないが、SIMD処理あたりのパフォーマンスを最大15%向上させている

メモリー圧縮技術の改良により、メモリー帯域をより有効に活用できるようになり、256bitインターフェースでも十分な性能を発揮できるとされる

L2キャッシュは従来の倍に増量され、メモリーアクセスの軽減に役立っている

ハードウェアスケジューラーを2基搭載し、より動的なコンピューティング処理の切り換えなどが可能になる
AMDでは、14nm FinFETプロセスの性能を最大限引き出すべく、Polarisでは、より積極的なクロック制御を採用。低電圧で最大限の電流供給を実現することで、省電力でも高クロックで動作する。
このため、GPU内部にいくつか埋め込まれているセンサーの機能を拡張して、これまでの温度と電圧に加えて、動作クロックもモニタリングできるようにしている。
28nmプロセスから16nm FinFETプロセスの移行で、消費電力あたりのパフォーマンスを約15%向上させられるのに加え、GPUアーキテクチャーの改良とGPU設計の最適化によって、消費電力あたりのパフォーマンスを最大28%(Radeon RX 470とRadeon R9 270X比)もの向上を可能にしたと言う。

28nmプロセスから、22/20nm世代を飛ばして14nm FinFETへ移行を果たしたGCNアーキテクチャー。プロセス移行に5年を要した

14nm FinFETプロセスはリーク電流が抑えられ、パフォーマンス向上と省電力化を両立できるメリットがある


動的なクロック制御を施し、より低い電圧で、かつ高電流を加えることによって、高クロック動作を実現可能にする

積極的なクロック制御を可能にすべく、GPU内のセンサーに、温度、電圧に加えて、周波数もモニタリングできるように改良した

メモリインターフェースの改良とL2キャッシュの増量も、省電力化に大きく寄与すると言う

14nm FinFETプロセス技術への移行に加え、アーキテクチャ拡張やGPU設計の最適化によって、従来製品に比べて、最大2.8倍の消費電力あたりのパフォーマンスを実現する
週刊アスキーの最新情報を購読しよう